知识图谱概述(二)
知识图谱概述(二)
前面我们介绍了知识图谱的前置知识,在这部分我们来了解知识图谱的基础知识。
Google知识图谱的宣传语”things not strings”给出了知识图谱的精髓,即不要无意义的字符串,而是获取字符串背后隐含的对象或事物。
这里总结下,我们可以以谷歌提出KG为界线,简单的分为传统知识工程和大数据知识工程。
传统知识工程
知识工程源于符号主义(逻辑主义),符号主义认为知识是智能的基础。
在符号主义思潮的影响下,早期的人工智能专家认为,不管是机器的智能还是人的智能,本质都是符号的操作和运算。
因此,人工智能的核心问题是如何表示知识、推理知识以及应用知识。在那时候的研究中,研究者们十分关注让机器拥有人类知识,比如常识,或者更为重要的专家知识,让机器在此基础上再进行表示、推理及应用。因此在那个时期,大家非常关注发展知识工程。
传统的知识工程解決了一系列问题,比如蛋白质结构的发现,数学定理的证明。但总体而言,解决的是简单问题,特点:
- 规则明确
- 应用封闭
大数据知识工程
因为到了互联网时代,信息更新迭代迅猛,导致知识迅速突破了专家定义的边界,为了适应互联网特点,谷歌在2021年推出全新的知识图谱,宣告知识工程进入了大数据时代,一方面是需求驱动,一方面是条件使然:
- 数据、算力和模型的飞速发展
- 使得机器大规模、自动化的去获取数据,摆脱对专家知识的依赖;
- 众包技术
- 使得知识的规模化验证成为可能。众多的环节都可以基于这个技术。比如很多时候会做一个众包来获取标注,在短时间内获取有标注的数据去训练领域模型。
