
大数据分布式计算之流式数据处理——SparkStreaming
Spark Streaming
Spark Streaming简介

Spark Streaming是Spark核心API的一个扩展,可以实现实时数据的可拓展,高吞吐量,容错机制的实时流处理框架。
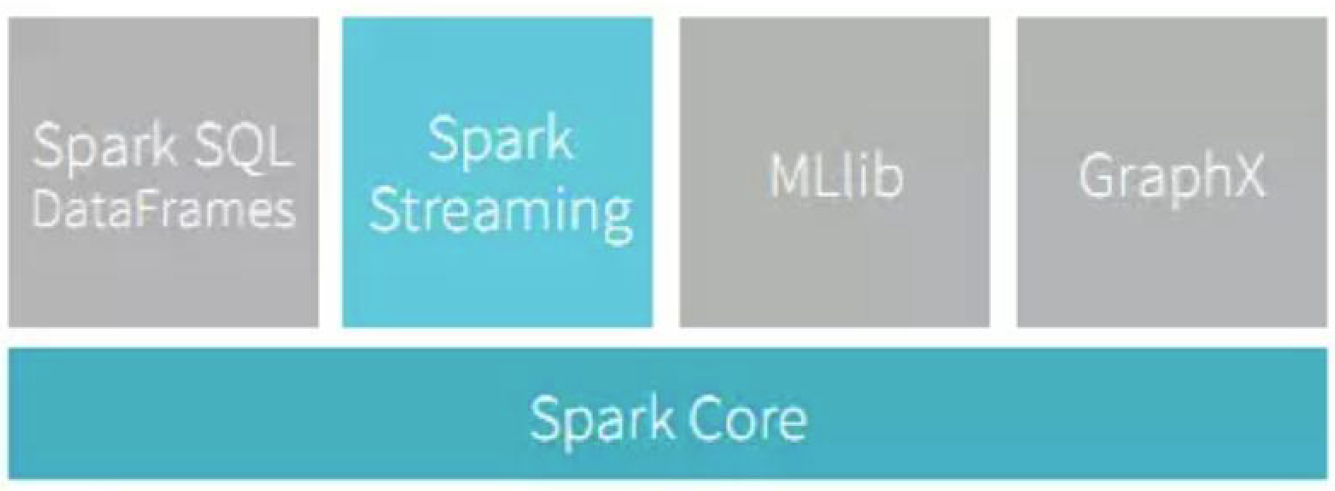
Spark Streaming 支持的数据输入源很多,例如:Kafka、 Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming 也能和 MLlib(机器学习)以及 Graphx 完美融合。
流数据特点:
- 数据一直在变化
- 数据无法回退
- 数据始终源源不断涌进
DStream
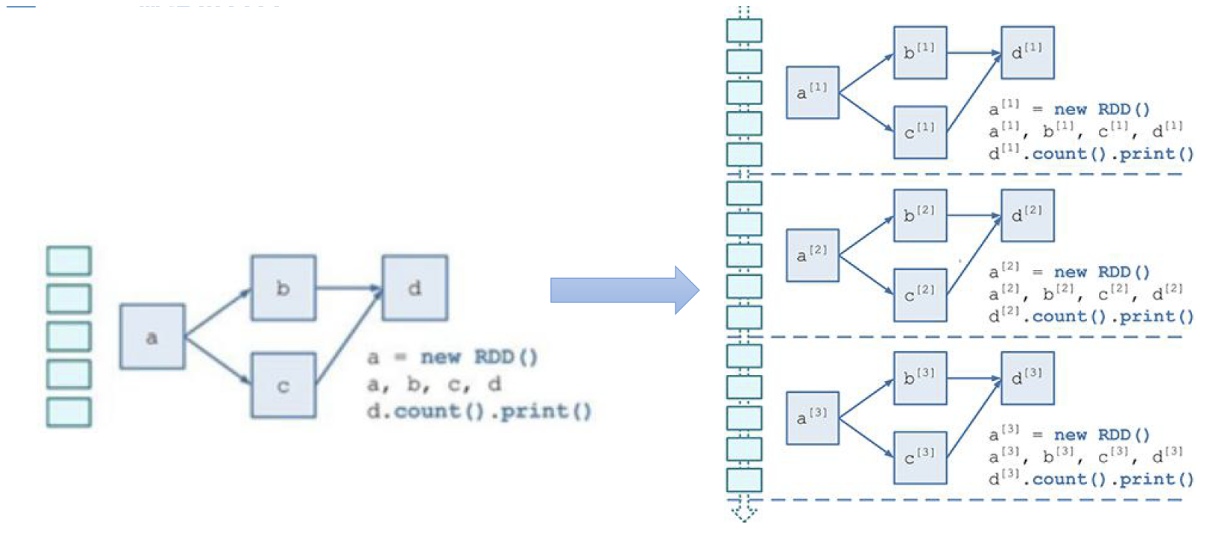
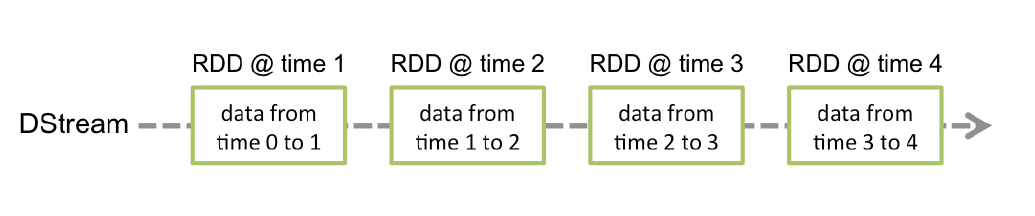
和 Spark 基于 RDD 的概念很相似,Spark Streaming 使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而DStream 是由这些RDD 所组成的序列(因此得名“离散化”)。
DStream形成步骤:
- 针对某个时间段切分的小数据块进行RDD DAG构建;
- 连续时间内产生的一连串小的数据进行切片处理分别构建RDD DAG,形成DStream;
定义一个RDD处理逻辑,数据按照时间切片,每次流入的数据都不一样,但是RDD的DAG逻辑是一样的,即按照时间划分成一个个batch,用同一个逻辑处理。
 DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。创建出来的 DStream 支持两种操作,一种是转化操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。创建出来的 DStream 支持两种操作,一种是转化操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
SparkStreaming特点
- 易用;
- 容错;
- 易整合到Spark体系中;
SparkStraming架构
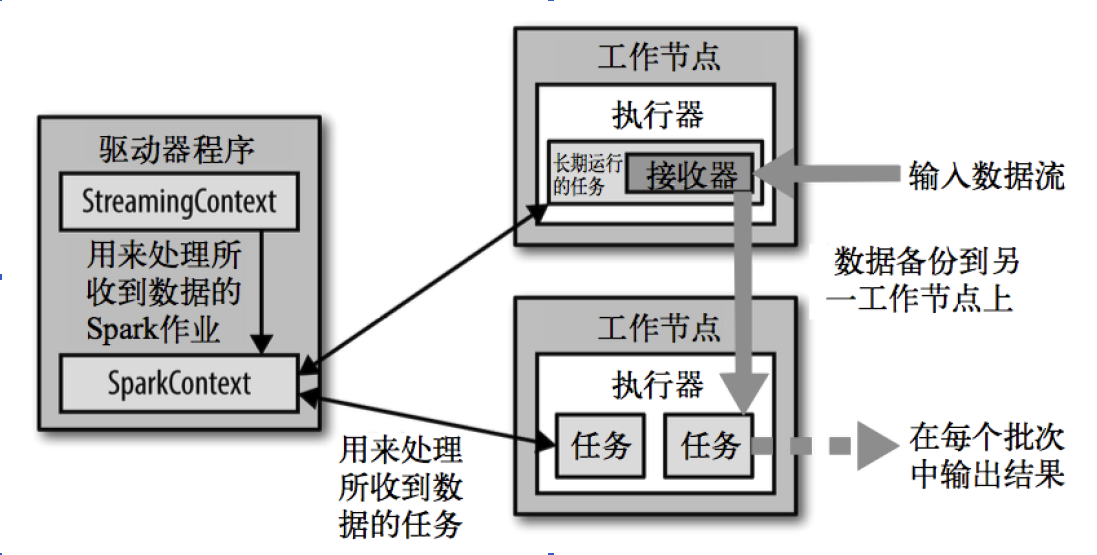
SparkStreaming架构由三个模块组成:
- Master:记录Dstream之间的依赖关系或者血缘关系,并负责任务调度以生成新的RD
- Worker:①从网络接收数据并存储到内存中 ②执行RDD计算
- Client:负责向Spark Streaming中灌入数据(flume kafka)
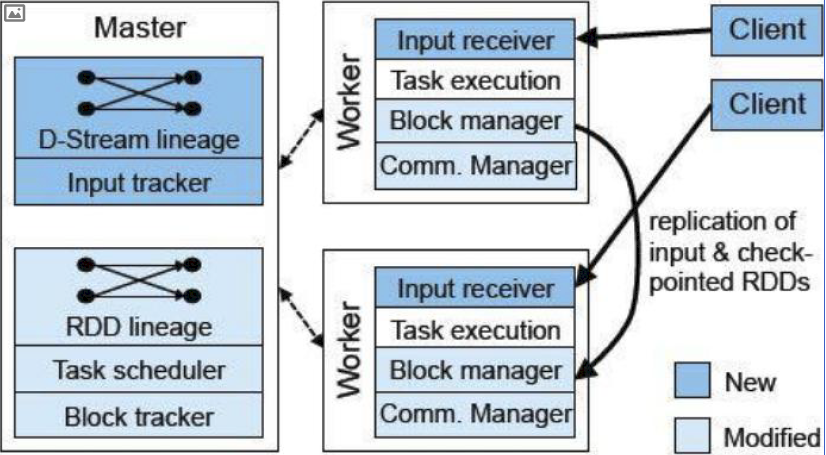
SparkStreaming 作业提交
相关组件
Network Input Tracker
跟踪每一个网络 received数据,并且将其映射到相应的 Input Dstream上
Job Scheduler
周期性的访问 Dstream Graph并生成 Spark Job,将其交给 Job Manager执行
Job Manager
获取任务队列,并执行 Spark任务
具体流程
要传入的数据会编排成block id(元数据)的形式,再加上RDD的逻辑,就生产了job scheduler,通过job manager形成job queue,以队列形式有序执行。真正的数据是以block形式传入worker,由worker上的executor通过元数据信息Block ID去HDFS上拉取对应的block数据进行执行。
