commit、tree、blob三个对象关系
在前面,我们进入到.git裸仓库目录下对相应的文件及git数据类型做了一个解释。在存储这块,是git核心基础点,git能够提供优良存储能力对版本控制系统是非常关键。
在版本控制系统中,文件变更是很频繁的,如果没有一套好的文件存储机制,库随着日积月累是越来越大的,性能会越来越差。所以良好的文件存储机制对于一个版本控制系统来说是十分重要的。
Git对象彼此关系
我们从左往右的顺序进行讲解。每次执行git commit都会创建一个commit对象。一个commit会对应一棵树(一个commit仅对应一棵树),tree代表了取出某一个commit,这个commit在整个对应的就是这个commit对应的视图,这个视图里面存储了一个快照,这个快照集合存储了当前commit对应的本项目仓库的所有文件夹,以及文件的快照,即那个时间点你的文件夹、文件的样子通过tree呈现。
tree里面也包含了tree,tree就是一个文件夹。blob指的就是一个具体的文件。
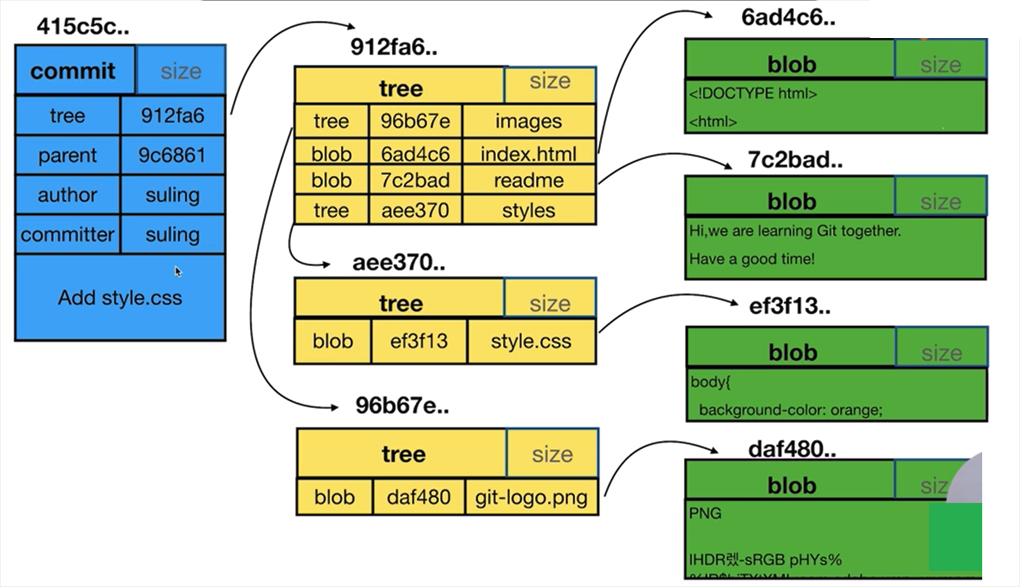
blob跟文件名没有关系,只要文件内容相同,则git就认为两个文件是同一个blob。
下面,我们进行实操。
实践练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| G:\mygitea\GitLearn\learn01 master
$ git log --oneline --all --graph
* e1514cf (temp) test1
* a1909d9 add 5bc7fdf file
* 5bc7fdf (HEAD -> master, checkout) rename test
* 012ae46 e1
* b390c28 (origin/master) add modified html css
* 58b4bfd add js
* 1d40e3a add css
* 1580123 add html images file
* 3cd7fd8 add readme
* df647fe Initial commit
G:\mygitea\GitLearn\learn01 master
$ git cat-file -p 1d40e3a
tree d4ad60182fea16159517aa825b21a5a712720d18
parent 1580123a0b8b0accaf7c6033381647ac01b671de
author GitHub Whiteco-okie <GitHub 1961663351@qq.com> 1651713921 +0800
committer Jabari <innocenfox@gmail.com> 1651715412 +0800
add css
G:\mygitea\GitLearn\learn01 master
$ git cat-file -p d4ad60182fe
100644 blob a58a8525f82c3e32934633d838f364039e68f44d LICENSE
100644 blob a437f1bf2beebbfae63bb067c5addc3739029b8f README.md
100644 blob 6bd030abf22a8ada1f4a2474e21b688577c7a1f8 Readme.md
040000 tree 96b67e399c8496ec36cbbbcb776eb924fad7f9a7 images
100644 blob 6ad4c68d567a1a5b415dcfce2010fce1a60b245f index.html
040000 tree aee37060401d19e7bd9f80b7b33920a000e96b5b styles
G:\mygitea\GitLearn\learn01 master
$ git cat-file -p 96b67e399c84
100644 blob daf480669aa9256fa18b5c28e467af816f16482d git-logo.png
G:\mygitea\GitLearn\learn01 master
$ git cat-file -p aee3706040
100644 blob ef3f137d8af338a8604544a3e482090684321d93 style.css
|
总结
现在我们应该明白git底层的运行流程了,当我们添加或者修改了文件并且add到Stage Area之后,首先会根据文件内容创建不同的blob,当进行提交之后马上创建一个tree组件把需要的blob组件添加进去,之后再封装到一个commit组件中完成本次提交。在将来进行reset的时候可以直接使用git reset —hard xxxxx可以恢复到某个特定的版本,在reset之后,git会根据这个commit组件的id快速的找到tree组件,然后根据tree找到blob组件,之后对仓库进行还原,整个过程都是以hash和二进制进行操作,所以git执行效率非常之高。
Q1:每次commit,git 都会将当前项目的所有文件夹及文件快照保存到objects目录,如果项目文件比较大,不断迭代,commit无数次后,objects目录中文件大小是不是会变得无限大?
很好的问题!我们之前提到blob,Git对于内容相同的文件只会存一个blob,不同的commit的区别是commit、tree和有差异的blob,多数未变更的文件对应的blob都是相同的,这么设计对于版本管理系统来说可以省很多存储空间。其次,Git还有增量存储的机制,我估计是对于差异很小的blob设计的吧。






