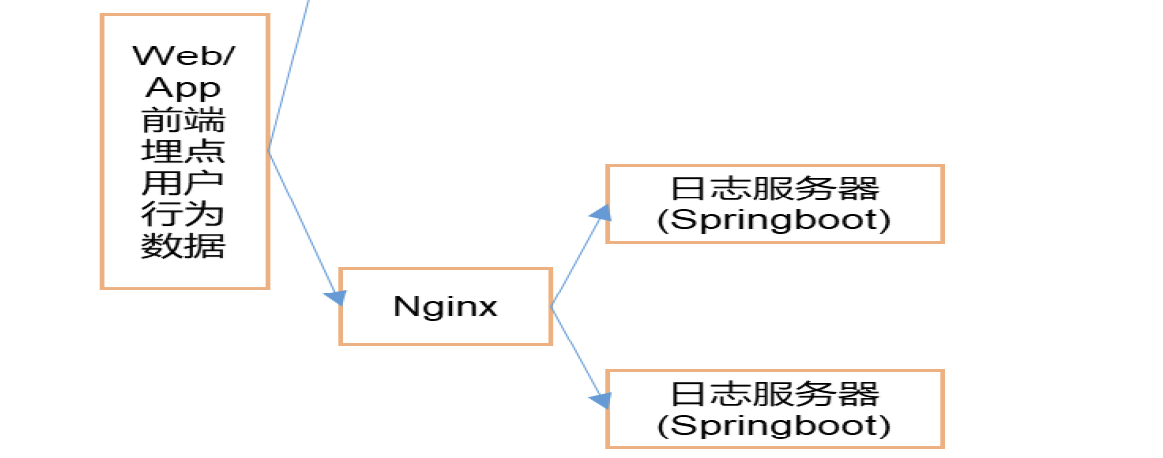
实时数仓之数据采集 日志数据采集 模拟日志生成器使用 对于日志数据,我们采用写好的一个模拟生成日志数据的jar包,运行jar包可以将日志发送给服务器上某一个指定的端口,需要我们大数据程序员从指定端口接收数据并对数据进行处理。
前端埋点数据通过nginx做负载均衡转发给日志服务器。这里我们首先通过编写soringboot代码模拟后台在本地做测试,之后再将项目打成jar包上传服务器测试,之后再搭建nginx测试测试负载均衡。
模拟web app前端埋点生成数据 1 2 3 4 5 6 7 (base) [dw@hadoop116 module]$ mkdir gmall-flink (base) [dw@hadoop116 module]$ cd gmall-flink/ (base) [dw@hadoop116 gmall-flink]$ ls (base) [dw@hadoop116 gmall-flink]$ mkdir rt_applog (base) [dw@hadoop116 rt_applog]$ ls application.yml gmall2020-mock-log-2020-12-18.jar
测试jar包:
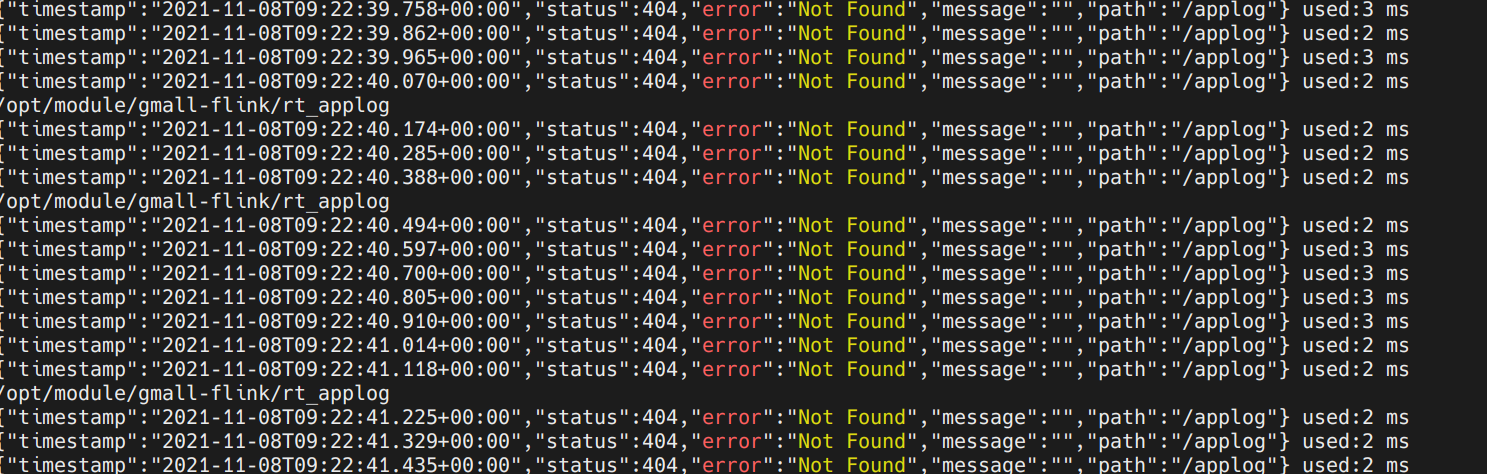
这里要注意,8080端口未监听,如果你启动zk,zk默认是8080端口,虽然这样有监听,但是会报错404,无响应。
1 2 3 (base) [dw@hadoop116 rt_applog]$ java -jar gmall2020-mock-log-2020-12-18.jar java.net.ConnectException: Failed to connect to localhost/0:0:0:0:0:0:0:1%1:8080
日志采集模块-本地测试 SpringBoot简介 (大数据程序员,要会写数据接口。给你一个请求,我要什么东西,一个json格式,去访问数据库,最后把数据加工成要的json格式返回。)