Network Input Tracker传入的并不是真正的数据,而是Block IDs,相当于获取的是元数据,数据是通过worker进行接受的,也就是说Master上不管真正数据的接受情况,Master上只是能够拿到数据block的id,至于这些block做什么操作,是会放到 Job Manager去,按照顺序执行。

SparkStreaming工作原理
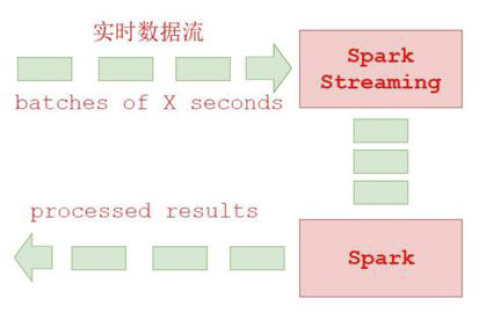
Discretized Stream 是Spark Streaming 的基础抽象,代表持续性的数据流和经过各种 Spark 原语操作后的结果数据流。在内部实现上,DStream 是一系列连续的RDD 来表示。每个RDD 含有一段时间间隔内的数据。简单来说,SparkStreaming接受实时的数据流,把数据按照指定的时间段切成一片片小的数据块(SparkStreaming将每个小的数据块当作RDD来处理),然后把数据块传给Spark Engine处理,最终得到一批批的结果。
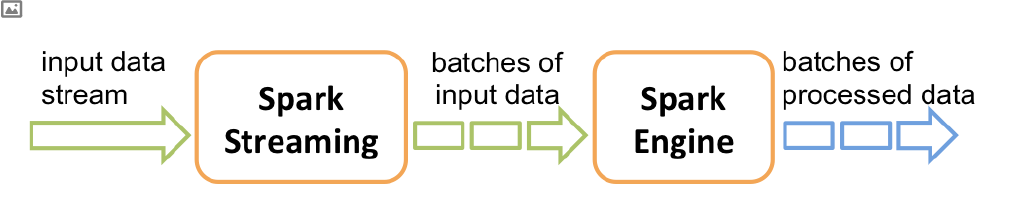
- 每一批数据,在Spark内核中对应一个RDD实例
- DStream可以看作一组RDDs,是持续的RDD序列
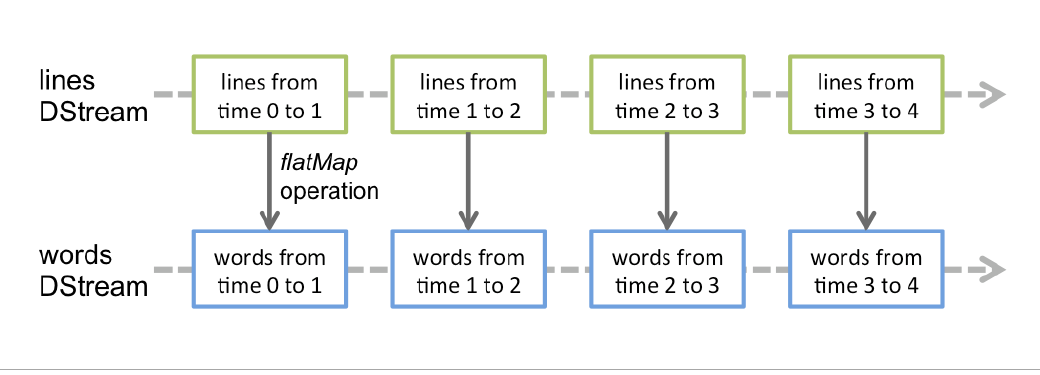
对于Streaming来说,它的单位是DStream,而对于SparkCore,它的单位是RDD。针对Spark开发,就是开发RDD的DAG图,而针对SparkStreaming,就是开发DStream。
DStream 代表连续的一组RDD,每个RDD都包含特定时间间隔的数据。DStream内部的操作,可以直接映射到内部RDD进行,相当于DStream是在RDD上增加一个时间的维度得到的。RDD是DStream最小的一个数据单元。DStream中对数据的操作也是按照RDD为单位来进行的。
简单来理解,SparkStreaming对于流数据的处理速度是秒级别,无法达到Storm的毫秒级别,因此也可以将Streaming看作是微批处理。(细品)
DStream
整体上来讲,Spark Streaming 的处理思路:将连续的数据持久化、离散化,然后进行批量处。对上面这句话进行分析:
- 数据持久化:接收到的数据暂存,方便数据出错进行回滚
- 离散化:按时间分片,形成处理单元
- 分片处理:采用RDD模式将数据分批处理
- DStrea m 相当于对 RDD 的再次封装 ,它提供了转化操作和输出操作两种操作方法
DStream创建注意事项
Spark Streaming 原生支持一些不同的数据源。一些“核心”数据源已经被打包到 Spark Streaming 的 Maven 工件中,而其他的一些则可以通过 spark-streaming-kafka 等附加工件获取。每个接收器都以 Spark 执行器程序中一个长期运行的任务的形式运行,因此会占据分配给应用的 CPU 核心。此外,我们还需要有可用的 CPU 核心来处理数据。这意味着如果要运行多个接收器,就必须至少有和接收器数目相同的核心数,还要加上用来完成计算所需要的核心数。例如,如果我们想要在流计算应用中运行 10 个接收器,那么至少需要为应用分配 11 个 CPU 核心。所以如果在本地模式运行,不要使用local 或者 local[1]。
DStream转换
DStream 上的原语与 RDD 的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window 相关的原语。
TransFormation:
- Spark支持RDD进行各种转换,因为 Dstream是由RDD组成的,Spark Streaming提供了一个可以在 DStream上使用的转换集合,这些集合和RDD上可用的转换类似;
- 转换应用到 Dstream的每个RDD;
- Spark Streaming提供了 reduce和 count这样的算子,但不会直接触发 Dstream计算;
- 常用算子:Map、 flatMap、 join、 reduceByKey;
Output:
- Print:控制台输出;
- saveAsObjectFile、 saveAsTextFile、 saveAsHadoopFiles:将一批数据输出到 Hadoop文件系统中,用批量数据的开始时间戳来命名;
- forEachRDD:允许用户对 Stream的每一批量数据对应的RDD本身做任意操作;
DStream = [rdd1, rdd2, …, rddn]
RDD两类算子:transformation、action
DStream两类算子:transformation、output
无状态转换
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。部分无状态转化操作列在了下表中。注意,针对键值对的 DStream 转化操作(比如 reduceByKey())要添加 import StreamingContext._才能在 Scala 中使用。

需要注意的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个DStream 在内部是由许多RDD(批次)组成,且无状态转化操作是分别应用到每个 RDD 上的。例如,reduceByKey()会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
无状态转化操作也能在多个 DStream 间整合数据,不过也是在各个时间区间内。例如,键 值对DStream 拥有和RDD 一样的与连接相关的转化操作,也就是cogroup()、join()、leftOuterJoin() 等。我们可以在DStream 上使用这些操作,这样就对每个批次分别执行了对应的RDD 操作。
我们还可以像在常规的 Spark 中一样使用 DStream 的 union() 操作将它和另一个 DStream 的内容合并起来,也可以使用 StreamingContext.union()来合并多个流。
有状态转换
UpdateStateByKey (全局统计量)
UpdateStateByKey 原语用于记录历史记录,有时,我们需要在DStream 中跨批次维护状态(例如流计算中累加wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个状态变量的访问,用于键值对形式的DStream。
给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
- updateStateByKey() 的结果会是一个新的 DStream,其内部的 RDD 序列是由每个时间区间对应的(键,状态)对组成的。
- updateStateByKey 操作使得我们可以在用新信息进行更新时保持任意的状态。
为使用这个功能,你需要做下面两步:
- 定义状态,状态可以是一个任意的数据类型。
- 定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新。 使用updateStateByKey 需要对检查点目录进行配置,会使用检查点来保存状态。
1 | package SparkStreamingTset |
如果要使用updateStateByKey算子,就必须设置一个checkpoint目录,开启checkpoint机制,这样的话才能把每个key对应的state除了在内存中有,在磁盘上也checkpoint一份。因为要长期保存一份key的state的话,那么spark streaming是要求必须用checkpoint的,以避免内存数据的丢失。
主要解决:
比如说在双十一统计一天销量和成交金额,这些计算需要全量汇总,对数据进行累加,就需要避免数据在内存中丢失,造成不准确。
Window Operations
Window Operations 有点类似于 Storm 中的 State,可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming 的允许状态。
基于窗口的操作会在一个比 StreamingContext 的批次间隔更长的时间范围内,通过整合多个批次(在窗口内的批次)的结果,计算出整个窗口的结果。
简单来说,Streaming的Window Operations是Spark提供的一组窗口操作,通过滑动窗口的技术,对大规模数据的增量更新进行统计分析,即定时进行一段时间内的数据处理。
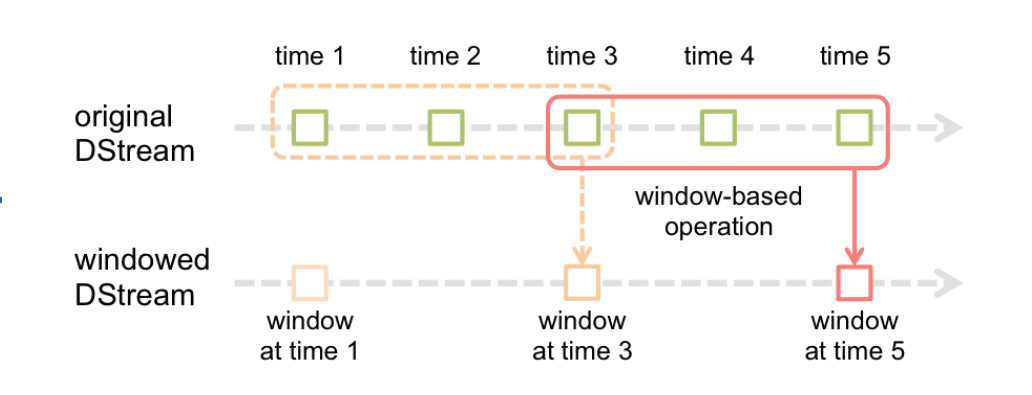
所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长,两者都必须是 StreamContext 的批次间隔的整数倍。
窗口时长控制每次计算最近的多少个批次的数据,其实就是最近的 windowDuration/batchInterval 个批次。如果有一个以 10 秒为批次间隔的源 DStream,要创建一个最近 30 秒的时间窗口(即最近 3 个批次),就应当把 windowDuration 设为 30 秒。而滑动步长的默认值与批次间隔相等,用来控制对新的 DStream 进行计算的间隔。如果源 DStream 批次间隔为 10 秒,并且我们只希望每两个批次计算一次窗口结果, 就应该把滑动步长设置为 20 秒。

滑动窗口的长度必须是滑动时间间隔的整数倍。因为RDD是DStream上最小的数据单元不可切分。如果不是整数倍,会出现一个RDD被切分的情况,程序会报错。
DStream Graph
DStream Graph是一系列transformation操作的抽象,例如:
c = a.join(b), d = c.filter() 时, 它们的 DAG 逻辑关系是a/b → c,c → d,但在 Spark Streaming 在进行物理记录时却是反向的 a/b ← c, c ← d, 目的是为了追溯。
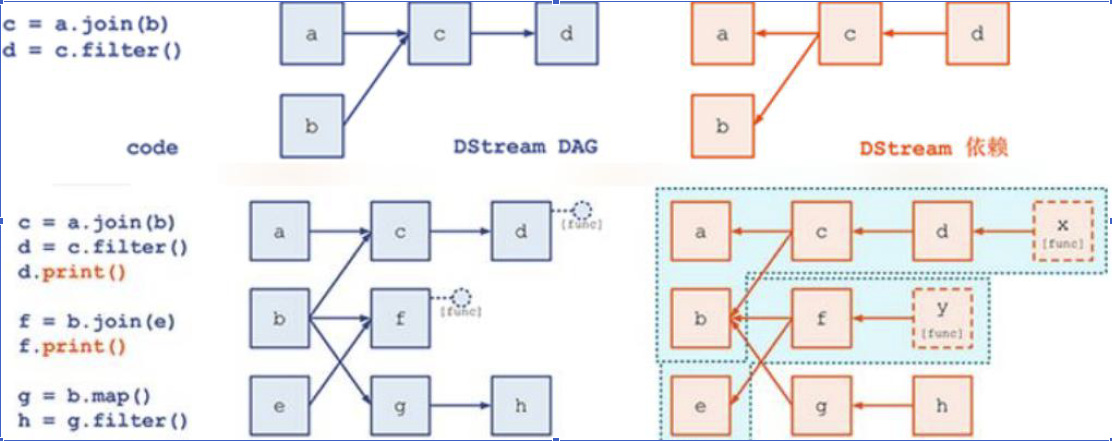
DStreamGraph:
①找代码输出
②根据输出再往前追溯依赖关系
Dstream之间的转换所形成的的依赖关系全部保存在DStreamGraph中, DStreamGraph对于后期生成RDD Graph至关重要。
DStreamGraph有点像简洁版的DAG scheduler,负责根据某个时间间隔生成一序列 JobSet,以及按照依赖关系序列化
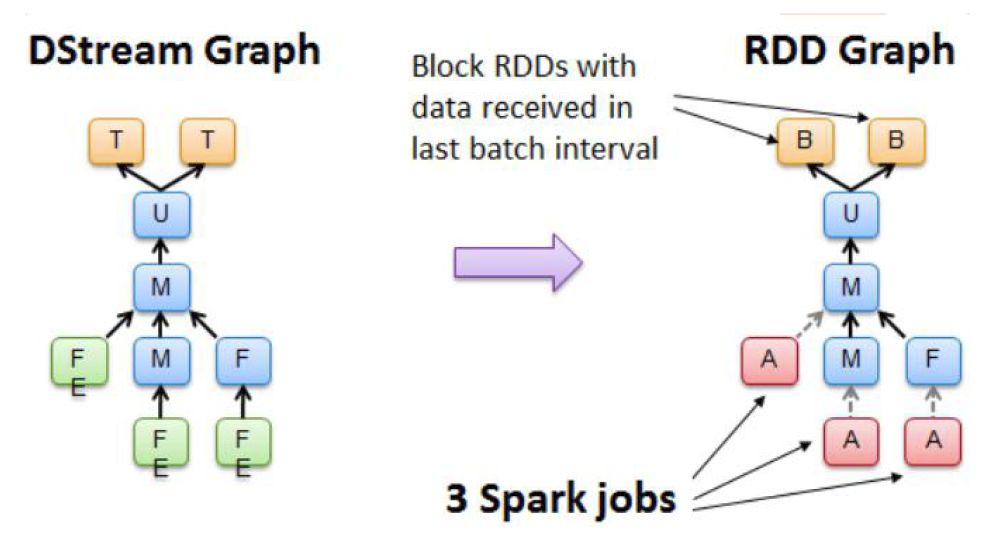
代码是一直在跑的,每隔一定时间就会形成一个RDD。
理解DStream与RDD:
DStream.map(RDD => RDD.map)
Streaming容错性分析*
实时的流式处理系统必须是7*24运行的,同时可以从各种各样的系统错误中恢复,在设计之初,Spark Streaming就支持driver和worker节点的错误恢复。
Worker容错:
spark和rdd的保证worker节点的容错性。spark streaming构建在spark之上,所以它的worker节点也是同样的容错机制
Driver容错:
依赖WAL(Write Ahead Log)持久化日志 (前提是数据源来自Kafka)
- 启动WAL需要做如下的配置
- 给streamingContext设置checkpoint的目录,该目录必须是HADOOP支持的文件系统hdfs,用来保存WAL和做Streaming的checkpoint;
- spark.streaming.receiver.writeAheadLog.enable 设置为true; receiver才有WAL;
WAL简介**
Spark应用分布式运行的,如果driver进程挂了,所有的executor进程将不可用,保存在这些进程所持有内存中的数据将会丢失。为了避免这些数据的丢失,Spark Streaming中引入了一个WAL (write ahead logs)。
WAL在文件系统和数据库中用于数据操作的持久化,先把数据写到一个持久化的日志中,然后对数据做操作,如果操作过程中系统挂了,恢复的时候可以重新读取日志文件再次进行操作。
如果WAL 启用了,所有接收到的数据会保存到一个日志文件中去(HDFS), 将接收数据的持久化,此外,如果只有在数据写入到log中之后接收器才向数据源确认,这样drive重启后那些保存在内存中但是没有写入到log中的数据将会重新发送。
以上两点保证了数据的不丢失。
补充:可靠的数据源和不可靠的数据源
可靠的数据源:利用kafka保证数据在存储至hdfs上之前不丢失。
不可靠的数据源:数据在写入hdfs时出错丢失。
WAL利用的就是可靠的数据源。
Streaming中WAL原理*
首先client端(Flume或Kafka)input stream到spark的executor中receiver,一部分数据通过容错写入HDFS(HDFS写成功后会发送AK给Kafka,更新ZK的offset),然后再写入receiver(receiver和hdfs会同时写,但是写入hdfs优先,会快一些)。写入内存的数据会被切分成一个个block data(每两秒切一个块),同时将切分的block id的metadata传给driver,再结合代码逻辑生成streamingcontext就可以开始运行了。driver端也有一个容错文件系统,传过来的代码逻辑metadata也会写入log(WAL机制)。
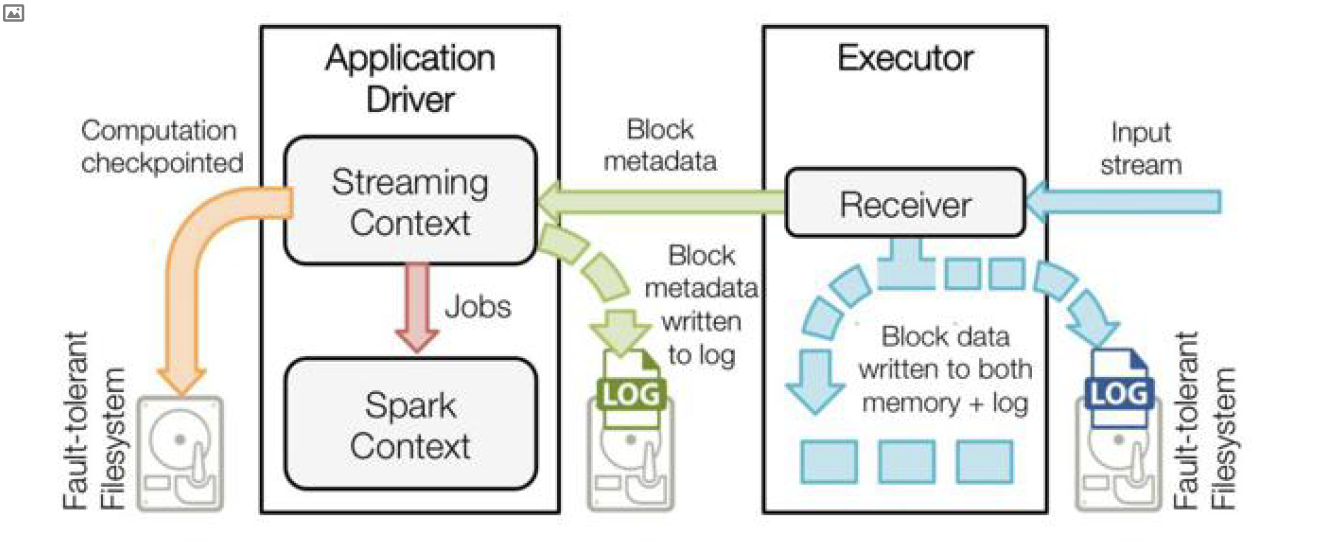
蓝色的箭头表示接收的数据
接收器把数据流打包成块,存储在 executor的内存中,如果开启了WAL,将会把数据写入到存在容错文件系统的日志文件中;
青色的箭头表示提醒 driver
接收到的数据块的元信息发送给 driver中的 Streaming Context,这些元数据包括: executor内存中数据块的引用ID和日志文件中数据块的偏移信息;
红色箭头表示处理数据
每一个批处理间隔, Streaming Context使用块信息用来生成RDD和jobs。 Sparkcontextf执行这些job用于处理 executor内存中的数据块;
黄色箭头表示 checkpoint这些计算
以便于恢复。流式处理会周期的被 checkpoint到文件中;
WAL下Driver失败重启流程*
首先,对于worker中的executor,将没处理的数据从文件系统进行恢复,切分成一个个Block块(根据时间进行RDD的切分)。
第二部分是要恢复代码逻辑和block元数据,代码逻辑由于每次执行都checkpoint了一次,那下一次执行的时候恢复到哪一步可以获取到,不用care以前执行的数据,只关心现在执行的数据,恢复还没有执行的数据,将这两部分数据放到Driver里,直接restart 它的StreamContext,就relaunch了jobs,jobs底层映射到SparkContext,启动RDD进行执行,底层就相当于走了批处理。
数据执行完过后,在executor或HDFS中将执行的块进行删除。
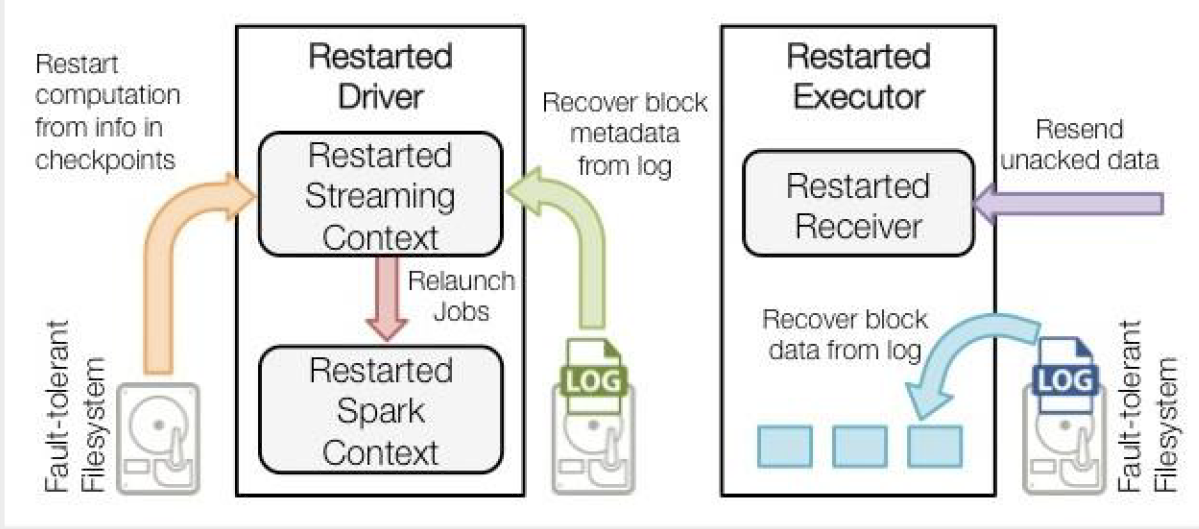
黄色的箭头用于恢复计算:
checkpointed的信息是用于重启driver,重新构造上下文和重启所有的receiver
青色箭头恢复块元数据信息:
所有的块信息对已恢复计算很重要
红色箭头重新生成未完成的job:
会使用到恢复的元数据信息
蓝色箭头读取保存在日志中的块:
当job重新执行的时候,块数据将会直接从日志中读取
紫色的箭头重发没有确认的数据:
缓冲的数据没有写到WAL中去将会被重新发送。
关于WAL中突发的情况
情况1:worker挂掉
Driver节点会将操作日志文件checkpoint到HDFS中。首先kafka来的数据会先写入HDFS,写入成功后会更新ZK的offset,数据在写入HDFS的同时也会写入Receiver,如果此时Receiver(Worker节点挂掉)挂掉了,会另外重新启动一个worker节点,将预写到HDFS的数据传给新的executor。
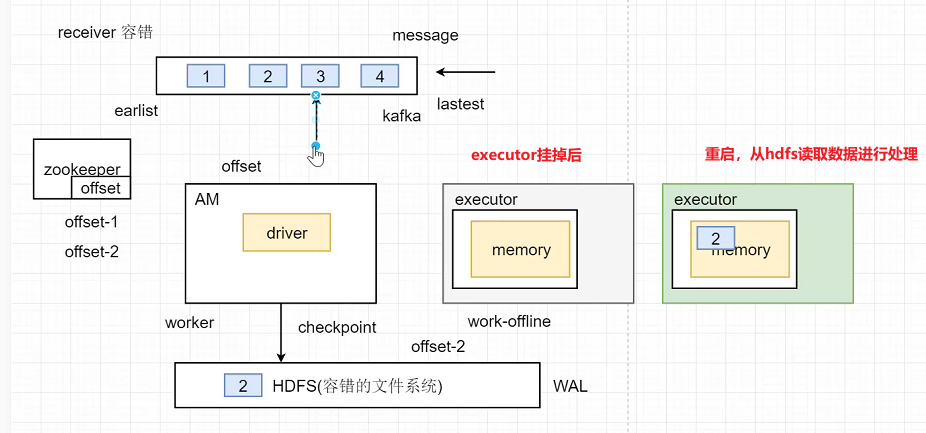
情况2:WAL未成功
假如Kafka的数据写入WAL未成功,因为没成功所以ZK的offset也没更新,此时会拿着原来的offset重新去Kafka预写数据。
情况2:Driver挂掉了
Driver端进行Streaming处理时,可能保存的是DStream相关信息,会将其checkpoint到hdfs。假设Driver在处理过程中处理到一半发生异常,发生异常时,如果进行了checkpoint,则可以从checkpoint进行恢复。假设Driver挂掉,下个节点Driver启动时可以从HDFS读取上个节点Driver的checkpoint日志记录,重新启动。
注意:
WAL保存的是操作日志而非具体的数据。比如对数据的增删改查,记录的是操作日志,可以类似mysql的操作日志去理解。
关于WAL的补充
WAL只是针对receiver才有。
Driver在AM中。Driver可以与Executor在同一节点上,也可以不在。
Direct Approach将容错交给了Kafka。
WAL先写HDFS,再写Executor,即hdfs写入的数据比executor要快一步,如果hdfs数据写入失败,那么executor写数据也会失败。
