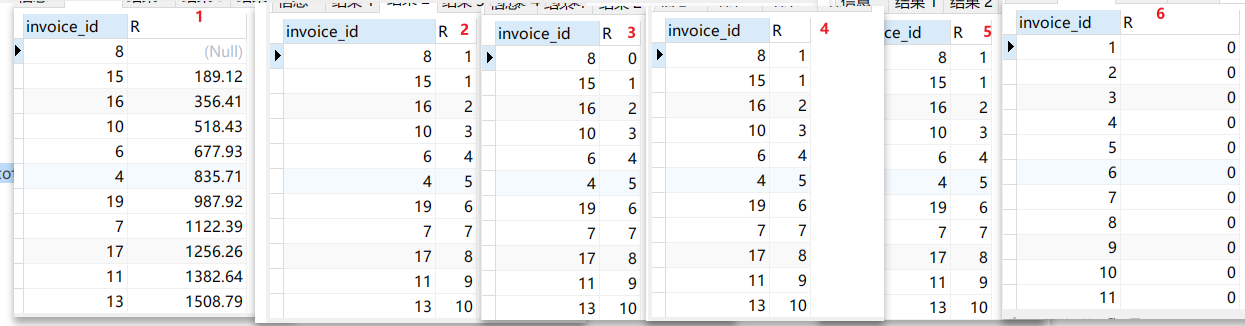
USE sql_invoicing; -- 1. select i.invoice_id, sum(i2.invoice_total) as R from invoices i leftjoin invoices i2 on i.invoice_total < i2.invoice_total groupby i.invoice_id ORDERBY R; -- 2. select i.invoice_id, count(1) as R -- 1改成2、3、4、5...结果都是一样,count()代表的是一个固定的值 from invoices i leftjoin invoices i2 on i.invoice_total < i2.invoice_total groupby i.invoice_id ORDERBY R; -- 3. select i.invoice_id, count(i2.invoice_total) as R from invoices i leftjoin invoices i2 on i.invoice_total < i2.invoice_total groupby i.invoice_id ORDERBY R; -- 4. select i.invoice_id, count(*) as R from invoices i leftjoin invoices i2 on i.invoice_total < i2.invoice_total groupby i.invoice_id ORDERBY R; -- 5. select i.invoice_id, count('') as R from invoices i leftjoin invoices i2 on i.invoice_total < i2.invoice_total groupby i.invoice_id ORDERBY R; -- 6. select i.invoice_id, count(NULL) as R from invoices i leftjoin invoices i2 on i.invoice_total < i2.invoice_total groupby i.invoice_id ORDERBY R;