SpringBoot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化新 Spring应用的初始搭建以及开发过程。 该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。
SpringBoot分为Controller、Service、DAO(如果用Mybaits就称为MApper)、持久化层(DAO工艺Mapper去读取写入数据的地方)。
controller:拦截用户的请求,调用service,响应请求 (相当于服务员)
service:调用DIO层,加工数据 (相当于厨房)
DAO:获取数据 (相当于采购)
持久化层:存储数据 (相当于菜市场)
分层复用,模块化、结构化开发,便于维护。
搭建springboot 1.创建一个新项目:
2.创建一个模块
这里由于该插件只有在当前安装了插件的idea里会自动帮忙生成get、set方法,所以不适合代码协作。这里要注意,除了安装lombok的依赖项,还要到插件plugins里安装lombok插件。
编写测试代码 在SpringBoot三层里,必不可少的是controller,我们编写controller的代码进行测试。(可以将services和DAO的代码写到controller,不过一般不这么写)
创建一个controller包:
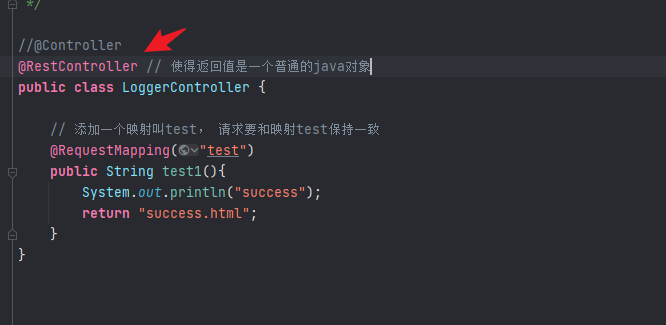
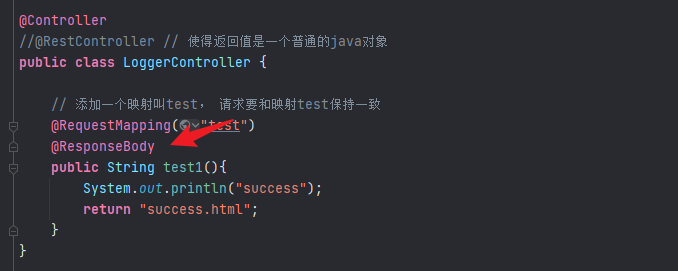
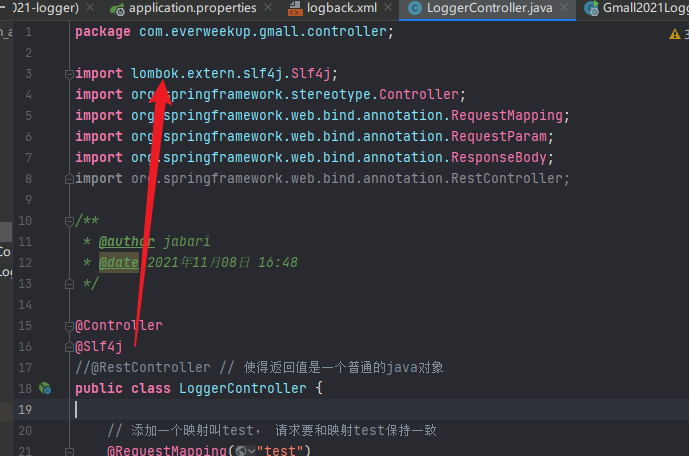
编写一个loggercontroller:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package com.everweekup.gmalllogger.controller;import org.springframework.stereotype.Controller;import org.springframework.web.bind.annotation.RequestMapping;@Controller public class LoggerController { @RequestMapping("test") public String test1 () { System.out.println("success" ); return "success" ; } }
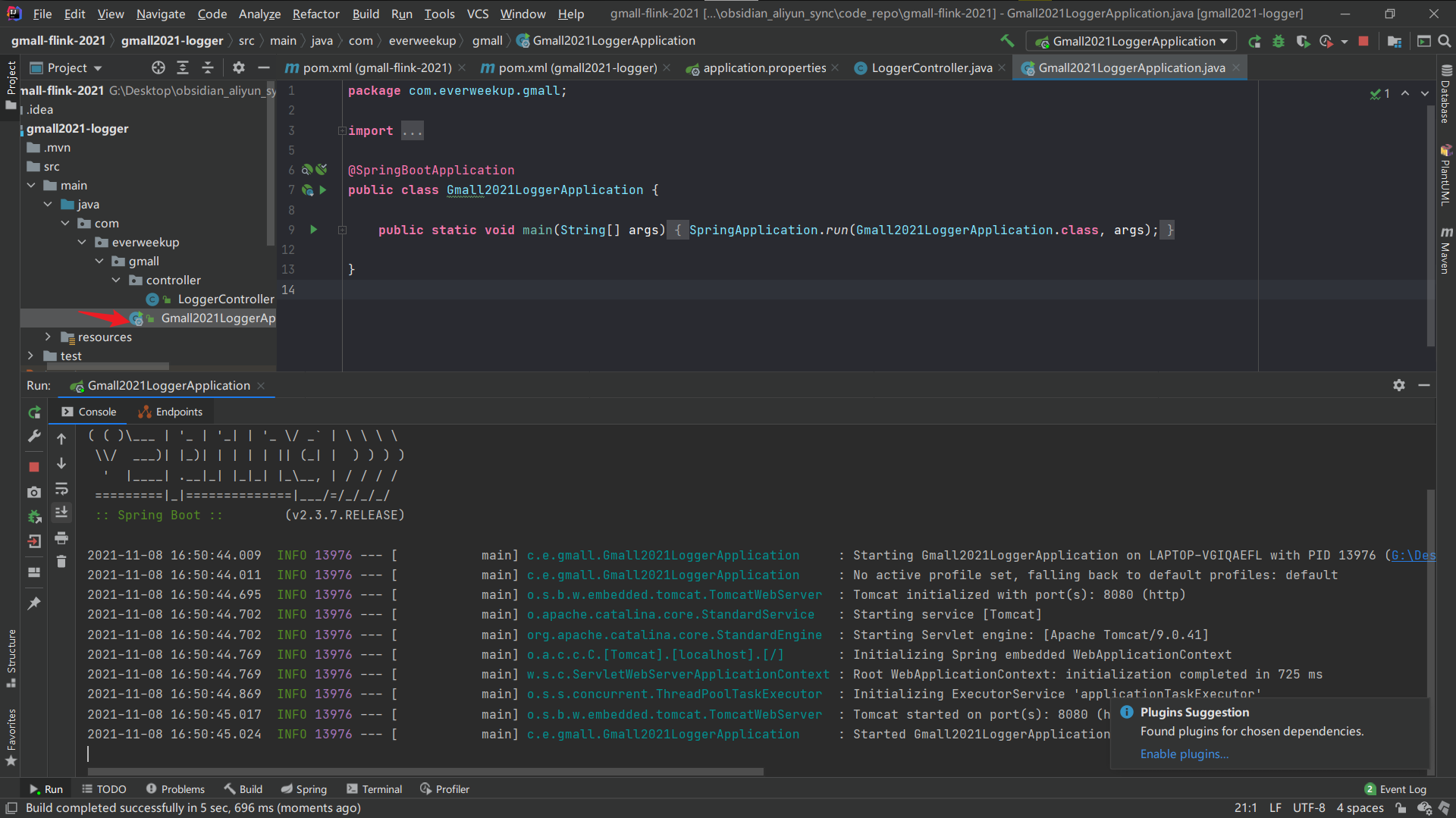
启动程序测试:
访问页面:
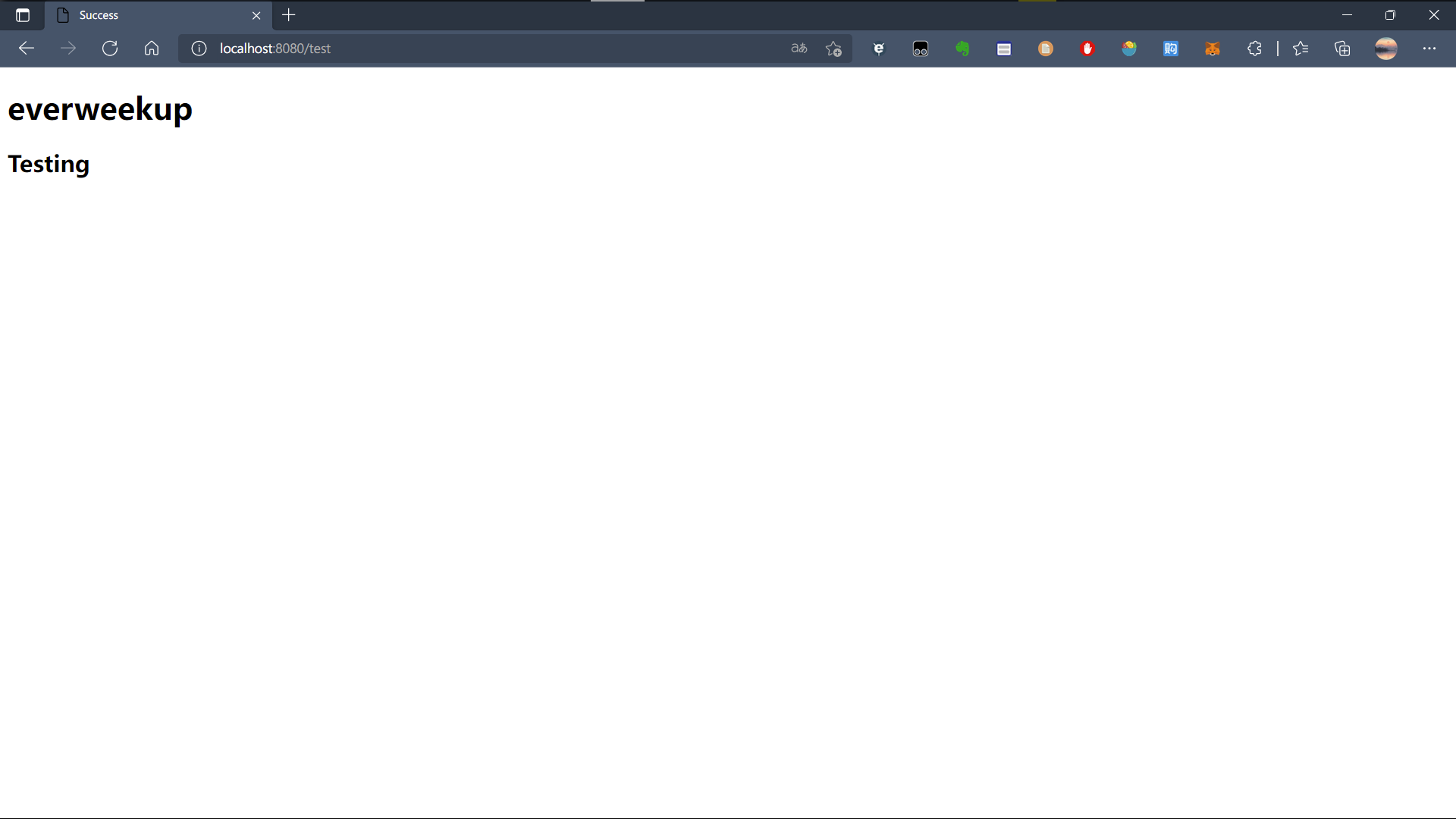
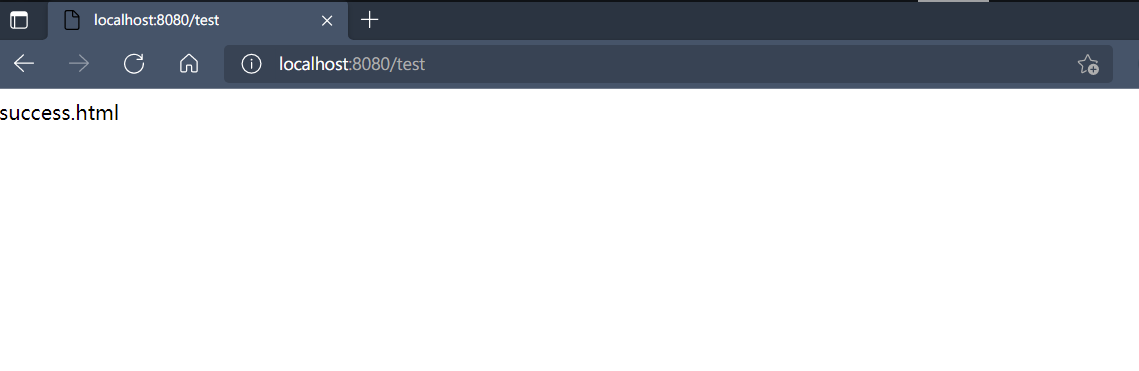
修改返回success.html,创建一个网页,重启程序访问:
访问成功:
如果只想让其返回java对象,有两种方式,第一种:
加了这个注释后,下面所有方法返回的对象都是普通的java对象。
第二种方式:
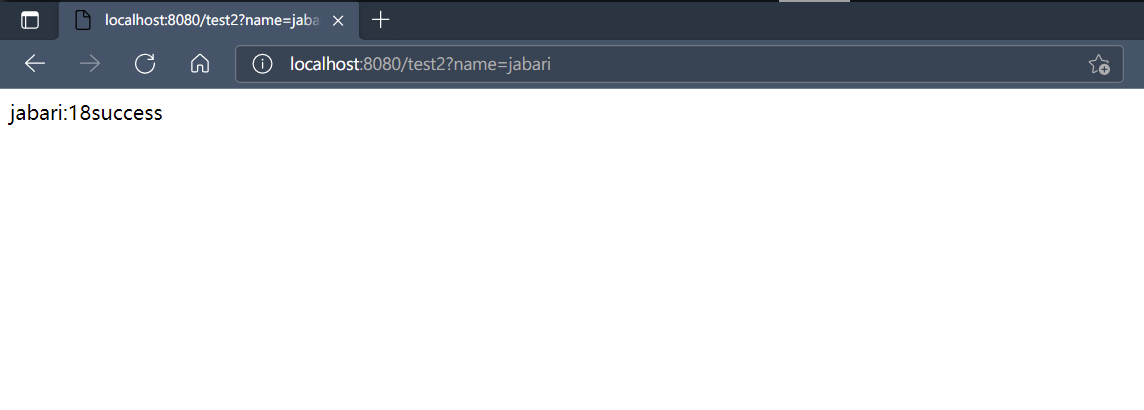
继续编写一个请求传入参数的方法:
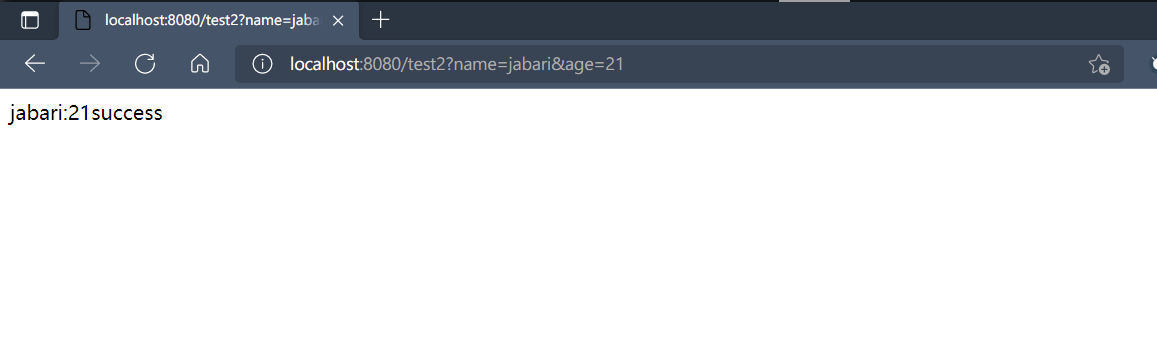
1 2 3 4 5 6 7 8 9 @RequestMapping("test2") @ResponseBody public String test2 (@RequestParam("name") String nn, @RequestParam(value = "age", defaultValue = "18") int age) { System.out.println("success" ); return nn + ":" + age + "success" ; }
请求里传入默认值:
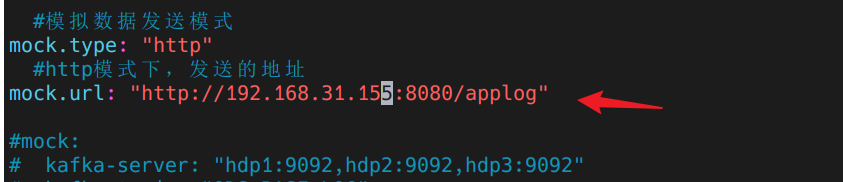
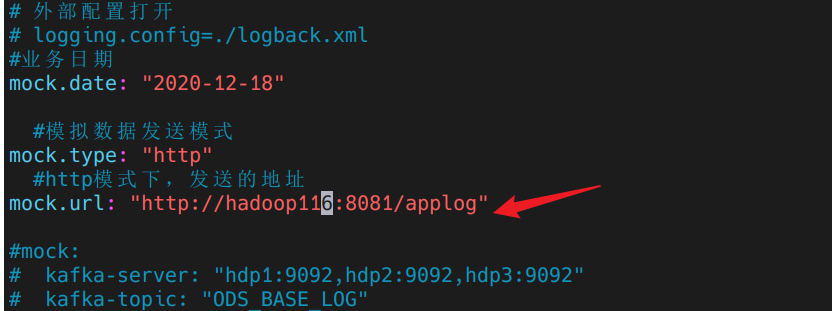
开始编写接收模拟请求代码 先查看请求地址配置文件:
1 2 3 4 5 (base) [dw@hadoop116 rt_applog]$ pwd /opt/module/gmall-flink/rt_applog (base) [dw@hadoop116 rt_applog]$ ls application.yml gmall2020-mock-log-2020-12-18.jar logs (base) [dw@hadoop116 rt_applog]$ vim application.yml
