
Go基本数据类型——字符串
Go基本数据类型——字符串
前言
前面我们讲了Go的基本数据类型有:数值类型,包括整型、浮点类型和复数类型,在这里,我们来介绍下Go的字符串类型。
Go语言对字符串数据类型提供了原生支持。相比原生支持的字符串,非原生支持字符串类型会造成以下问题:
- 不是原生类型,编译器不会对字符串进行类型校验,造成类型安全性较差;
- 获取一个字符串长度代价开销大,通常需要遍历整个字符串,是O(n)的时间复杂度;
- 对中文之类的语言支持会出现问题;
以上这些问题都会对开发人员在使用字符串时造成一定的困扰,所以,Go语言在设计之初就决定了支持字符串类型。
在Go中,字符串的类型为string,Go通过string类型统一了对“字符串”的抽象。像字符串常量、字符串变量、字符串字面值,他们的类型都统一是string。
下面我们概括下Go原生支持字符串数据类型的好处:
- string数据类型不可变,提高了字符串并发安全(可以并发的被使用而不用担心出现不一致的情况)和存储利用率(无论它在哪使用,只需要分配一块空间去存储不可变量即可);
- 没有结尾的’\0’(C语言字符串以’\0’结尾),且获取字符串长度的时间复杂度是常数时间(Go对字符串进行了抽象,可以直接获取字符串长度),消除了字符串长度开销;
- “所见即所得”的原始字符串,降低构造多行字符串的负担;
- 对非ASCII字符提供原生支持,消除了源码在不同环境下显示乱码的可能;
原始字符串时通过一对反引号进行构造的字符串,原始字符串里的任何转义字符都不会起到转义作用,如下代码:
1 |
|
上面的代码输出即为所见。
Go字符串的组成
从字节视角上看字符串组成
Go语言中的字符串值是由一个可空的字节序列组成,字节序列中的字节数个数称为该字符串的长度。每个字节都是孤立的数据,不表意。
如下代码,我们对案例字符串进行打印输出每个字节以及字符串长度:
1 | var c_str = "吃饭" |
可以看到,仅从输出的字节看是无法与字符串中任一字符对应。
从字符视角上看字符串组成
从字符视角上看,字符串是可以表意的,即字符串是由一个可空的字符序列构成。
1 | var c_str = "吃饭" |
这里我们输出的是字符串中的字符数量,也输出了字符串中的每个字符,这里的字符采用的是Unicode的码点表示。
Unicode码点
Unicode 字符集中的每个字符,都被分配了统一且唯一的字符编号。所谓 Unicode 码点,就是指将 Unicode 字符集中的所有字符“排成一队”,字符在这个“队伍”中的位次,就是它在 Unicode 字符集中的码点。也就说,一个码点唯一对应一个字符。“码点”的概念和我们马上要讲的 rune 类型有很大关系。
rune 类型与字符字面值
Go 使用 rune 这个类型来表示一个 Unicode 码点。rune 本质上是 int32 类型的别名类型,它与 int32 类型是完全等价的,在 Go 源码中我们可以看到它的定义是这样的:
1 | // $GOROOT/src/builtin.go |
由于一个 Unicode 码点唯一对应一个 Unicode 字符。所以我们可以说,一个 rune 实例就是一个 Unicode 字符,一个 Go 字符串也可以被视为 rune 实例的集合。我们可以通过字符字面值来初始化一个 rune 变量。
在 Go 中,字符字面值有多种表示法,最常见的是通过单引号括起的字符字面值,比如:
1 | 'a' // ASCII字符 |
我们还可以使用 Unicode 专用的转义字符\u 或\U 作为前缀,来表示一个 Unicode 字符,比如:’
1 | '\u4e2d' // 字符:中 |
这里,我们要注意,\u 后面接两个十六进制数。如果是用两个十六进制数无法表示的 Unicode 字符,我们可以使用\U,\U 后面可以接四个十六进制数来表示一个 Unicode 字符。
而且,由于表示码点的 rune 本质上就是一个整型数,所以我们还可用整型值来直接作为字符字面值给 rune 变量赋值,比如下面代码:
1 | '\x27' // 使用十六进制表示的单引号字符 |
字符串字面值
字符串是字符的集合,了解了字符字面值后,字符串的字面值也就很简单了。只不过字符串是多个字符,所以我们需要把表示单个字符的单引号,换为表示多个字符组成的字符串的双引号就可以了。我们可以看下面这些例子:
1 | "abc\n" |
我们看到,将单个 Unicode 字符字面值一个接一个地连在一起,并用双引号包裹起来就构成了字符串字面值。甚至,我们也可以像倒数第二行那样,将不同字符字面值形式混合在一起,构成一个字符串字面值。
不过,这里你可能发现了一个问题,上面示例代码的最后一行使用的是十六进制形式的字符串字面值,但每个字节的值与前面几行的码点值完全对应不上啊,这是为什么呢?
这个字节序列实际上是“中国人”这个 Unicode 字符串的 UTF-8 编码值。什么是 UTF-8 编码?它又与 Unicode 字符集有什么关系呢?
UTF-8 编码方案
UTF-8 编码解决的是 Unicode 码点值在计算机中如何存储和表示(位模式)的问题。那你可能会说,码点唯一确定一个 Unicode 字符,直接用码点值不行么?
这的确是可以的,并且 UTF-32 编码标准就是采用的这个方案。UTF-32 编码方案固定使用 4 个字节表示每个 Unicode 字符码点,这带来的好处就是编解码简单,但缺点也很明显,主要有下面几点:
- 这种编码方案使用 4 个字节存储和传输一个整型数的时候,需要考虑不同平台的字节序问题 ;
- 由于采用 4 字节的固定长度编码,与采用 1 字节编码的 SCII 字符集无法兼容;
- 所有 Unicode 字符码点都用 4 字节编码,显然空间利用率很差。
针对这些问题,Go 语言之父 Rob Pike 发明了 UTF-8 编码方案。和 UTF-32 方案不同,UTF-8 方案使用变长度字节,对 Unicode 字符的码点进行编码。编码采用的字节数量与 Unicode 字符在码点表中的序号有关:表示序号(码点)小的字符使用的字节数量少,表示序号(码点)大的字符使用的字节数多。
UTF-8 编码使用的字节数量从 1 个到 4 个不等。前 128 个与 ASCII 字符重合的码点(U+0000~U+007F)使用 1 个字节表示;带变音符号的拉丁文、希腊文、西里尔字母、阿拉伯文等使用 2 个字节来表示;而东亚文字(包括汉字)使用 3 个字节表示;其他极少使用的语言的字符则使用 4 个字节表示。
这样的编码方案是兼容 ASCII 字符内存表示的,这意味着采用 UTF-8 方案在内存中表示 Unicode 字符时,已有的 ASCII 字符可以被直接当成 Unicode 字符进行存储和传输,不用再做任何改变。
此外,UTF-8 的编码单元为一个字节(也就是一次编解码一个字节),所以我们在处理 UTF-8 方案表示的 Unicode 字符的时候,就不需要像 UTF-32 方案那样考虑字节序问题了。相对于 UTF-32 方案,UTF-8 方案的空间利用率也是最高的。
现在,UTF-8 编码方案已经成为 Unicode 字符编码方案的事实标准,各个平台、浏览器等默认均使用 UTF-8 编码方案对 Unicode 字符进行编、解码。Go 语言也不例外,采用了 UTF-8 编码方案存储 Unicode 字符,我们在前面按字节输出一个字符串值时看到的字节序列,就是对字符进行 UTF-8 编码后的值。
那么现在我们就使用 Go 在标准库中提供的 UTF-8 包,对 Unicode 字符(rune)进行编解码试试看:
1 | // rune -> []byte |
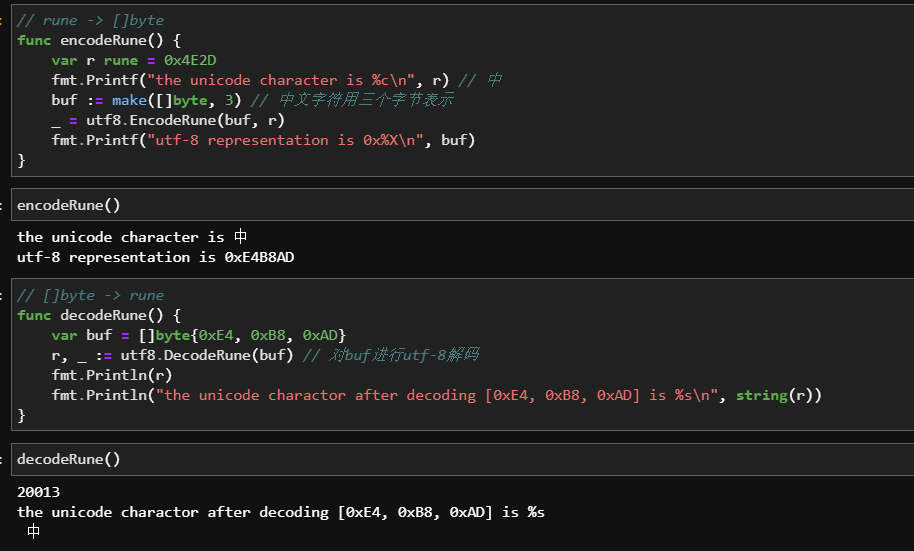
这段代码中,encodeRune 通过调用 UTF-8 的 EncodeRune 函数实现了对一个 rune,也就是一个 Unicode 字符的编码,decodeRun 则调用 UTF-8 包的 decodeRune,将一段内存字节转换回一个 Unicode 字符。
好了,现在我们已经搞清楚 Go 语言中字符串类型的性质和组成了。有了这些基础之后,我们就可以看看 Go 是如何实现字符串类型的。也就是说,在 Go 的编译器和运行时中,一个字符串变量究竟是如何表示的?
Go 字符串类型的内部表示
其实,我们前面提到的 Go 字符串类型的这些优秀的性质,Go 字符串在编译器和运行时中的内部表示是分不开的。Go 字符串类型的内部表示究竟是什么样的呢?在标准库的 reflect 包中,我们找到了答案,你可以看看下面代码:
1 | // $GOROOT/src/reflect/value.go |
我们可以看到,string 类型其实是一个“描述符”,它本身并不真正存储字符串数据,而仅是由一个指向底层存储的指针和字符串的长度字段组成的。我也画了一张图,直观地展示了一个 string 类型变量在 Go 内存中的存储:
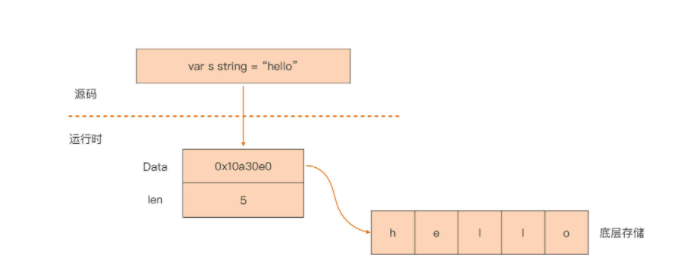
你看,Go 编译器把源码中的 string 类型映射为运行时的一个二元组(Data, Len),真实的字符串值数据就存储在一个被 Data 指向的底层数组中。通过 Data 字段,我们可以得到这个数组的内容,你可以看看下面这段代码:
1 | func dumpBytesArray(arr []byte) { |
这段代码利用了 unsafe.Pointer 的通用指针转型能力,按照 StringHeader 给出的结构内存布局,“顺藤摸瓜”,一步步找到了底层数组的地址,并输出了底层数组内容。
知道了 string 类型的实现原理后,我们再回头看看 Go 字符串类型性质中“获取长度的时间复杂度是常数时间”那句,是不是就很好理解了?之所以是常数时间,那是因为字符串类型中包含了字符串长度信息,当我们用 len 函数获取字符串长度时,len 函数只要简单地将这个信息提取出来就可以了。
了解了 string 类型的实现原理后,我们还可以得到这样一个结论,那就是我们直接将 string 类型通过函数 / 方法参数传入也不会带来太多的开销。因为传入的仅仅是一个“描述符”,而不是真正的字符串数据。
那么,了解了 Go 字符串的一些基本信息和原理后,我们从理论转向实际,看看日常开发中围绕字符串类型都有哪些常见操作。Go 字符串类型的常见操作
Go 字符串类型的常见操作
由于字符串的不可变性,针对字符串,我们更多是尝试对其进行读取,或者将它作为一个组成单元去构建其他字符串,又或是转换为其他类型。下面我们逐一来看一下这些字符串操作:
第一个操作:下标操作
在字符串的实现中,真正存储数据的是底层的数组。字符串的下标操作本质上等价于底层数组的下标操作。我们在前面的代码中实际碰到过针对字符串的下标操作,形式是这样的:
1 | var s = "中国人" |
我们可以看到,通过下标操作,我们获取的是字符串中特定下标上的字节,而不是字符。
第二个操作:字符迭代
Go 有两种迭代形式:常规 for 迭代与 for range 迭代。你要注意,通过这两种形式的迭代对字符串进行操作得到的结果是不同的。
通过常规 for 迭代对字符串进行的操作是一种字节视角的迭代,每轮迭代得到的的结果都是组成字符串内容的一个字节,以及该字节所在的下标值,这也等价于对字符串底层数组的迭代,比如下面代码:
1 | var s = "中国人" |
运行这段代码,我们会看到,经过常规 for 迭代后,我们获取到的是字符串里字符的 UTF-8 编码中的一个字节:
1 | index: 0, value: 0xe4 |
而像下面这样使用 for range 迭代,我们得到的又是什么呢?我们继续看代码:
1 | var s = "中国人" |
同样运行一下这段代码,我们得到:
1 | index: 0, value: 0x4e2d |
我们看到,通过 for range 迭代,我们每轮迭代得到的是字符串中 Unicode 字符的码点值,以及该字符在字符串中的偏移值。我们可以通过这样的迭代,获取字符串中的字符个数,而通过 Go 提供的内置函数 len,我们只能获取字符串内容的长度(字节个数)。当然了,获取字符串中字符个数更专业的方法,是调用标准库 UTF-8 包中的 RuneCountInString 函数,这点你可以自己试一下。
第三个操作:字符串连接
我们前面已经知道,字符串内容是不可变的,但这并不妨碍我们基于已有字符串创建新字符串。Go 原生支持通过 +/+= 操作符进行字符串连接,这也是对开发者体验最好的字符串连接操作,你可以看看下面这段代码:
1 | s := "Rob Pike, " |
不过,虽然通过 +/+= 进行字符串连接的开发体验是最好的,但连接性能就未必是最快的了。出了这个方法外,Go 还提供了 strings.Builder、strings.Join、fmt.Sprintf 等函数来进行字符串连接操作。
第四个操作:字符串比较
Go 字符串类型支持各种比较关系操作符,包括 = =、!= 、>=、<=、> 和 <。在字符串的比较上,Go 采用字典序的比较策略,分别从每个字符串的起始处,开始逐个字节地对两个字符串类型变量进行比较。
当两个字符串之间出现了第一个不相同的元素,比较就结束了,这两个元素的比较结果就会做为串最终的比较结果。如果出现两个字符串长度不同的情况,长度比较小的字符串会用空元素补齐,空元素比其他非空元素都小。
这里我给了一个 Go 字符串比较的示例:
1 | func main() { |
你可以看到,鉴于 Go string 类型是不可变的,所以说如果两个字符串的长度不相同,那么我们不需要比较具体字符串数据,也可以断定两个字符串是不同的。但是如果两个字符串长度相同,就要进一步判断,数据指针是否指向同一块底层存储数据。如果还相同,那么我们可以说两个字符串是等价的,如果不同,那就还需要进一步去比对实际的数据内容。
第五个操作:字符串转换
在这方面,Go 支持字符串与字节切片、字符串与 rune 切片的双向转换,并且这种转换无需调用任何函数,只需使用显式类型转换就可以了。我们看看下面代码:
1 | var s string = "中国人" |
这样的转型看似简单,但无论是 string 转切片,还是切片转 string,这类转型背后也是有着一定开销的。这些开销的根源就在于 string 是不可变的,运行时要为转换后的类型分配新内。