- 高质量的用户生成内容提供了高质量知识库来源。
知识图谱概念的提出
互联网的出现为大量内容创建者打开了创造内容产出信息的大门,为了帮助计算机理解这些高质量文档内容信息,需要一种有效的方式来组织和表示这些数据。针对此问题,研究人员提出了把数据中隐藏的知识用图结构的形式进行表示,于是基于语义网络提出了知识图谱的概念来解决这个问题。
简而言之,知识图谱以图结构的组织形式,通过语义关联描述客观世界中概念、实体及其关系。
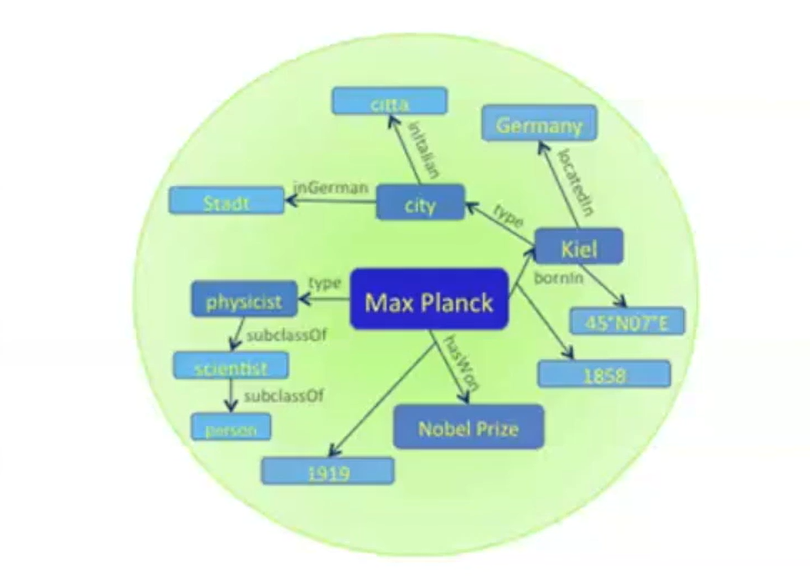
知识图谱是什么
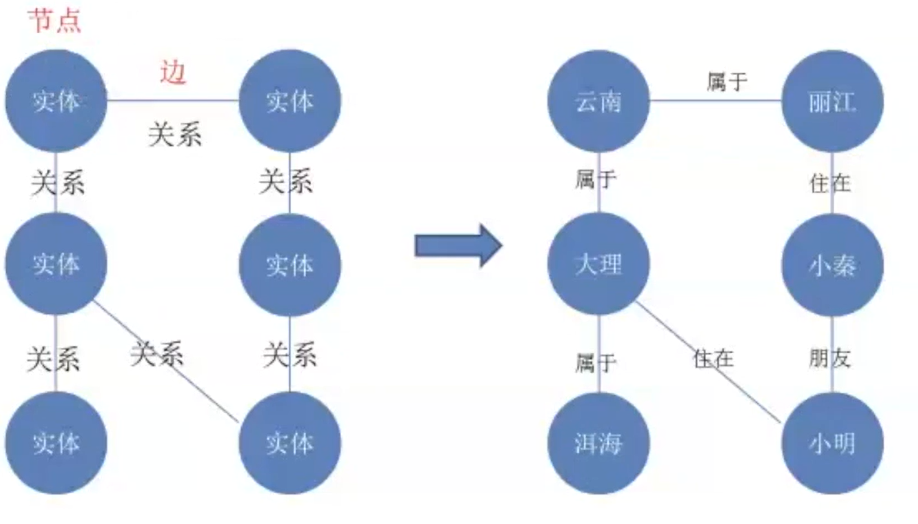
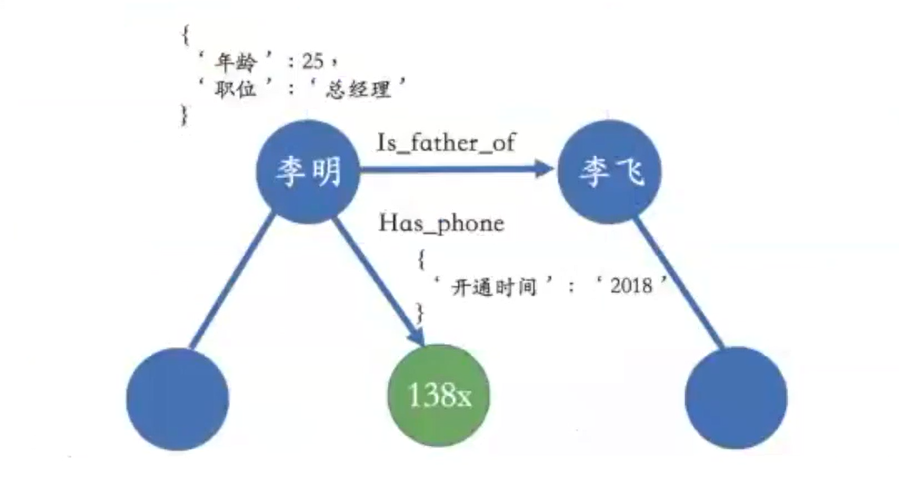
知识图谱是一种基于图的数据结构,由节点( point)和边(Edge)组成,每个节点表示一个“实体”,每条边为实体与实体之间的“关系”,知识图谱本质上是语义网络。
实体指的可以是现实世界中的事物,比如人、地名、公司、电话、动物等;关系则用来表达不同实体之间的某种联系。
由右图,可以看到实体有地名和人;大理属于云南、小明住在大理、小明和小秦是朋友,这些都是实体与实体之间的关系。
通俗定义:知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络,因此知识图谱提供了从“关系”的角度去分析问题的能力。
此外,我们要注意在现实世界中,实体和关系也会拥有各自的属性,比如人可以有“姓名”、“年龄”和“职业”。(注意:其实“姓名”也是一种属性)
知识有哪些?