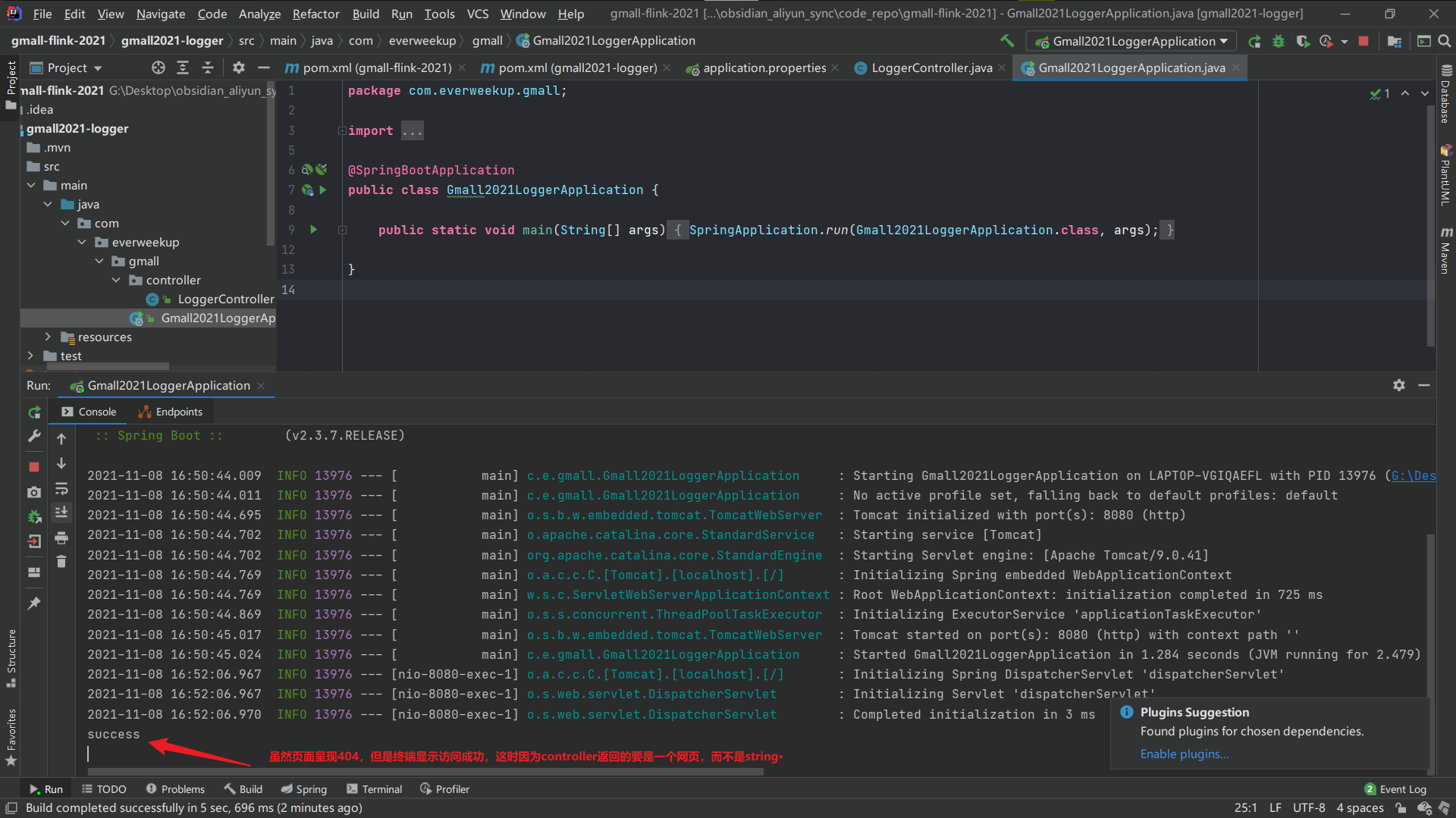
开始编写方法:
1 2 3 4 5 6 7 8 9 10 11 12 @RequestMapping("applog") public String getLog (@RequestParam("param") String jsonStr) { System.out.println(jsonStr); return "success" ; }
启动程序,修改请求发生配置文件的ip地址为本机地址:
虚拟机生成数据:
1 (base) [dw@hadoop116 rt_applog]$ java -jar gmall2020-mock-log-2020-12-18.jar
idea终端输出:
虚拟机终端输出:
开始编写落盘代码 使用日志打印的方式,将数据写入到磁盘。
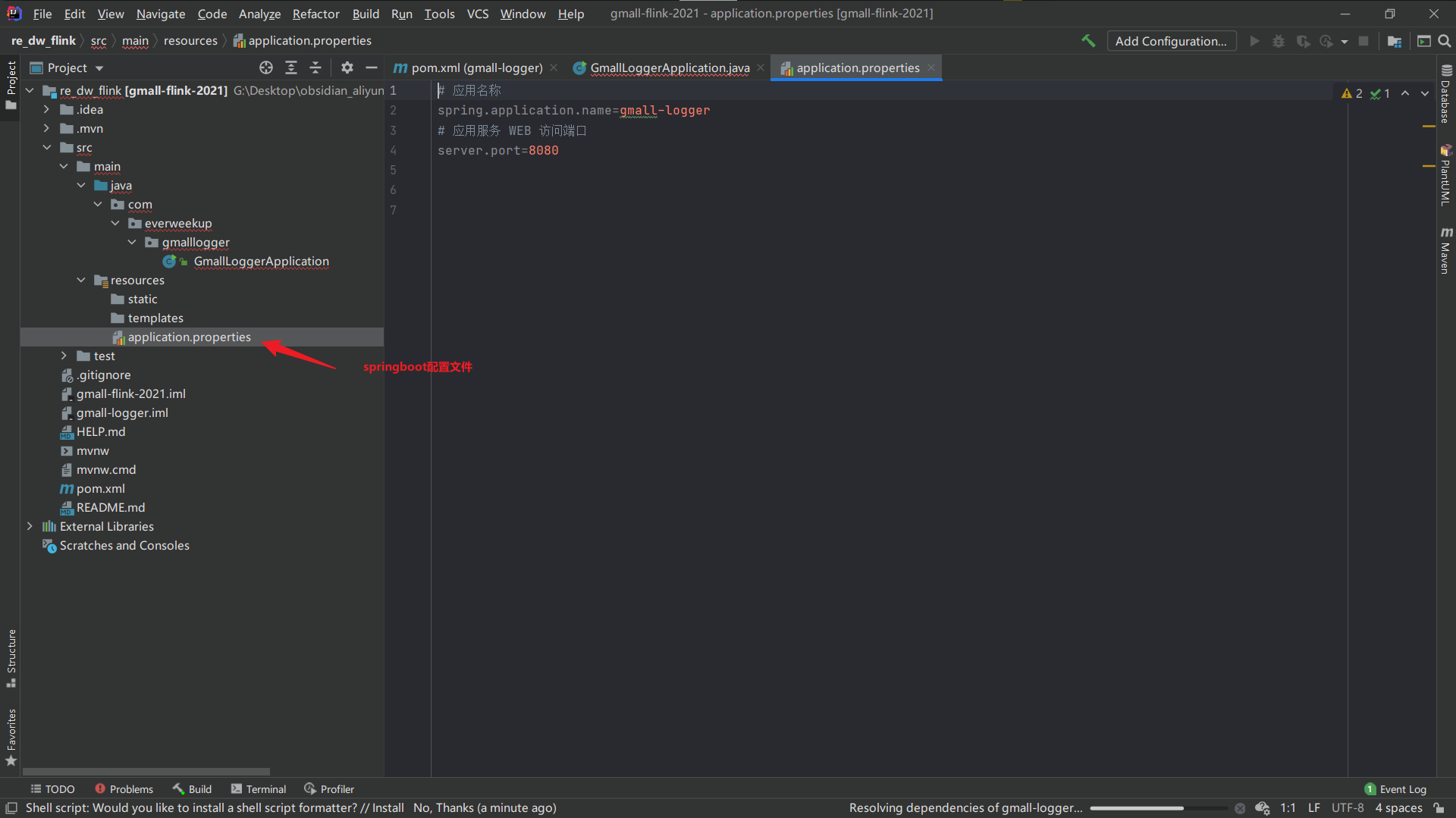
1.修改springboot配置
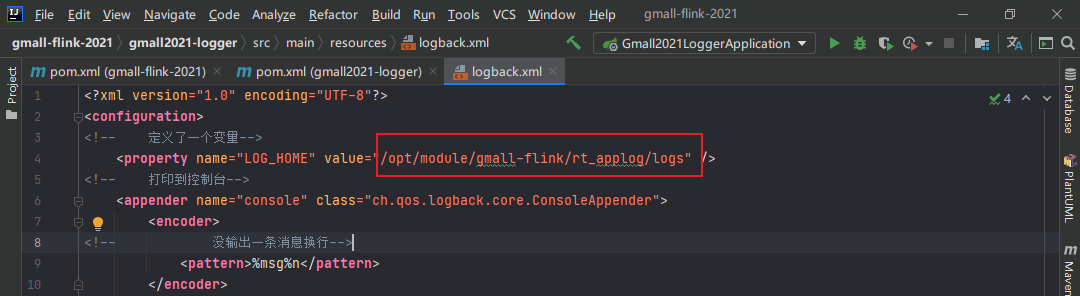
2.配置日志打印所需的xml配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 <?xml version="1.0" encoding="UTF-8" ?> <configuration > <property name ="LOG_HOME" value ="g:/Desktop/obsidian_aliyun_sync/code_repo/logs" /> <appender name ="console" class ="ch.qos.logback.core.ConsoleAppender" > <encoder > <pattern > %msg%n</pattern > </encoder > </appender > <appender name ="rollingFile" class ="ch.qos.logback.core.rolling.RollingFileAppender" > <file > ${LOG_HOME}/app.log</file > <rollingPolicy class ="ch.qos.logback.core.rolling.TimeBasedRollingPolicy" > <fileNamePattern > ${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern > </rollingPolicy > <encoder > <pattern > %msg%n</pattern > </encoder > </appender > <logger name ="com.everweekup.gmall.controller.LoggerController" level ="INFO" additivity ="false" > <appender-ref ref ="rollingFile" /> <appender-ref ref ="console" /> </logger > <root level ="error" additivity ="false" > <appender-ref ref ="console" /> </root > </configuration >
3.给代码添加log对象
注意这里引入的log对象是lombok包下的
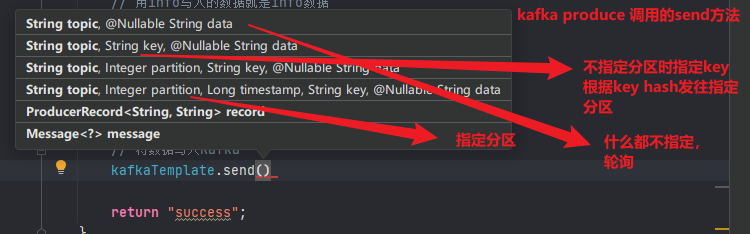
4.编写log打印和kafka对接代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 package com.everweekup.gmall.controller;import lombok.extern.slf4j.Slf4j;import org.apache.kafka.common.protocol.types.Field;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.stereotype.Controller;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.ResponseBody;import org.springframework.web.bind.annotation.RestController;@Slf4j @RestController public class LoggerController { @Autowired private KafkaTemplate<String, String> kafkaTemplate; @RequestMapping("test") public String test1 () { System.out.println("success" ); return "success.html" ; } @RequestMapping("test2") public String test2 (@RequestParam("name") String nn, @RequestParam(value = "age", defaultValue = "18") int age) { System.out.println("success" ); return nn + ":" + age + "success" ; } @RequestMapping("applog") public String getLog (@RequestParam("param") String jsonStr) { log.info(jsonStr); kafkaTemplate.send("ods_base_log" , jsonStr); return "success" ; } }
开始测试 1.启动kafka
先启动zk,再启动kafka集群:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 (base) [dw@hadoop116 module]$ zkS.sh start ---------- zookeeper hadoop116 启动 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cf g Starting zookeeper ... STARTED ---------- zookeeper hadoop117 启动 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cf g Starting zookeeper ... STARTED ---------- zookeeper hadoop118 启动 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cf g Starting zookeeper ... STARTED (base) [dw@hadoop116 kafka]$ pwd /opt/module/kafka (base) [dw@hadoop116 kafka]$ kafka.sh start --------启动 hadoop116 Kafka------- --------启动 hadoop117 Kafka------- --------启动 hadoop118 Kafka-------
2.创建主题
主题没创建直接消费该主题会报一个警告,但是可以往该主题发,默认配置是会自动创建主题,如果没创建的话。
1 2 ./bin/kafka-topics.sh --create --zookeeper localhost:2181/kafka --replication-factor 1 --partitions 10 --topic ods_base_log
这里我们不创建topic,直接启动kafka consumer,尝试运行下:
1 (base) [dw@hadoop116 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop116:9092 --topic ods_base_log
3.启动服务端
4.启动jar包
1 (base) [dw@hadoop116 rt_applog]$ java -jar gmall2020-mock-log-2020-12-18.jar
日志生成页面:
本地idea终端:
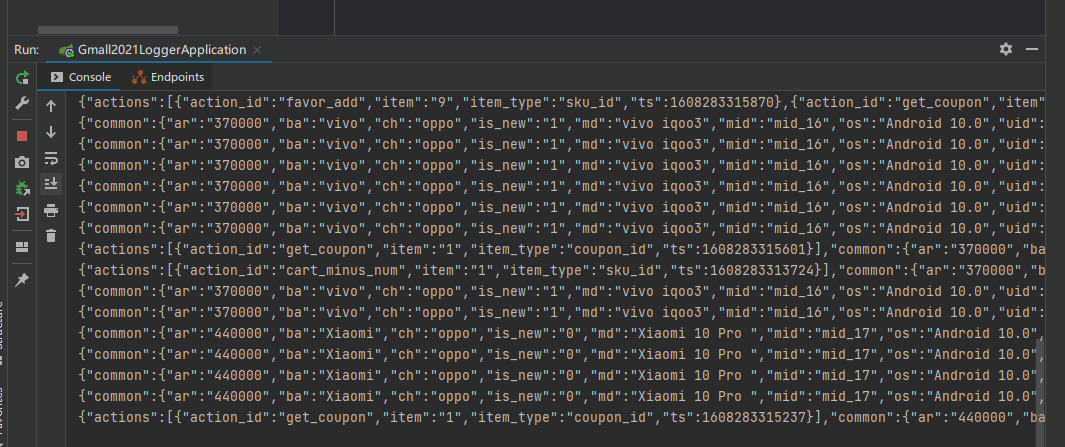
查看kafka消费者:
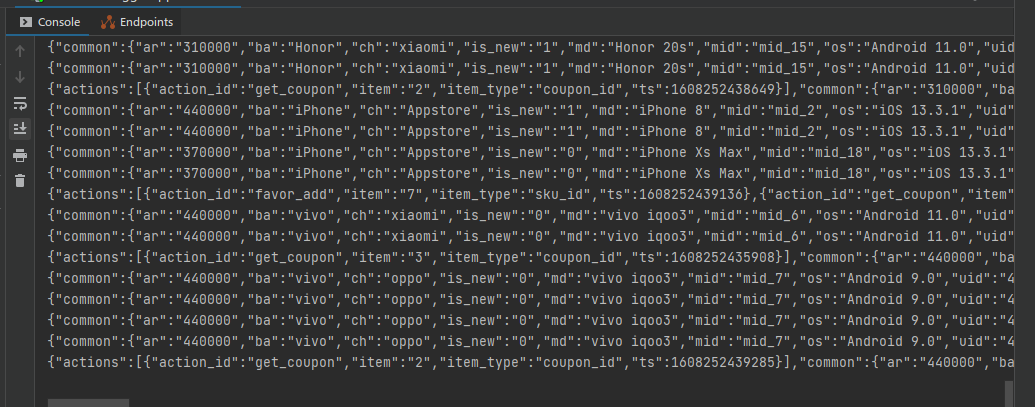
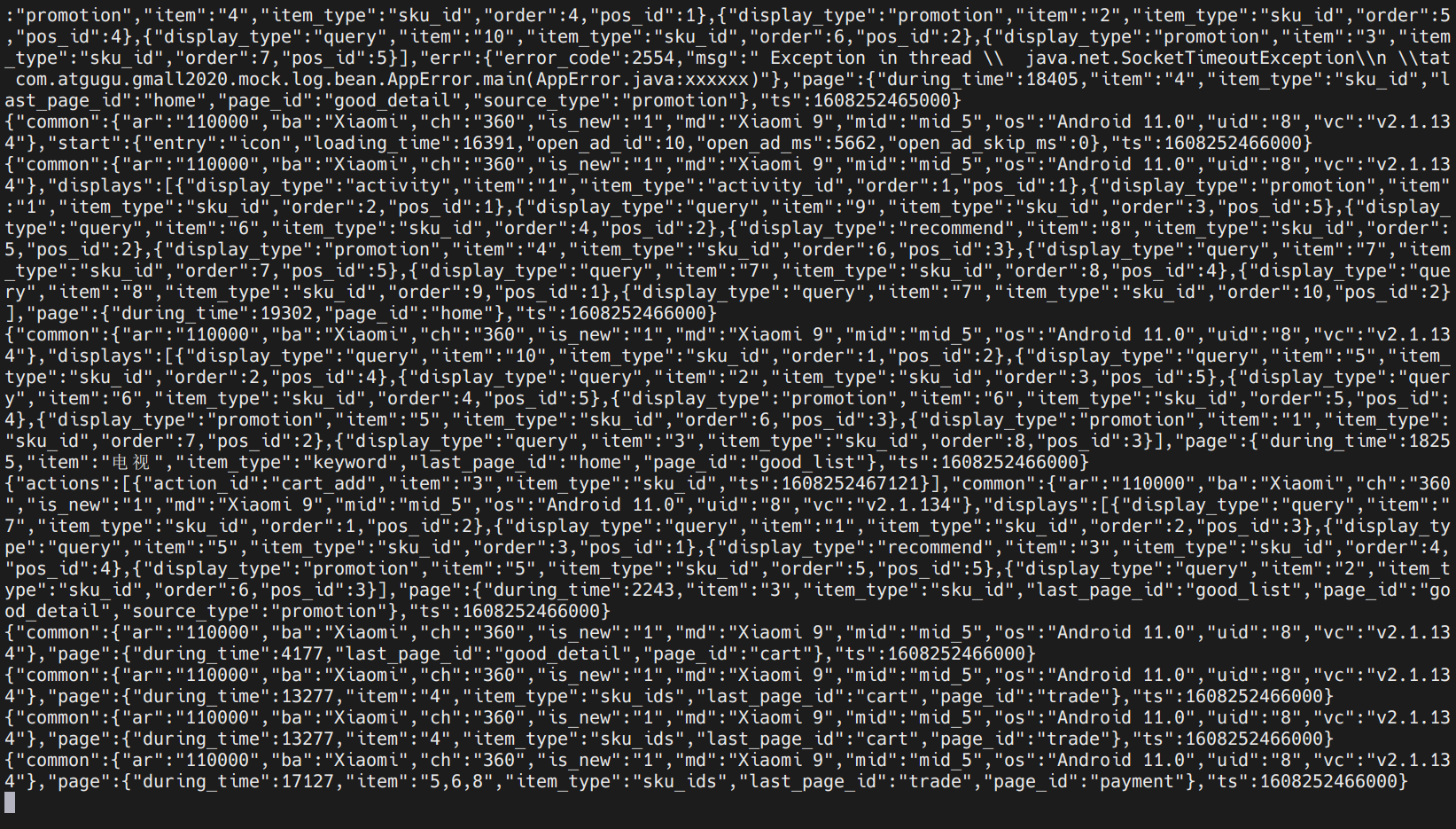
数据都在滚动生成。
检查时发现,kafka中没找到ods_base_log这个主题,那么数据生成保存到哪里去了?
模拟日志采集模块-集群测试 开始打包,单机部署 修改路径,因为要在linux上使用。
开始打包:
1 2 3 4 (base) [dw@hadoop116 rt_applog]$ mv gmall2021-logger-0.0.1-SNAPSHOT.jar gmall-logger.jar (base) [dw@hadoop116 rt_applog]$ (base) [dw@hadoop116 rt_applog]$ ls application.yml gmall2020-mock-log-2020-12-18.jar gmall-logger.jar logs
集群测试 上传到集群后,修改日志生成代码的目标IP地址
1.先启动web服务
1 2 3 4 5 6 7 8 9 10 11 12 (base) [dw@hadoop116 rt_applog]$ ls application.yml gmall2020-mock-log-2020-12-18.jar gmall-logger.jar logs (base) [dw@hadoop116 rt_applog]$ java -jar gmall-logger.jar . ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | ' _ | '_| | ' _ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.3.7.RELEASE)
2.启动kafka消费者
1 (base) [dw@hadoop116 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop116:9092 --topic ods_base_log
3.启动日志生成jar包
1 (base) [dw@hadoop116 rt_applog]$ java -jar gmall2020-mock-log-2020-12-18.jar
4.查看执行结果
Nginx搭建与负载均衡测试 该部分内容查看链接:Nginx搭建与负载均衡测试
*业务数据库数据采集 架构和FlinkCDC是这整个实时数仓的重点内容。业务数据采集中我们会用到FlinkCDC根据业务数据库的binlog来捕获变动数据,此外,我们还会对比FlinkCDC、Canal、Maxwell这三种CDC工具。
MYSQL数据准备 创建实时数据库:
导入建表数据:
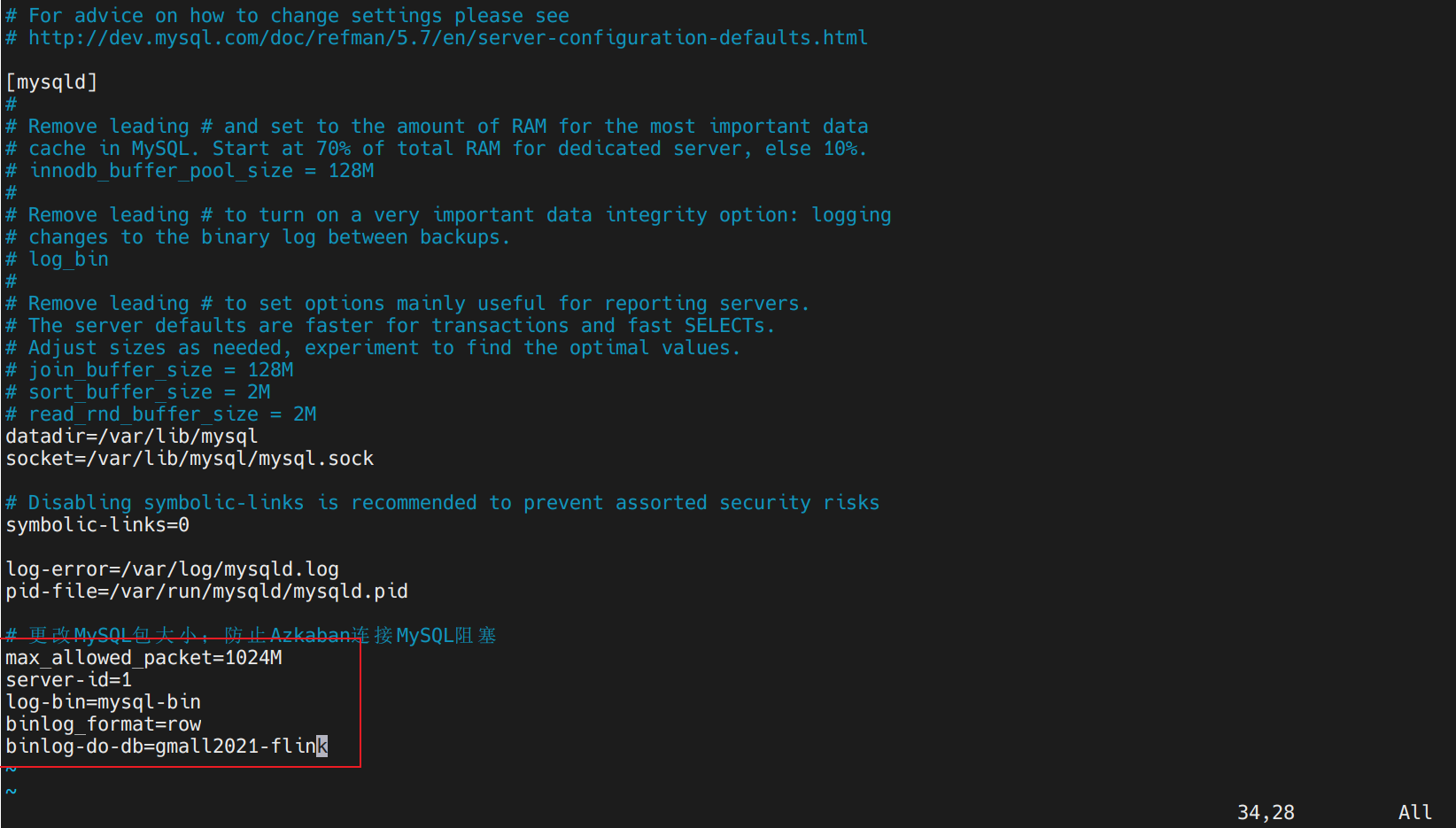
开启binlog 1 2 3 (base) [dw@hadoop116 logs]$ sudo vim /etc/my.cnf (base) [dw@hadoop116 logs]$ sudo systemctl restart mysqld
检验binlog生效 开启后进入到binlog所在目录下查看:
我们随便插入一条查看binlog有无变化:
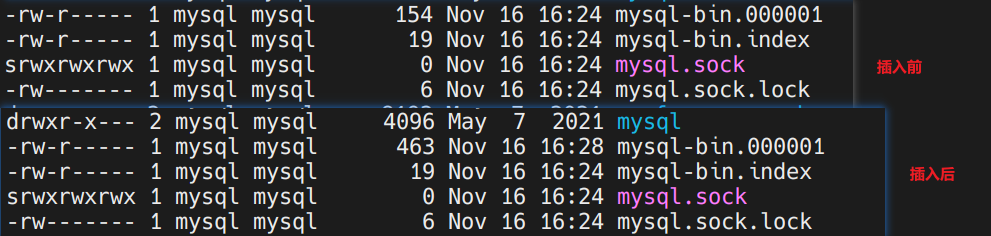
查看下binlog变化:
发现发生变化,binlog已经准备好了。
业务数据抓取—FlinkCDC 请参阅此链接:FlinkCDC
业务数据抓取—Canal&Maxwell CDC-Canal&Maxwell
FlinkCDC VS CanalCDC VS MaxwellCDC FlinkCDC VS CanalCDC VS MaxwellCDC