executor拉取数据写入hdfs完成后,再给receiver使用。
Streaming采取Direct的容错情况
由于Direct依靠的是Kafka自身的容错机制来实现容错,所以就没有了WAL机制。
在Direct方式,操作的是offset range,offset range包含了开始的offset到结束offser组成的区间。offset range不关心起始offset,关注的是结束的offset。知道offset是从哪里结束,下次直接从结束的位置开始读取。
将offset range当作block id即元数据信息传递给Driver,生产执行任务。
假设offset range是(1, 2),会将对于offset1,2的数据载入到executor内存中去,直接进行处理,之后再更新offset range中的end对应的offset到ZK里。当然,不仅仅通过ZK来保存offset(因为zk的节点有限),也可以通过redis或者mysql来保存offset的信息。

情况1:worker挂掉
如果读取的数据到executor上未处理好该节点就挂掉了,那么offset就不会被更新,将会重新读取数据进行处理。
Streaming接受消费Kafka数据的两种方式**
Receiver
1.Receiver-based Approach:offset存储在zookeeper,由Receiver维护,Spark获取数据存入executor中,调用的是Kafka高阶API,来更新offset;
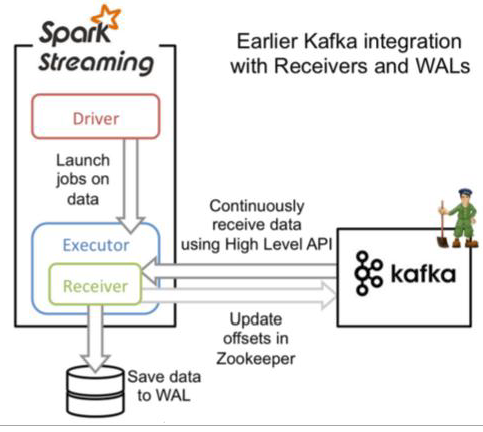
Receiver数据丢失原因
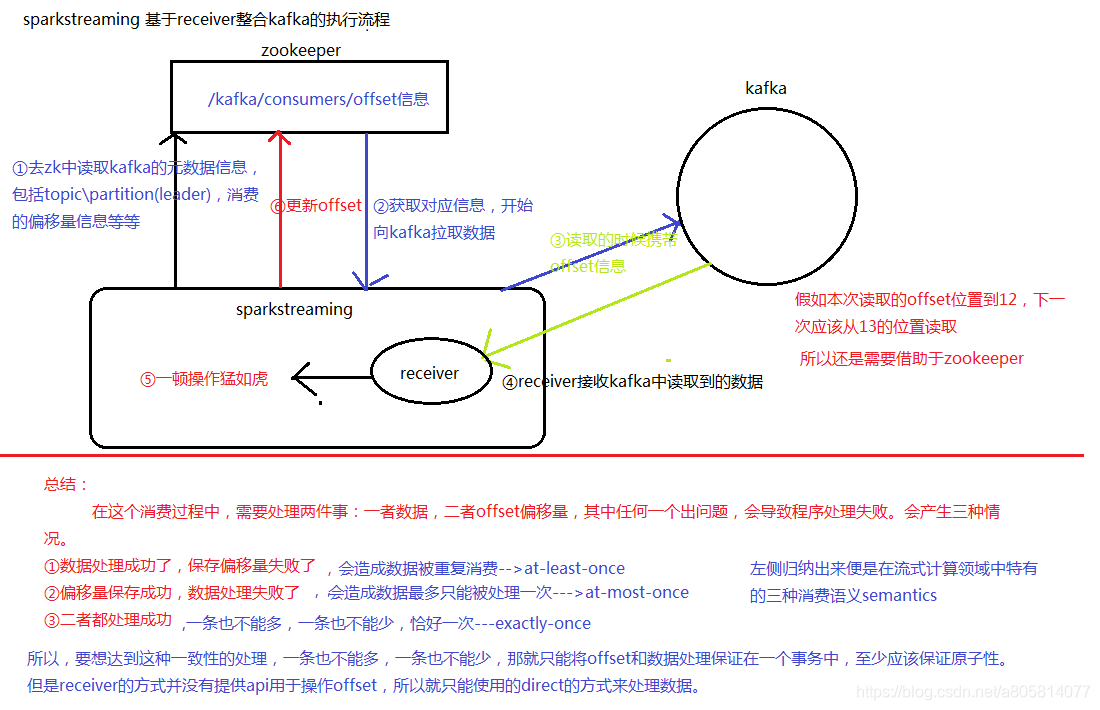
注意点1
- Kafka的topic分区和Spark Streaming中生成的RDD分区没有关系。 在KafkaUtils.createStream中增加分区数量只会增加单个receiver的线程数,不会增加Spark的并行度;
- 可以创建多个的Kafka的输入DStream, 使用不同的group和topic, 使用多个receiver并行接收数据。
- 如果启用了HDFS等有容错的存储系统,并且启用了写入日志,则接收到的数据已经被复制到日志中。因此,输入流的存储级别设置StorageLevel.MEMORY_AND_DISK_SER(即使用KafkaUtils.createStream(…,StorageLevel.MEMORY_AND_DISK_SER))的存储级别。
Direct
2.Direct Approach (No Receivers):offset自己存储和维护,由Spark维护,且可以从每个分区读取数据,调用的是Kafka的低阶API;
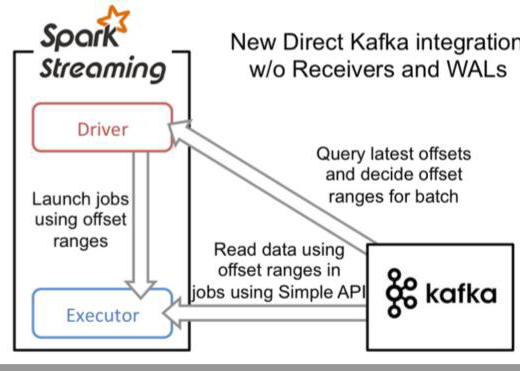
Streaming on Kafka Direct
1.Direct的方式是会直接操作kafka底层的元数据信息。
2.由于直接操作的是kafka,kafka就相当于底层的文件系统(对应receiver的executor内存)。
3.由于底层是直接读数据,没有所谓的Receiver,直接是周期性(Batch Intervel)的查询kafka,处理数据的时候,我们会使用基于kafka原生的Consumer api来获取kafka中特定范围(offset范围)中的数据。
4.读取多个kafka partition,Spark也会创建RDD的partition ,这个时候RDD的partition和kafka的partition是一致的。
5.不需要开启wal机制,从数据零丢失的角度来看,极大的提升了效率,还至少能节省一倍的磁盘空间。从kafka获取数据,比从hdfs获取数据,因为zero copy的方式,速度肯定更快。
Streaming on Kafka Direct 与 Receiver的对比
从容错角度
Receiver(高层次的消费者API)
在失败的情况下,有些数据很有可能会被处理不止一次。 接收到的数据被可靠地保存到WAL中,但是还没有来得及更新Zookeeper中Kafka偏移量。导致数据不一致性:
Streaming知道数据被接收,但Kafka认为数据还没被接收。这样系统恢复正常时,Kafka会再一次发送这些数据。at least once;
Direct(低层次消费者API)
给出每个batch区间需要读取的偏移量位置,每个batch的Job被运行时,对应偏移量的数据从Kafka拉取,偏移量信息也被可靠地存储(checkpoint),在从失败中恢复可以直接读取这些偏移量信息。exactly once;
Direct API消除了需要使用WAL的Receivers的情况,而且确保每个Kafka记录仅被接收一次并被高效地接收。这就使得我们可以将Spark Streaming和Kafka很好地整合在一起。总体来说,这些特性使得流处理管道拥有高容错性,高效性,而且很容易地被使用。
Receiver和Direct如何选择?
spark中RDD的partition和kafka的partition是一致的,强一致性
采用receriver方式,从kafka读取Partition数据到executor内存中,通过Task执行作业。
采用direct方式,三个partition直接对应启动3个task执行。
总结两者区别,receiver方式特点就是读取入内存的数据并不是一个RDD,可以对数据切分成多个RDD,能够启动很多个task进行消费。也可以启动多个进程,每个进程里有多个线程,这样每次处理的数据量就能够得到提升。
对于direct方式,由于parttion和task一一对应,每个线程去消费数据没那么快,导致消费跟不上,会出现数据堆积。若出现消费跟不上,采用receiver方式可以增加进程和线程,达到消费能力的提升,不会出现数据堆积情况,增加了并行度计算。
direct方式适合数据量不多,业务不复杂的情况。在业务高峰期不适合用direct方式。但是使用receiver,在大量数据情况下可能容易出错,导致WAL机制消耗大量的资源,损耗性能。所以使用receiver前提要求程序稳定(鲁棒性强),机器稳定,性能强。
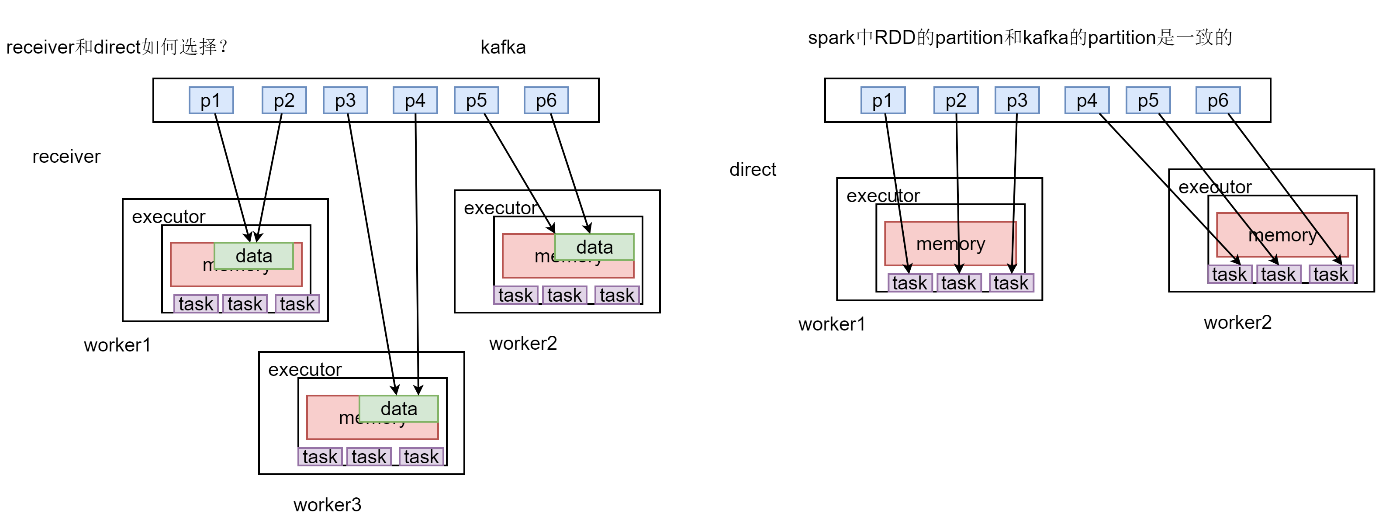
receiver优点:
通过增加进程或者线程的方式提高数据的处理量,减少数据的堆积,提高并行计算的能力
receiver缺点:
如果代码健壮性和机器稳定性存在问题,会出现WAL,会消耗较多的性能
direct优点:
没有WAL机制,数据直接读取kafka,如果业务逻辑不复杂,数据量不大,direct方式也能正常处理数据
direct缺点:
如果出现业务/流量高峰期,梳理数据不会很及时,会产生数据堆积的情况
实践
1 | package SparkStreamingTset |
案例2 运行streaming源码(HDFSWordCount)
参考链接
1. https://blog.csdn.net/a805814077/article/details/106531020 ↩