事实知识
关于某个特定实体的基本事实。比如:李白生活在唐朝。也存在一些事实难以用简单的三元组进行表示,比如李白与杜甫之间的关系,很难用简单的语言描述。
概念知识
类属关系。理清楚概念之间的层级关系是构建知识图谱中模式设计的重要工作。
词汇知识
实体与词汇间的关系或者词汇之间的关系(上下位、反义、同义、缩略,上班-同义打工)
常识知识
人类与外界交互获得的知识,无须言明就能理解的知识,大部分与时间、空间以及因果相关。
7点月在禁
开源的知识图谱
事实型
DBpedia
Dbpedia项目始于2007年,是个多语言知识图谱,致力于从 Wikipedia页面中获取结构化的知识供大众使用,可称作为数据库版本的Wikipedia。
Qpply:https:/wiki.dbpedia.org/apply
CN-DBpedia
CN- Dbpedia是由复旦大学知识工场实验室(http://kw.fudan.edu.cn/)研发并维护的大规模通
用领域结构化百科,其前身是复且GDM中文知识图谱。
CN- DBpedia主要针对单数据源中文百科类网站(如百度百科、互动百科、中文维基百科等)进行深入挖掘,经知识抽取、知识清洗、知识填充以及知识更新等操作后,最终形成一个质量高、知识多、更新快的中文通用百科知识图谱,供机器和人访问。
CN- DBpedia自2015年12月份发布以来已经在可答机器人、智能玩具、智慧医疗、智慧软件等领域产生超过3.6亿次API调用量。
概念型
YAGO
YAGO是由德国马普研究所研制的链接数据库。YAGO主要集成了 Wikipedia、 Wordnet和 Geonames三个来源的数据。目前,YAGO包含1.2亿条三元组知识。
YAGO特点:人工审核,准确率在95%以上;考虑了时间和空间知识,为很多知识条目增加了时间和空间维度的属性描述;YAGO将 Wordnet的词汇定义与 Wikipedia的分类体系进行了融合集成,使得YAGO具有更加丰富的实体分类体系。
https://www.mpi-inf.mpg.de/departments/databases-and-information-systems/research/yago-naga/yago/
CN-Probase
CN- Probase是由复旦大学知识工场实验室研发并维护的大规模中文概念图谱,包含约1700万实体、27万概念和3300万isa关系。
isa关系的准确率在95%以上,是目前规模最大的开放领域中文概念图谱和概念分类体系。
相比较于其他概念图谱,CN- Probase具有两个显著优点:
一、规模巨大,基本涵盖常见实体;
二、严格按照实体进行组织,有利于实体的精准理解。
词汇型
WordNet
Word Net是由 Princeton大学的心理学家,语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典。它不是光把单词以字母顺序排列,而目按照单词的意义组成个”单词的网络”。 Word Net是个覆盖范围宽广的英语词汇语义网。名词,动词,形容词和副词各自被组织成一个同义词的网络每个同义词集合都代表个基本的语义概念,并目这些集合之间也由各种关系连接。
Wordnet的描述对象包含 compound(复合词)、 phrasal verb(短语动词)、 collocation(搭配词)idiomatic phrase(成语)、Word(单词),其中word是最基本的单位。
Wordnet的词汇结构包括九大类:上下位关系(动词、名词)、蕴含关系(动词)、相似关系(名词)成员部分关系(名词)、物质部分关系(名词)、部件部分关系(名词)、致使关系(动词)、相关动词关系(动词)、属性关系(形容词)。
BabelNet
相较WordNet联想能力更强。
Babelnet是个多语词汇语义网络和本体,由罗马萨皮恩扎大学(罗马大学)计算机科学系的计算语言学实验室所创建。
Babelneta是自动构建的,其将最大的多语Web百科全书维基百科链接到最常用的英语计算词典 Wordnet。
这种链接整合,以自动映射的方式完成;对于资源関乏的语言所存在的词汇空缺,借助于统计机器翻译来补充。其结果是个“百科词典”,提供了多种语言的概念和命名实体,并包含了它们之间的丰富的语义关系。
常识型
Cyc
cyc取自英文单词 Encyclopedia,是在1984年由MCC公司开始创建,最初的目标是要建立人类最大的常识知识库。
Cyc知识库主要由术语Tems和断言 Assertions组成。 Terms包含概念、关系和实体的定义。
Assertions用来建立 Terms之间的关系,用以支持机器像人类一样推理。
典型的常识知识如“燕子是一种鸟”,“鸟会飞”等,“燕子会飞吗”,系统会根据推理规则进行回答。
Cyc的主要特点是基于形式化的知识表示方法来刻画知识。形式化的优势是可以支持复杂的推理。但过于形式化也导致知识库的疒展性和应用的灵活性不够(鸵鸟会飞吗?)
Conceptnet
Conceptnet始于2004年,最早源于MT媒体实验室,是一个大型的多话言常识知识库,其中包含了大量计算机应该了解的关于这个世界的信息,这些信息有助于计算机做更好的搜索回答问题以及理解人类的意图,知识来源于互联网众包、游戏以及专家构建。
它由一些代表概念的节点构成,这些概念以自然语言的单词或者短语形式表达,并且其中标示了这些概念的关系。
其他
下面的网站提供了几乎所有的中文开源知识图谱: