
大数据技术之即席查询——Kylin
Kylin即席查询
Kylin简介
即席查詢
即席查詢,區別于數倉中一些固定的查詢抽數脚本工作流程,它是一個不固定,不斷探索的過程,从数据中探索有价值的信息,对查询引擎的响应速度有高的要求,力求做到交互式。
Kylin定義
Apache Kylin是一个开源的分布式分析引擎,是为数仓服务的一种工具,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
前置概念补充
DataWarehouse[数据仓库]
数据仓库是一个各种数据(包括历史数据[纵向看]和公司各部门数据[横向看])的中心存储系统,是BI(business intelligence商业智能)的核心部件。
这里所谈的数据包括来自企业业务系统的订单、库存、交易账目、客户和供应商等来自企业所处行业和竟争对手的数据以及来自企业所处的其他外部环境中的各种数据。
Businesses Intelligence[商业智能]
商业智能通常被理解为将企业中现有的数据转化为知识,帮助企业做出明智的业务经营決策的工具。
为了将数据转化为知识,需要利用教据仓库、联机分析处理(OLAP)工具和数据挖掘等技术。
OLAP[Online Analytical Processing]
OLAP( online analytical processing)是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。从方面观察信息,也就是从不同的维度分析数据,因此OLAP也称为多维分析。
多维角度如何定义呢?就看有多少个维度个数,有n个维度个数,则角度有$2^{n} - 1$。
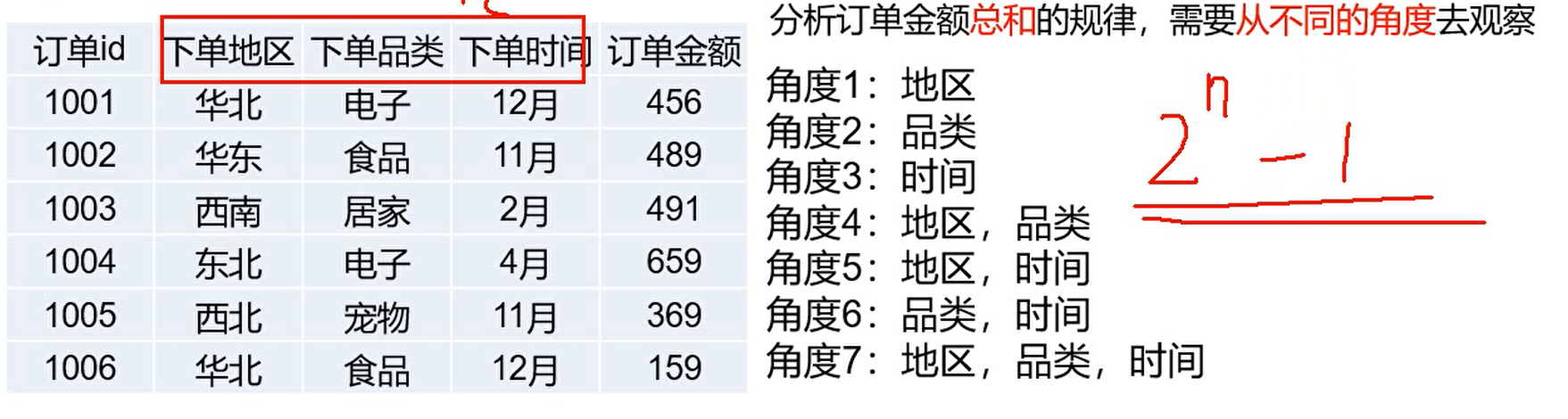
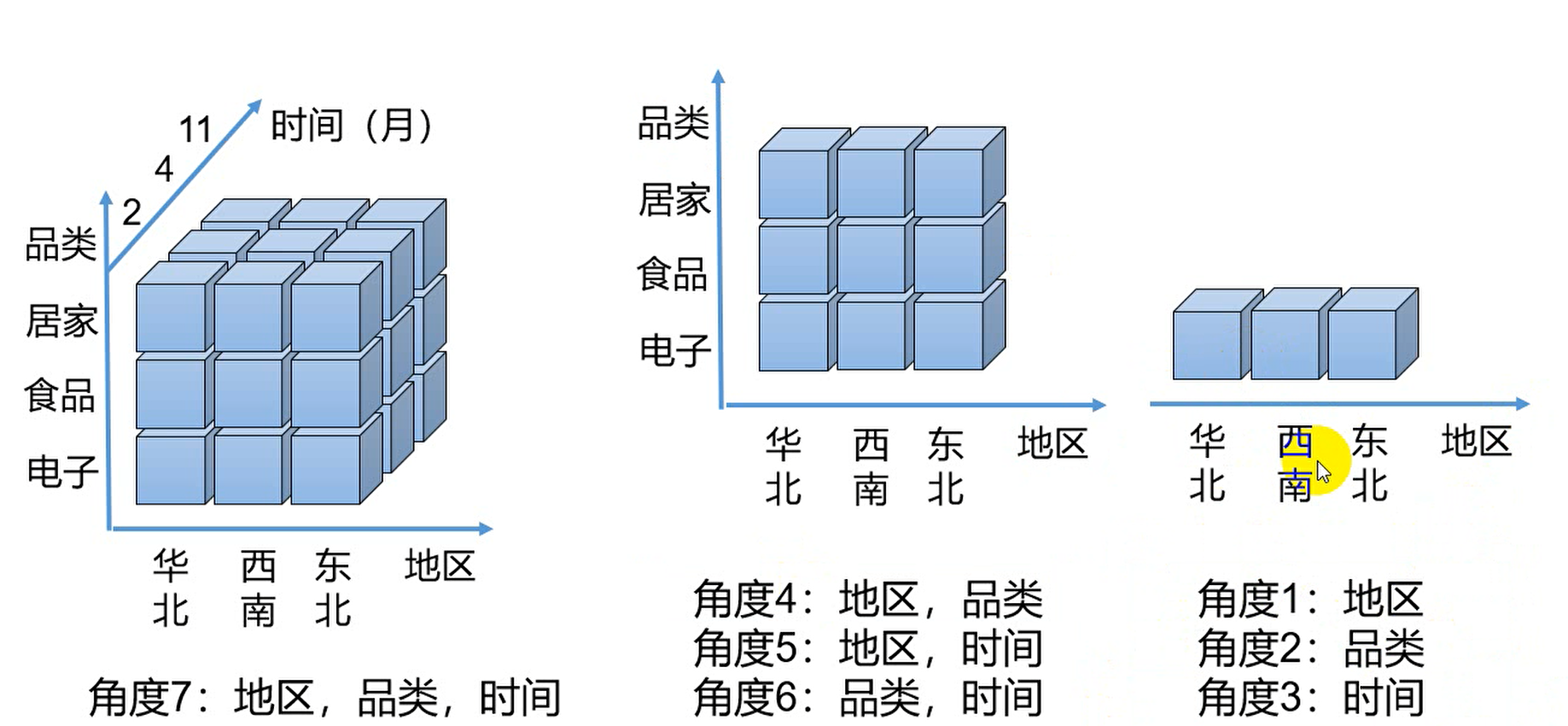
多维分析做法一般都是按照维度字段进行分组,按照度量值字段进行聚合。
OLAP类型
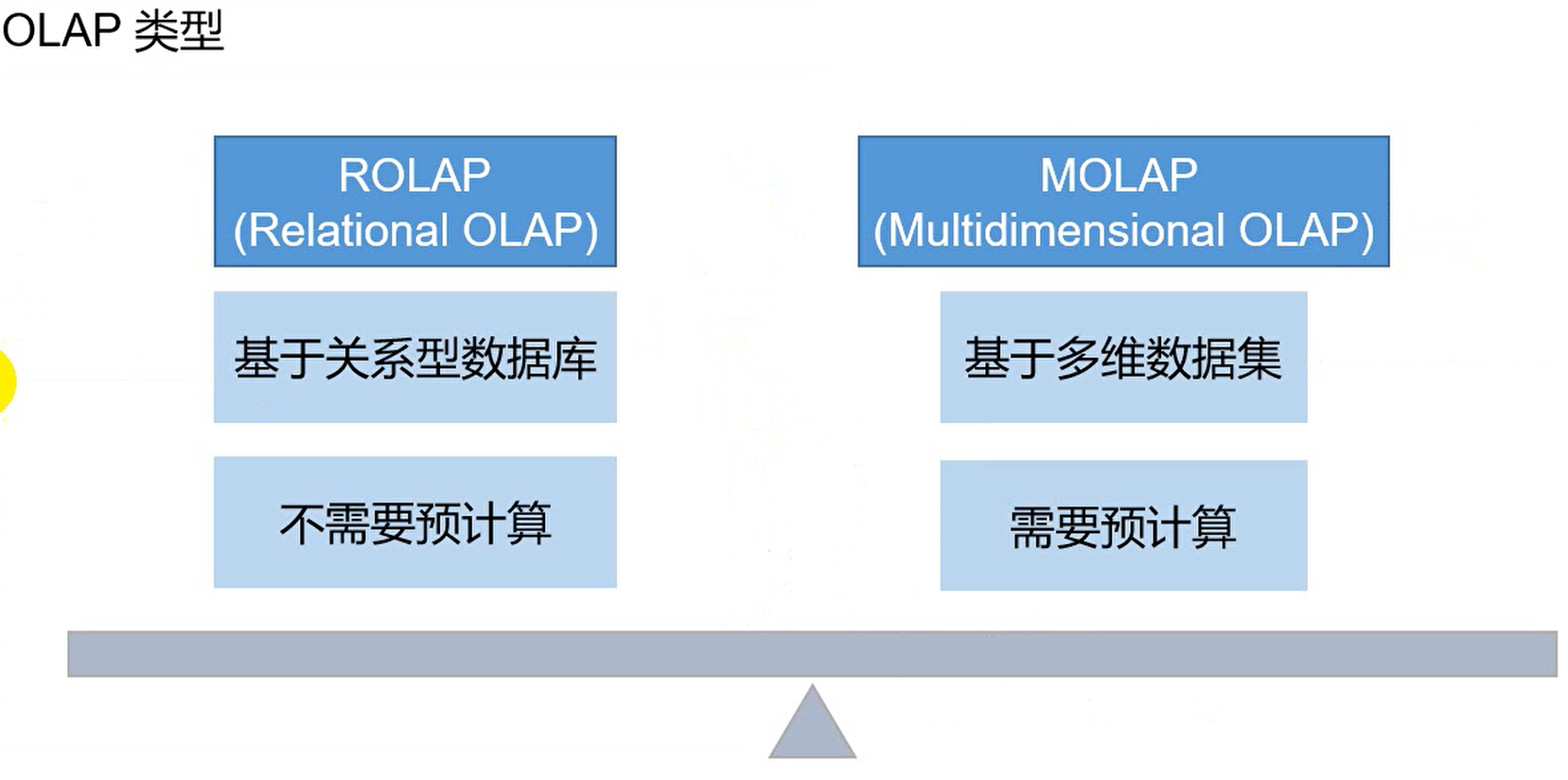
ROLAP
简单来说,就是数据存储在关系型数据库中,进行分析时不需要预计算。预计算即提前计算,在发出sql请求之前进行计算。像hive执行sql,是在发出sql请求之后才开始执行计算,不算预计算。
MOLAP
基于多维数据集,需要进行预计算。
OLAP CUBE
MOLAP基于多维数据集,一个多维数据集称为ー个 OLAP Cube。
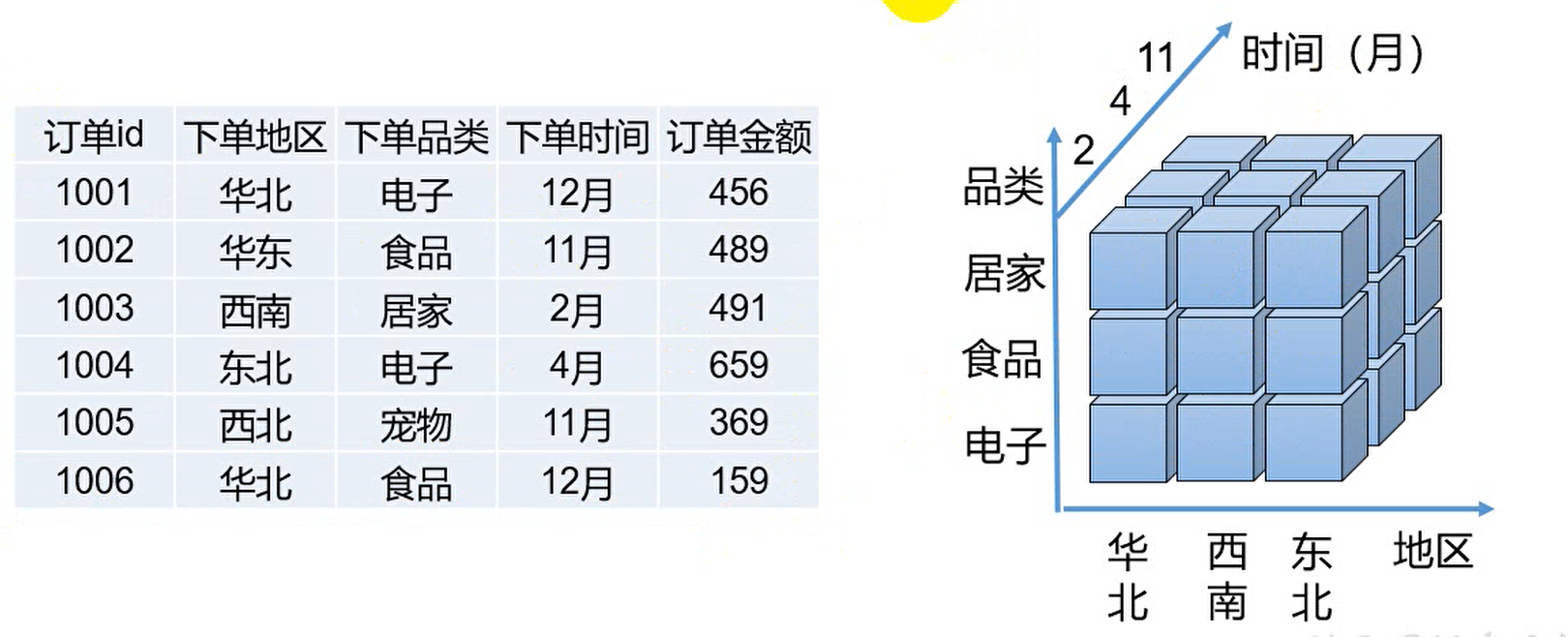
在上图中的立方体小块中,一个小块就对应表里的多条数据,而这些立方体中的多条数据是提前做好聚合计算的,即预计算,当我们把最原始的明细数据放在多维数据集的一个过程就是预计算。
我们在往多维数据集存放的数据,是按照分析的角度去进行聚合的,且分析的角度是可以穷举出来的,按照穷举出来的分析角度将原始数据聚合处理好,后续分析时即可快速取出所需数据,做到不管查询数据集有多大,由于做过预处理,能够很快的相应出分析结果数据。
Kylin的预计算执行引擎是基于Hadoop的MR和Spark的RDD。即前面提到的Hadoop/Spark之上的SQL查询接口。目前Kylin也支持Flink的接口。
在计算的时候,可以先计算最高维度,然后依次进行维度压缩,就能得到其他较低维度的数据,不用每次都从原始明细数据去计算。
CUBE&CUBOID
cuboid是单一分析角度,所有分析角度的集合才称为cube。
Star Schema
Kylin对接的就是维度模型。
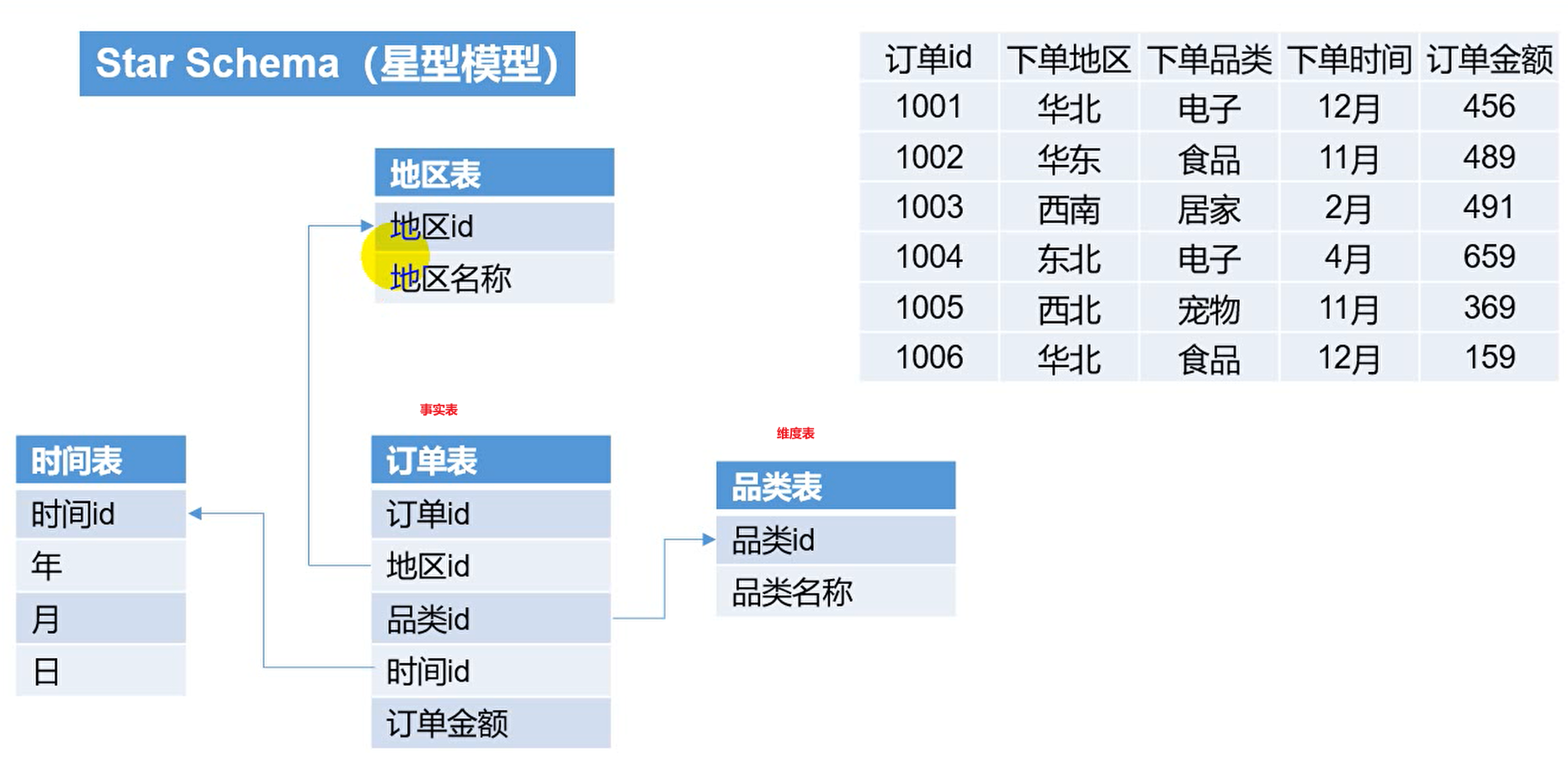
维度和度量
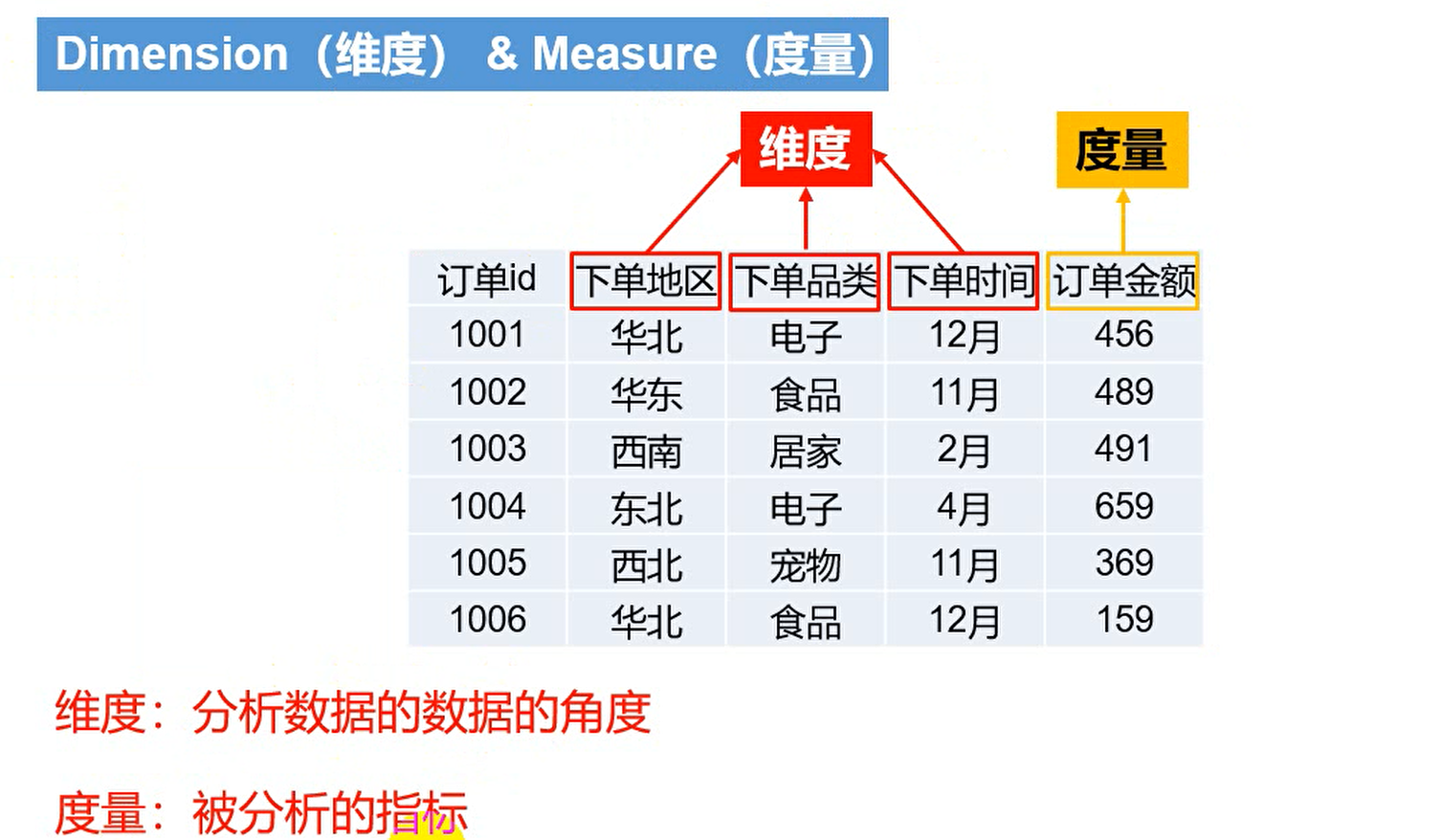
Kylin原理
Kylin架构
Kylin分为三层,下两层称为计算层,中间层称为路由层,最上层称为查询层。
计算层
构建cube的过程就是计算的过程。Kylin计算cube的数据源既可以是离线的也可以是实时的,计算完后的结果存储在HBase中。
Kylin选择Hbase有以下原因:
- Kylin需要进行预计算,预计算穷举结果数据量会很大,所以存储系统的扩展性得好,能够保证随着维度的增加和数据量的增大,依然能够很好对结果数据进行存储。Hbase即符合这个特性,一张表可以不断进行分裂成多个region,多个region可以横向的分布在不同的region server里面,底层依靠的是HDFS分布式存储系统,扩展性好;
- 后期查询延迟要低,Hbase有多个特性能够优化查询的速度,比如最底层存储文件HFile的存储结构块和索引,能够加速查询。还有布隆过滤器,以及rowkey是有序的能够快速定位数据等。
查询层
REST Server
REST Server是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等。另外可以通过Restful接口实现SQL查询。
REST Server提供数据接口服务。通过访问一个数据库地址,然后返回响应,响应的数据格式一般都是json。Kylin对这些数据接口进行了封装,即可任意直接通过web访问数据,也可以通过java的JDBC或者C的ODBC去访问数据,两者都会访问REST服务,即接受请求返回数据。
Query Engine
当cube准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。
不管通过什么方式去访问Kylin,都需要传递SQL查询语句,查询引擎层通过解析SQL为Hbase的语言去查询数据得到结果然后通过REST服务层将数据响应出去。
路由层
由于Kylin是对多维分析进行预计算,有时候的SQL语句过于复杂,所需的数据并没有存储在Hbase中,在这种情况下,Kylin就会通过路由层将复杂的SQL语句传给Hive去进行查询。这样做会导致Kylin查询的性能不是很稳定,影响顶层系统设计,因此Kylin的路由层基本上是关闭了的,一旦出现复杂的SQL语句,到Hbase中查询不到结果,Kylin会直接返回空。即通过Kylin查询的数据最好都是聚合之后的结果,直接SELECT *是查询不到数据的额。
计算层
MetaData
Kylin是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin的元数据存储在hbase中。
任务引擎(Cube Build Engine)
这套引擎的设计目的在于处理所有离线任务,其中包括shell脚本、Java API以及Map Reduce任务等等。任务引擎对Kylin当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
Kylin特点
Kylin的主要特点包括支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等。
- 标准SQL接口:Kylin是以标准的SQL作为对外服务的接口。
- 支持超大数据集:Kylin对于大数据的支撑能力可能是目前所有技术中最为领先的。早在2015年eBay的生产环境中就能支持百亿记录的秒级查询,之后在移动的应用场景中又有了千亿记录秒级查询的案例。
- 亚秒级响应:Kylin拥有优异的查询相应速度,这点得益于预计算,很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需的计算量,提高了响应速度。
- 可伸缩性和高吞吐率:单节点Kylin可实现每秒70个查询,还可以搭建Kylin的集群。
- BI工具集成
Kylin可以与现有的BI工具集成,具体包括如下内容:
- ODBC:与Tableau、Excel、PowerBI等工具集成
- JDBC:与Saiku、BIRT等Java工具集成
- RestAPI:与JavaScript、Web网页集成
Kylin开发团队还贡献了Zepplin的插件,也可以使用Zepplin来访问Kylin服务。
Kylin Cube存储原理
前面的介绍我们了解了Kylin Cube是存储在HBase上以实现亚秒级的响应。所以对于cube的存储我们重点关注在Hbase上的rowkey。
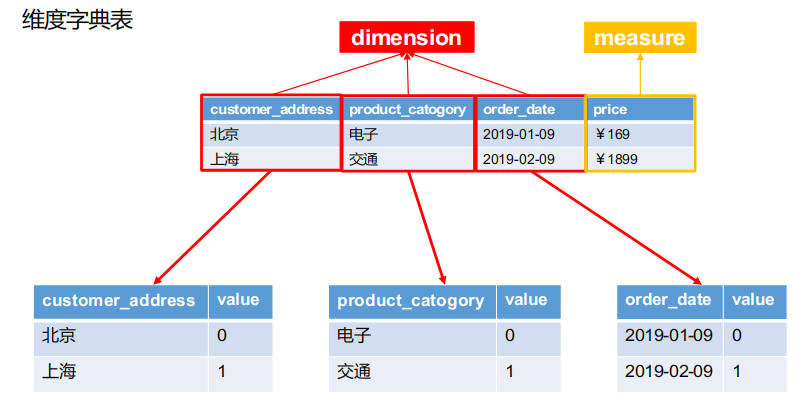
维度字典
中间那张表就是我们使用kylin进行cube构建时所选的维度和度量值,在kylin我们使用hbase去计算构建cube以及最终存储时并不会使用到维度里面真正的值。因为维度值可能会很长,影响计算速度同时也对Hbase存储造成一定压力,所以在计算和存储的时候会对维度值进行编码,经过一定编码的算法,转成int或其他形式。
这里的默认编码方式就是字典编码,将维度值转成int整型表示。
HBase K-V
下图左边第一张表就是经过cube计算后的一个结果集合。第一行代表某地区某产品某具体时间的金额总和,第二行代表某地区某产品以时间维度聚合后的金额总和。即我们的结果集合既有多维度的记录,也有聚合部分维度的记录。图表展示的是文字形式,实际在Hbase中是以编码形式呈现的。
右边三表是对维度进行编码的形式,做下方表是对上表编码后存储在Hbase的形式。实际Hbase中每一个维度值都会有分隔符区分开,值都是以16进制进行存储。

Kylin Cube构建原理
有了维度跟度量,一个数据表或者数据模型上的所有字段就可以分类了,它们要么是维度,要么是度量(可以被聚合)。于是就有了根据维度和度量做预计算的Cube理论。
给定一个数据模型,我们可以对其上的所有维度进行聚合,对于N个维度来说,组合`的所有可能性共有2n种。对于每一种维度的组合,将度量值做聚合计算,然后将结果保存为一个物化视图,称为Cuboid。所有维度组合的Cuboid作为一个整体,称为Cube。
下面举一个简单的例子说明,假设有一个电商的销售数据集,其中维度包括时间[time]、商品[item]、地区[location]和供应商[supplier],度量为销售额。那么所有维度的组合就有24 = 16种,如下图所示:(每个点的入度代表一个维度)
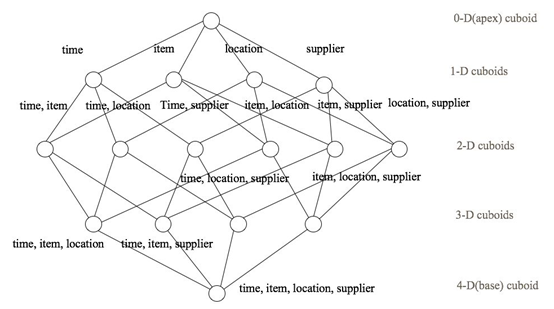
一维度(1D)的组合有:[time]、[item]、[location]和[supplier]4种;
二维度(2D)的组合有:[time, item]、[time, location]、[time, supplier]、[item, location]、[item, supplier]、[location, supplier]3种;
三维度(3D)的组合也有4种;
最后还有零维度(0D)和四维度(4D)各有一种,总共16种。
零维度即指的是所有度量值的聚合,结果是没有任何意义的一个值,所以我们一般都是用2的n次方-1个聚合维度组合。
注意:每一种维度组合就是一个Cuboid,16个Cuboid整体就是一个Cube。
我们可以在Kylin上查看构建好的cube:
Kylin Cube构建算法
逐层构建算法(layer)
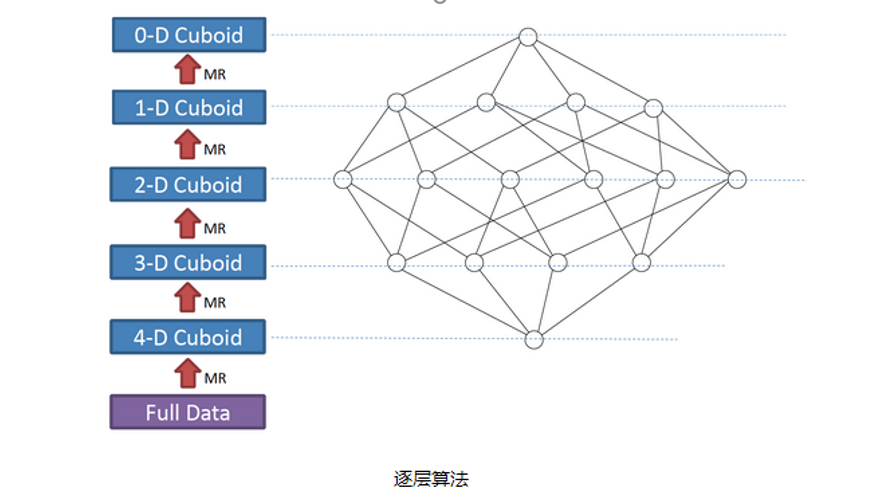
我们知道,一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、……、N个1维子立方体和1个0维子立方体构成,总共有2^N个子立方体组成,在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的。这样可以减少重复计算。当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
每一轮的计算都是一个MapReduce任务,且串行执行。一个N维的Cube,至少需要N次MapReduce Job,总体来看运算比较慢,但是稳定。
算法案例
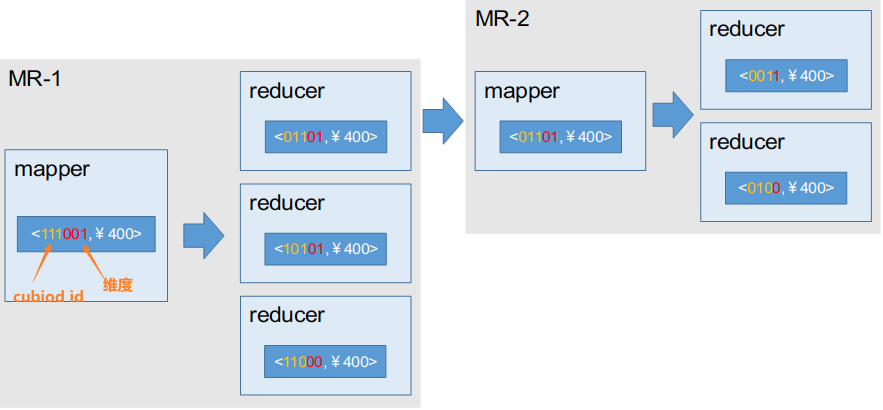
下面来讲讲具体的实现,首先,假设数据分析维度是三维,现在要计算二维的值,因此需要降维度。在MR里根据cuboid保证任意两个维度一致,然后根据维度值编码相同的去进行聚合。在MR里的实现是通过保证键一致,即维度+维度编码一致去进行聚合,只需要去掉第三个维度保证两个维度+对应维度编码一致,按此进行聚合即可。
接下去的降维也是按照此步骤进行,最后将结果存储在hdfs文件上,Hbase通过接口批量导入将hdfs文件转成hfile格式,然后存到对应表中,这样Hbase就能购识别表了。
快速构建算法(inmem)
快速构建算法也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从Kylin1.5.x开始引入该算法,该算法的主要思想是,每个Mapper将其所分配到的数据块,计算成一个完整的小Cube 段(包含所有Cuboid)。每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果。如图所示解释了此流程。
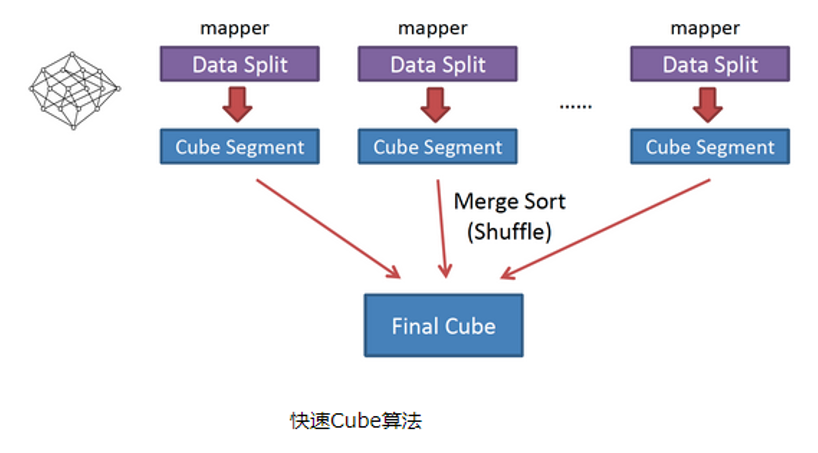
可以看到,该算法只经过了一次的MR即可得出Cube。在Map端进行了cuboid的聚合,也就是数据的降维,需要占用较大的内存空间。
算法案例
基快速构建算法和逐层构建算法基本思想一致,只不过快速构建算法是在内存中进行聚合的,按照key进行聚合,即一个map就包含了从最高维到最低维的所有的结果,最后将结果输出到reducer,去将不同map里相同的key值进行进一步的聚合。(因为在map端只是聚合了当前map里的同值key)。
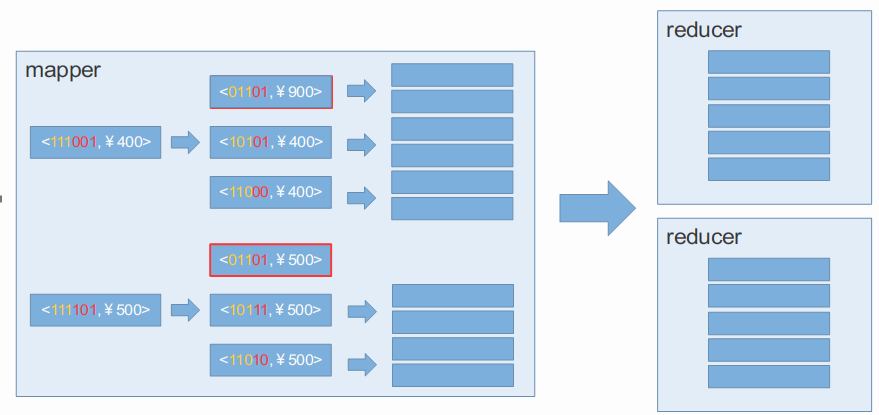
最后具体基于哪种算法需要根据集群空余资源和计算量,Kylin会自动根据集群选择合适的算法进行cube的构建。
Kylin使用
安装Kylin前需先部署好Hadoop、Hive、Zookeeper、HBase,并且需要在/etc/profile中配置以下环境变量HADOOP_HOME,HIVE_HOME,HBASE_HOME,记得source使其生效,同时还要对存在的一些依赖包不匹配问题进行处理。
安装完并配置好环境变量后进入kylin安装目录,运行bin/kylin.sh start即可启动kylin,首次登陆账户为ADMIN,密码为KYLIN。
如何给Kylin配置预计算规则
前面内容介绍过,Kylin需要进行预计算将所有结果穷举,要让Kylin去穷举,需要告诉Kylin计算的维度是啥,度量值是啥以及预计算的函数是啥,即计算的规则。
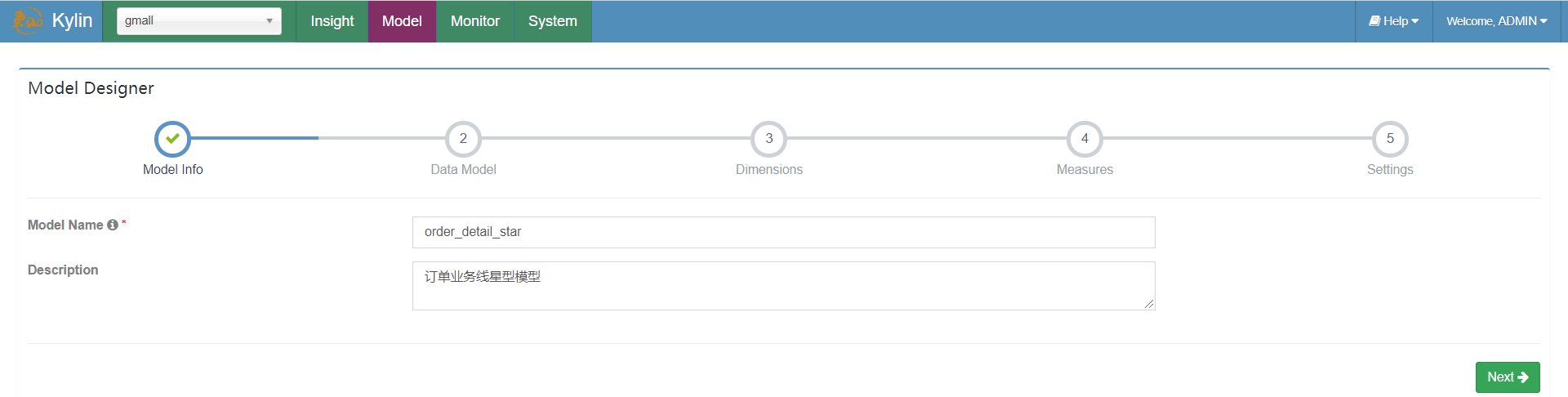
创建项目
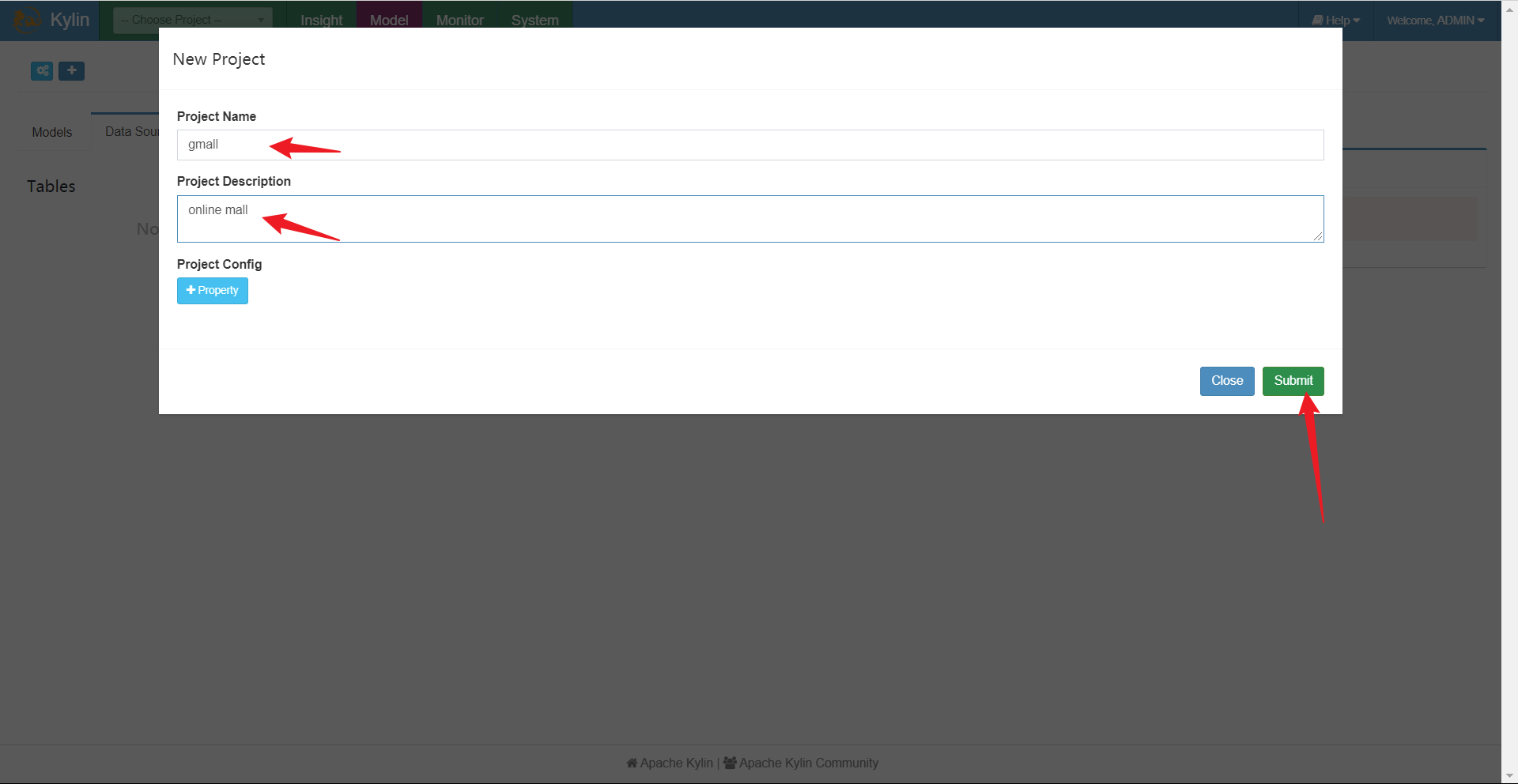
创建project后会自动跳转创建的项目,以后每次登陆kylin使用时都需要选择project。
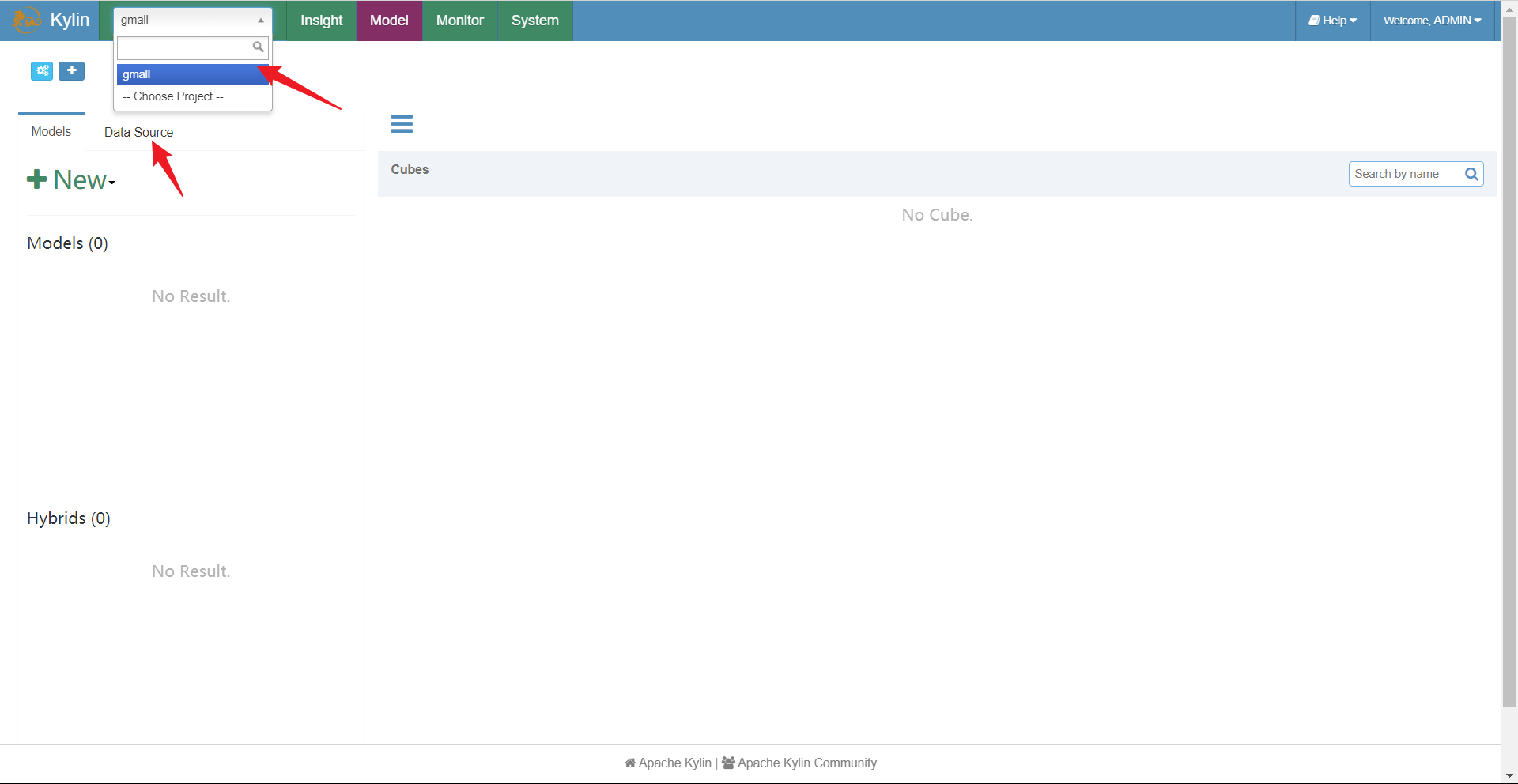
连接数据源
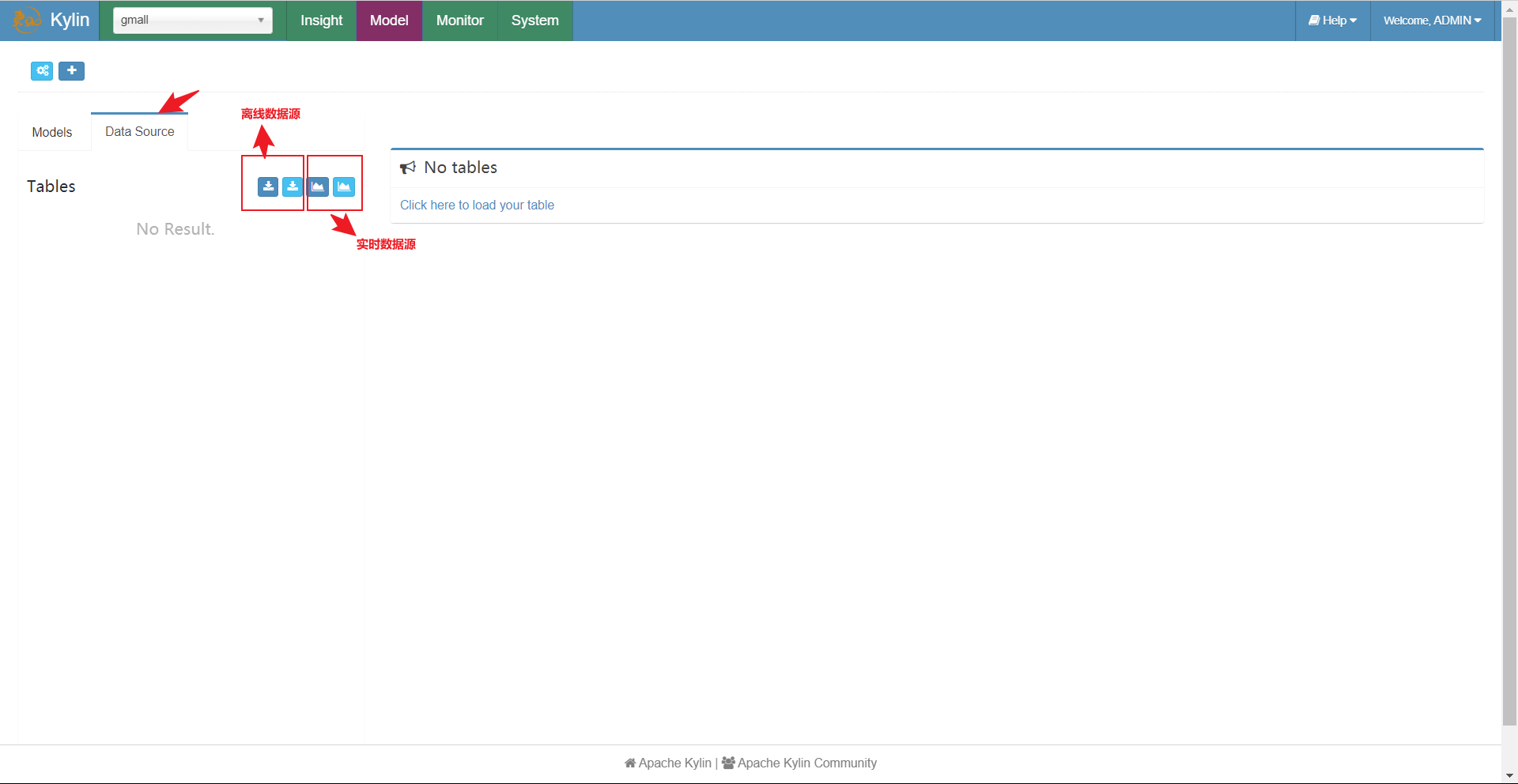
我们选择使用蓝色的LOAD TABLE FROM TREE它会自动可视化呈现数据库表,直接选择就好。如果选择左边的LOAD TABLE就需要手动输入要选择库表。

在选择Kylin对接的库表时要注意,Kylin对接的是维度模型,我们是在DWD进行的维度建模,所以我们选择使用dwd的库表来构建cube。在这里我们要注意,一个cube对应一个雪花或星型模型,一个星型模型对应一个事实表和多个维度表,一个事实表对应一个业务线。
因此,我们在使用的时候应该一个cube对应一个业务线,这里我们选择下单业务线。
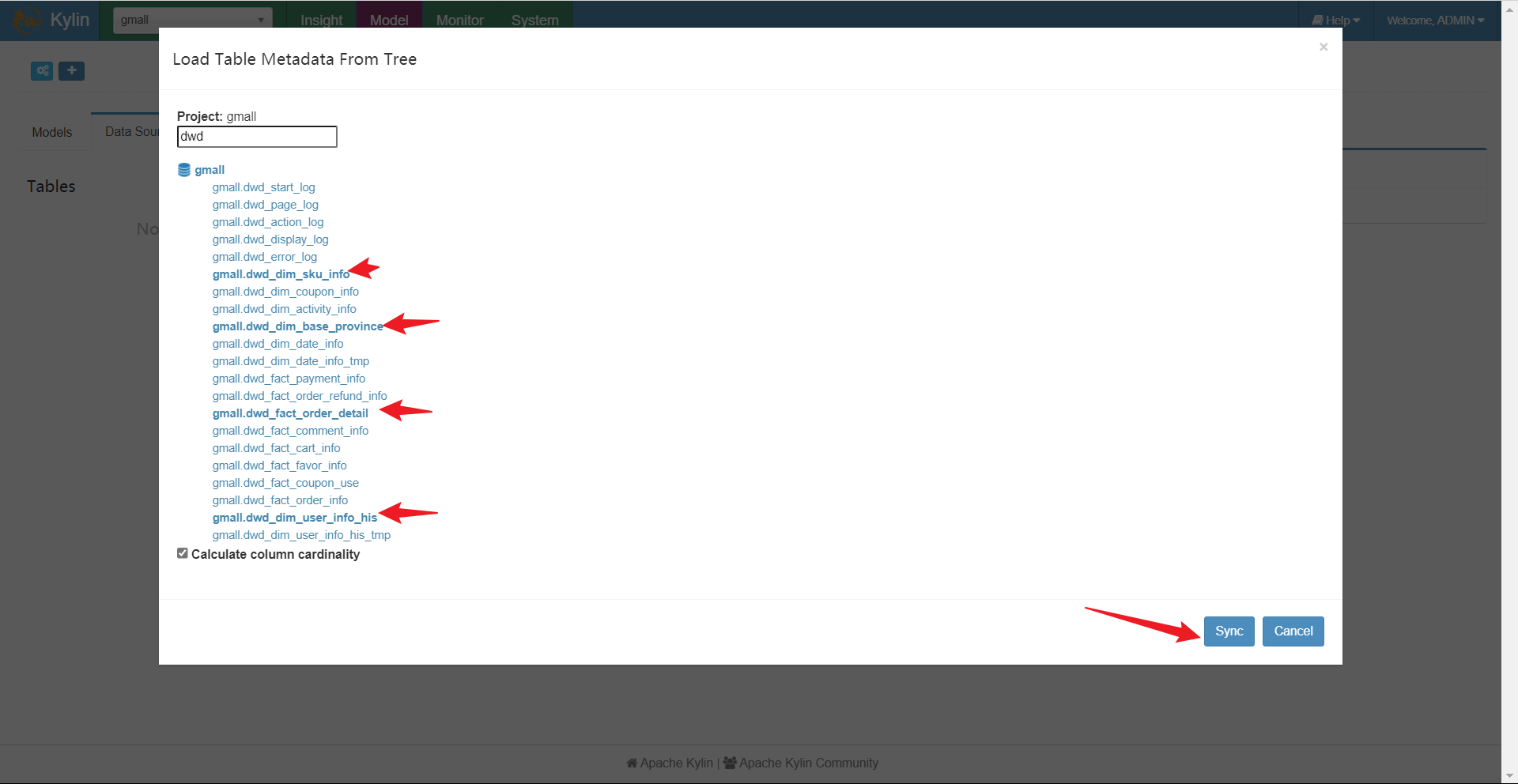
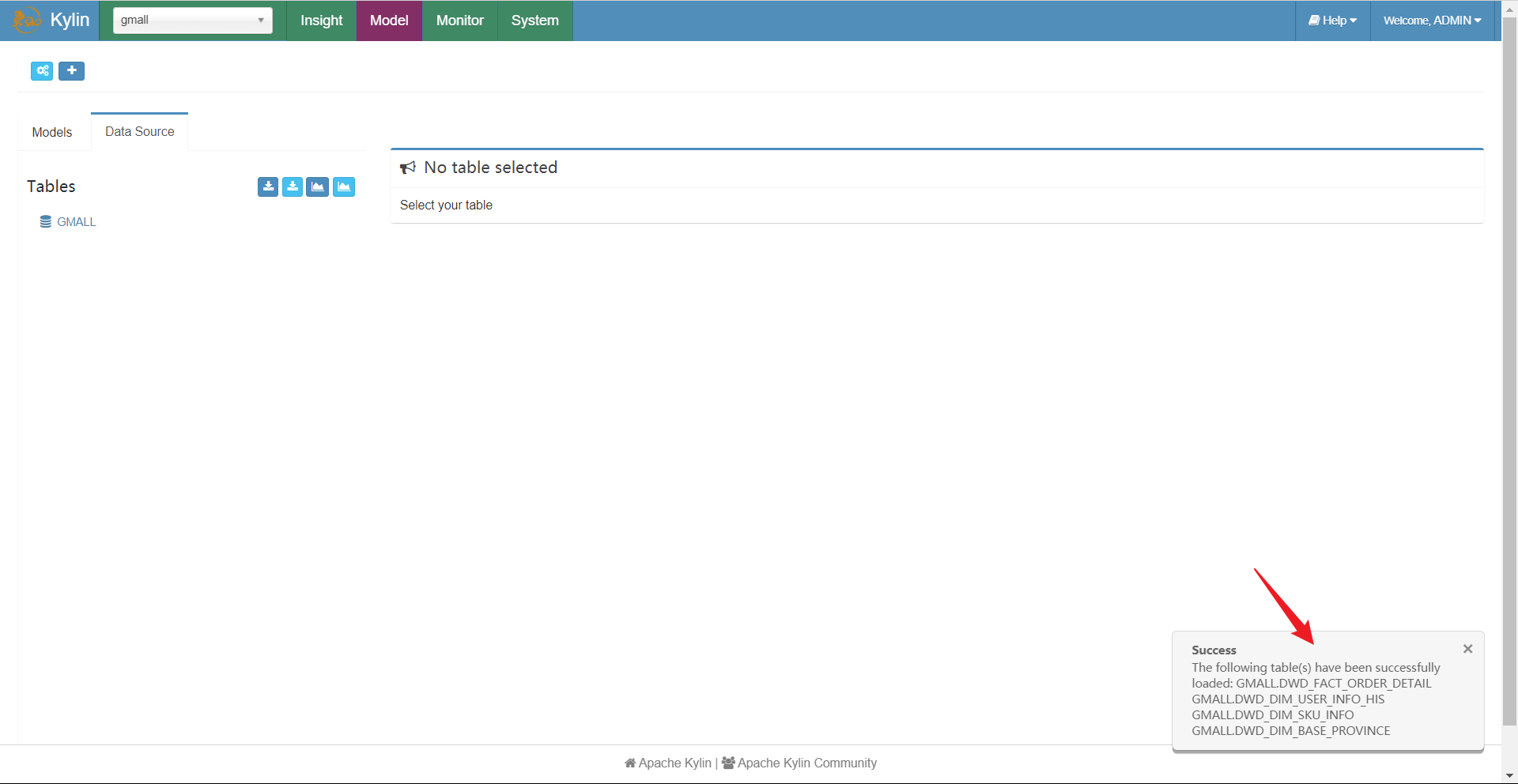
此时,我们就可以看到我们获取的表了。注意这里只是获取到了元数据!
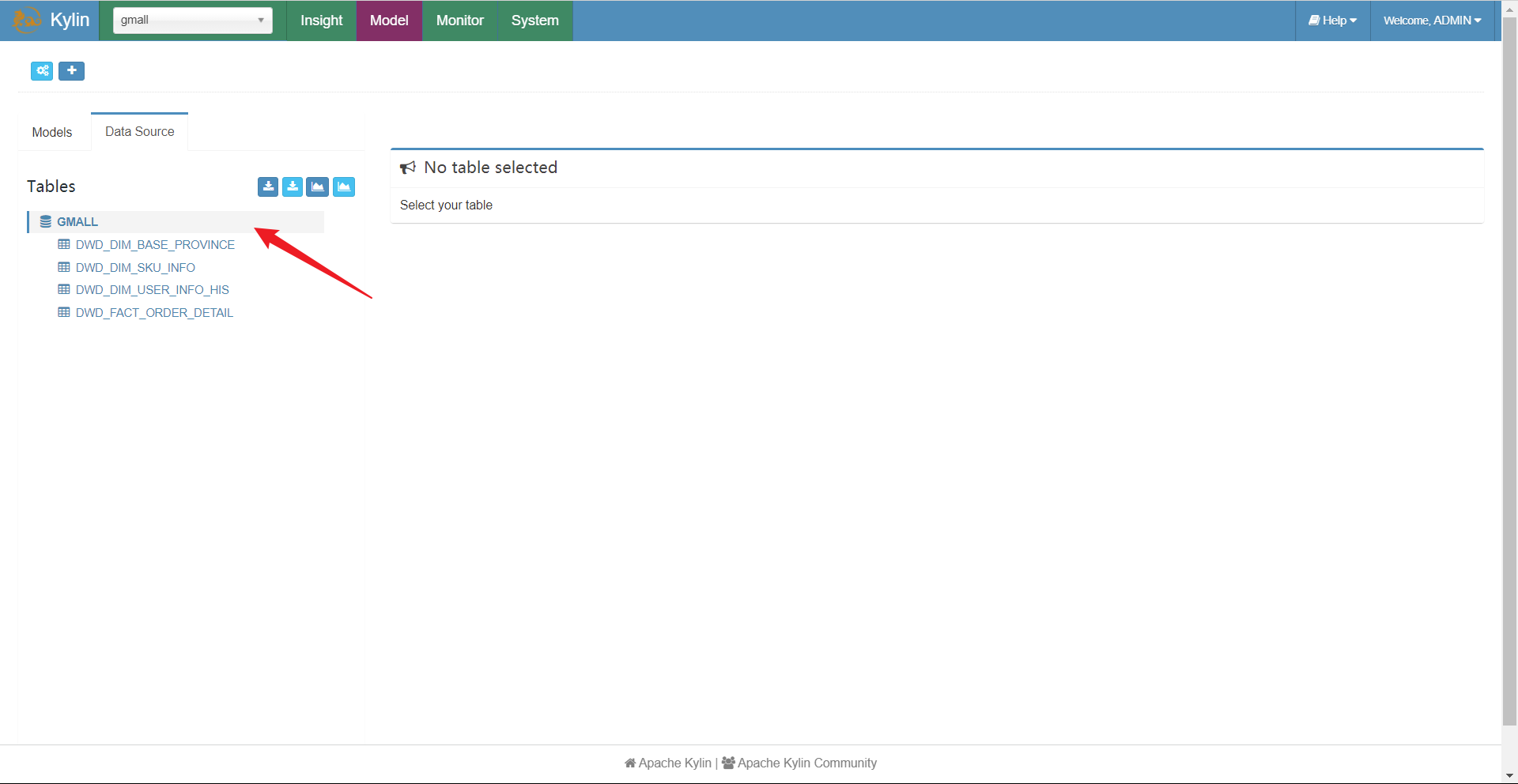
配置计算规则
在数据源连接完后,我们需要告诉Kylin哪张表是事实表,哪些是维度表,表与表之间是通过哪些字段join的
填充对应关系:
填充维度模型:
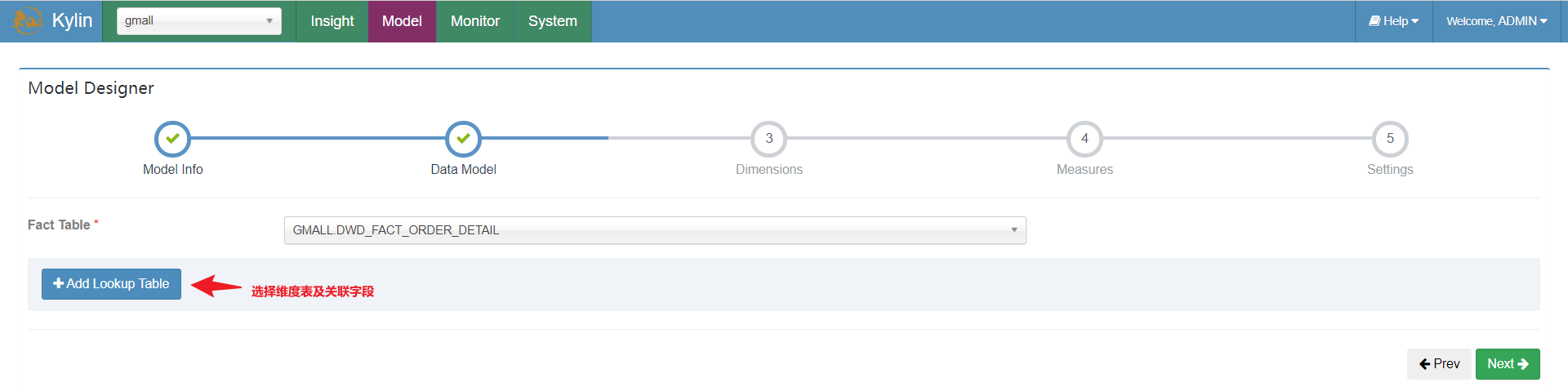
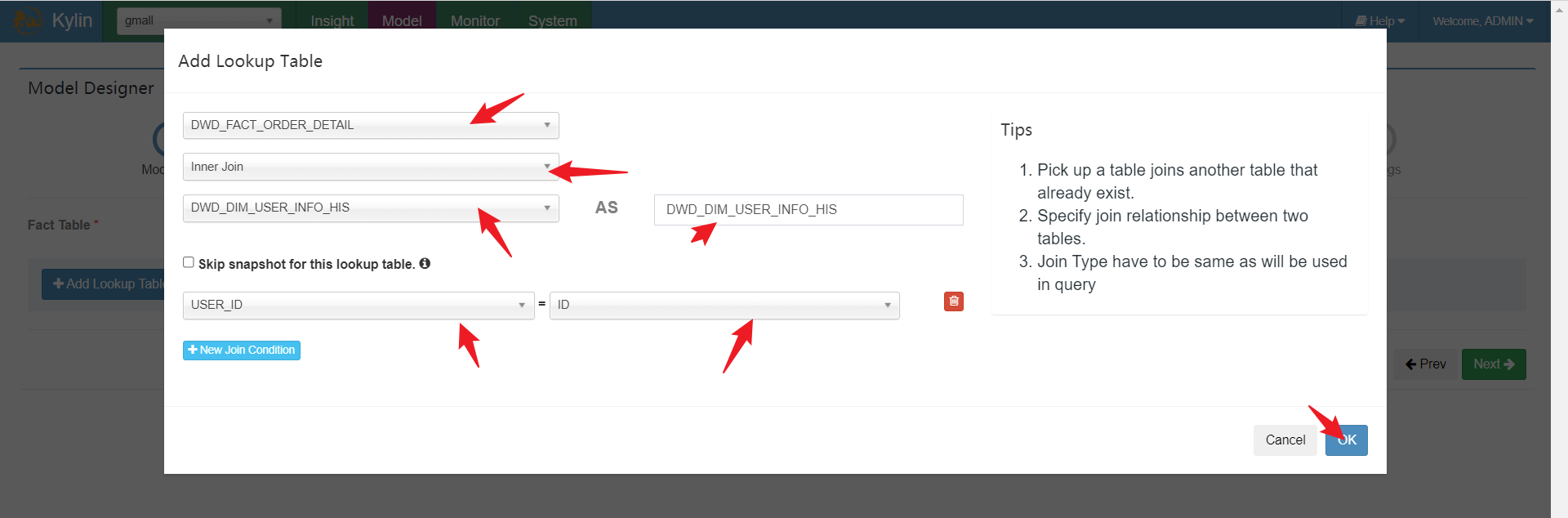
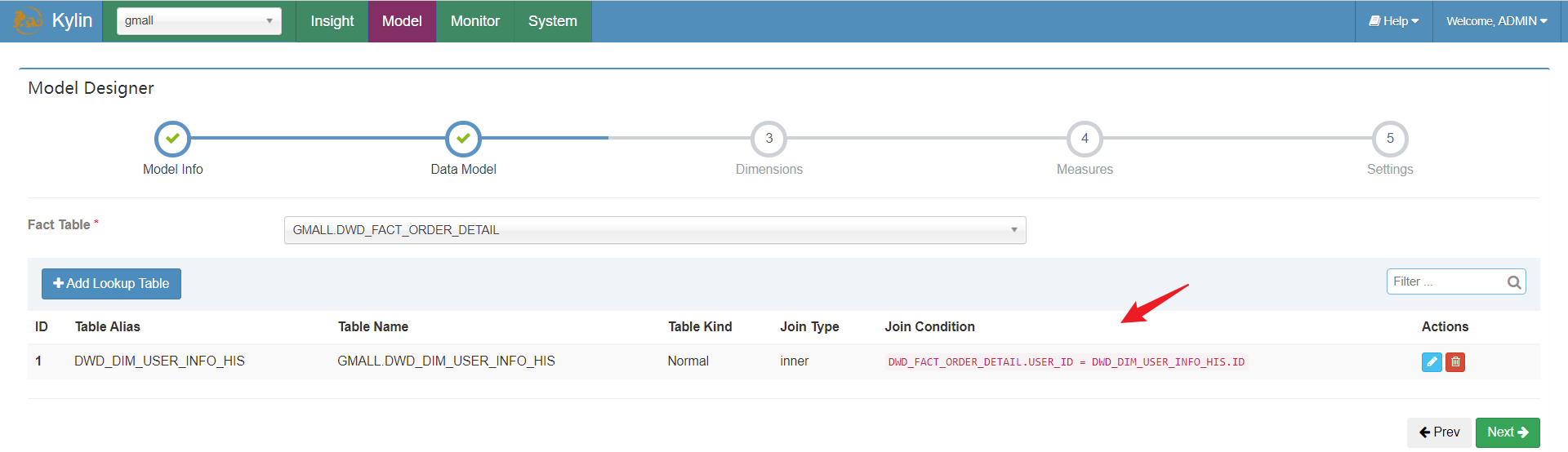
之后有多少个维度表,表之间如何join照着选即可。
选择维度字段:
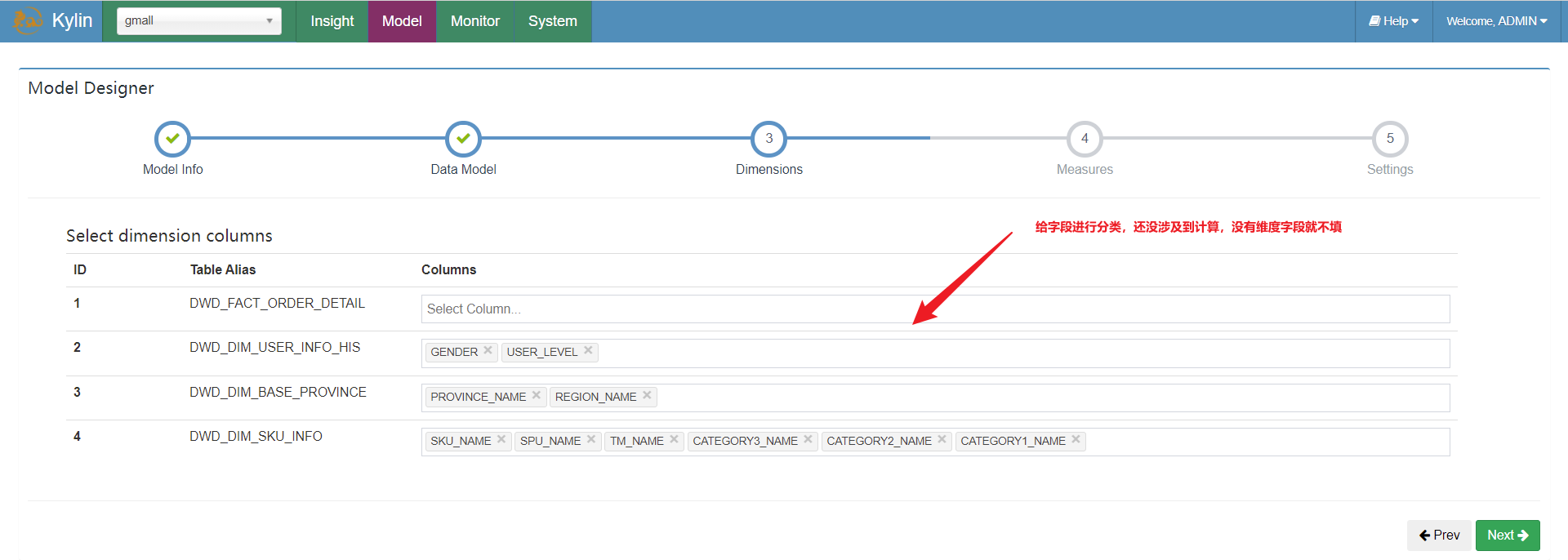
选择度量值字段:
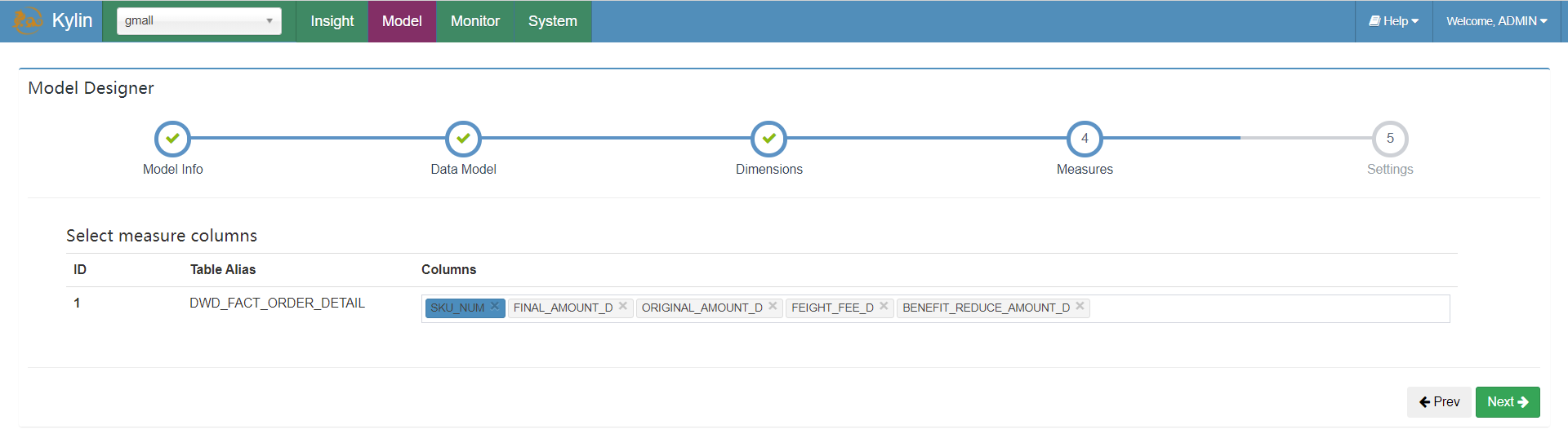
选择事实表的分区字段和过滤条件:
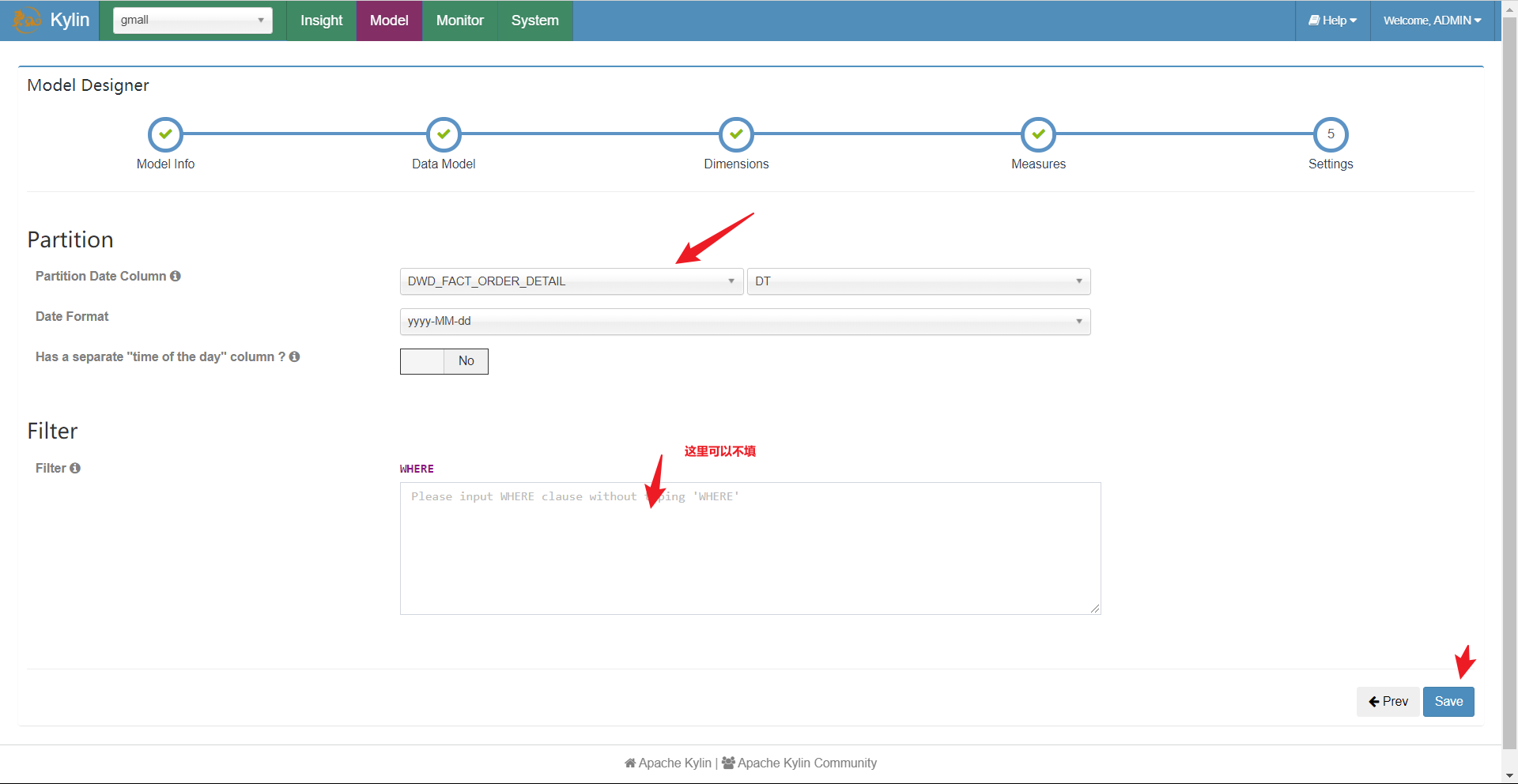
总结
到目前为止,,我们已经告诉Kylin哪张表是事实表,哪些是维度表,表与表之间是通过哪些字段join的了,下面需要告诉kylin聚合的维度,事实以及计算的函数。

定义计算规则
选择计算维度:
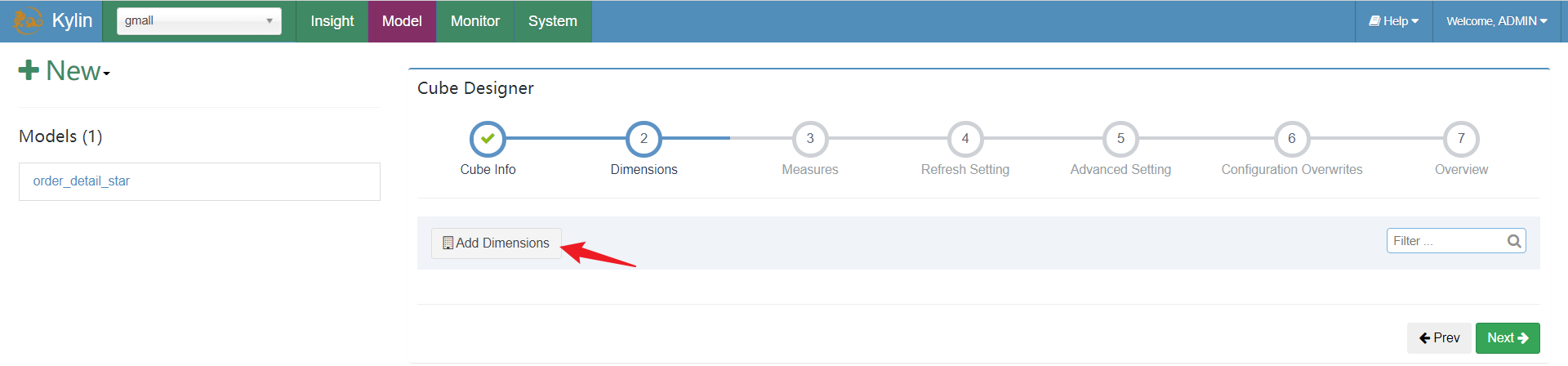
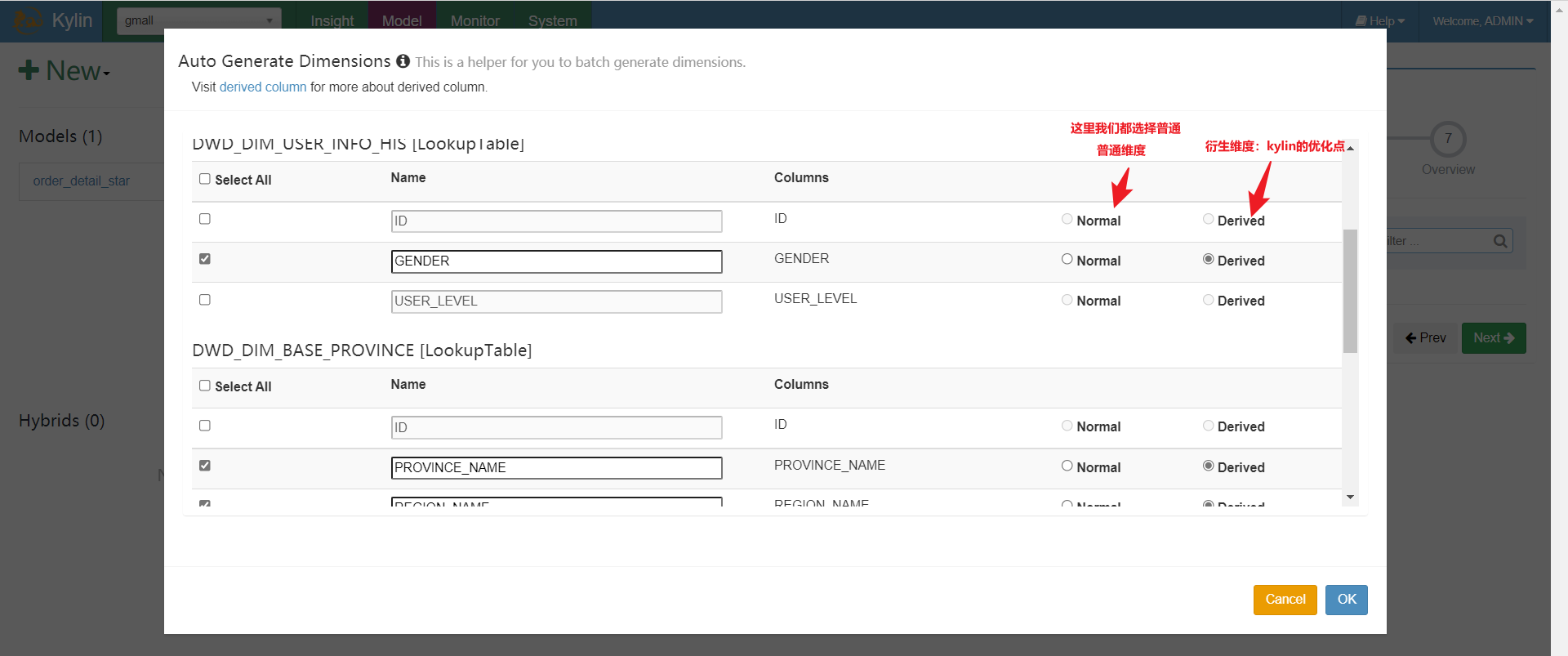
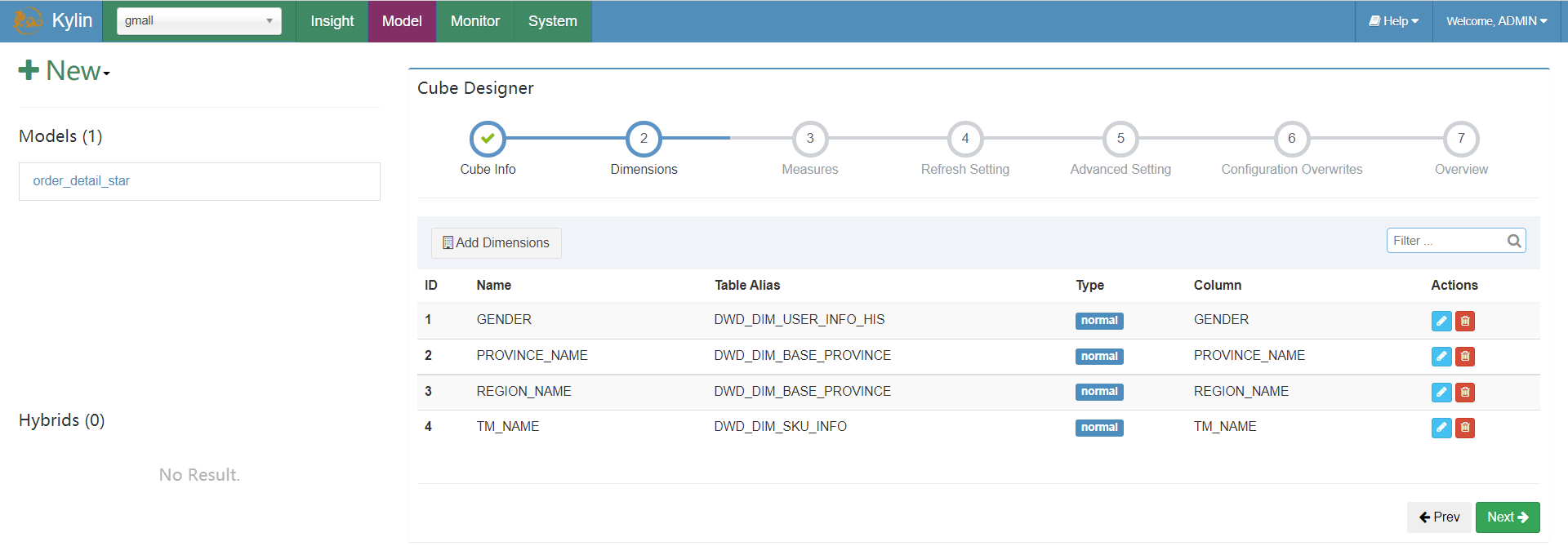
告知计算规则:
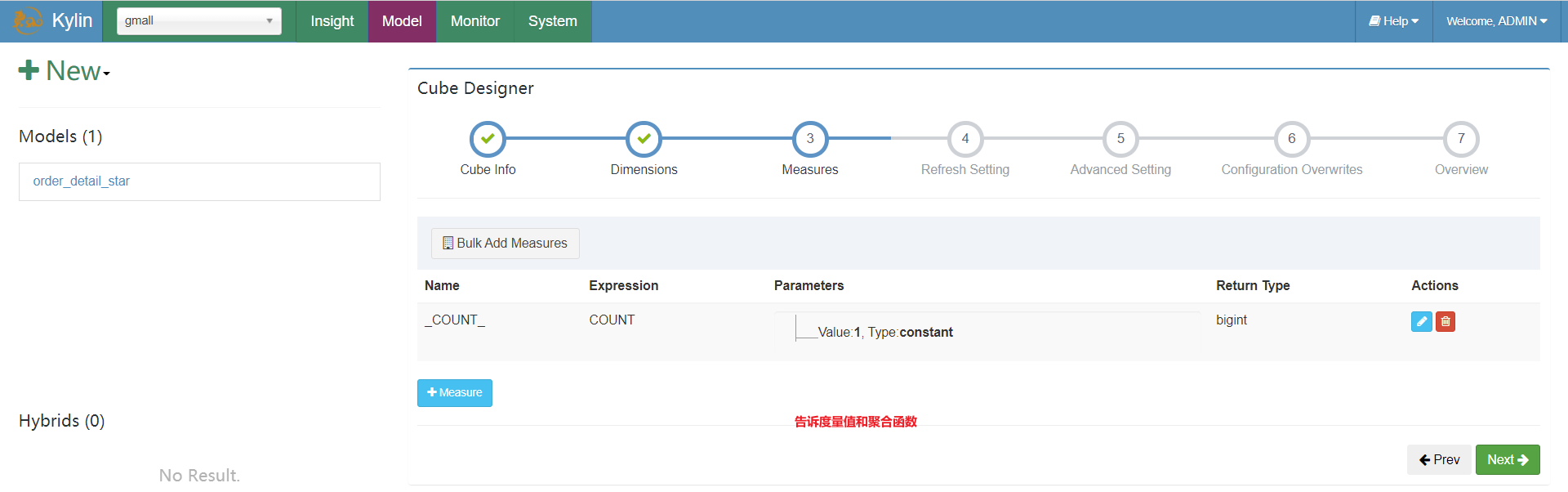
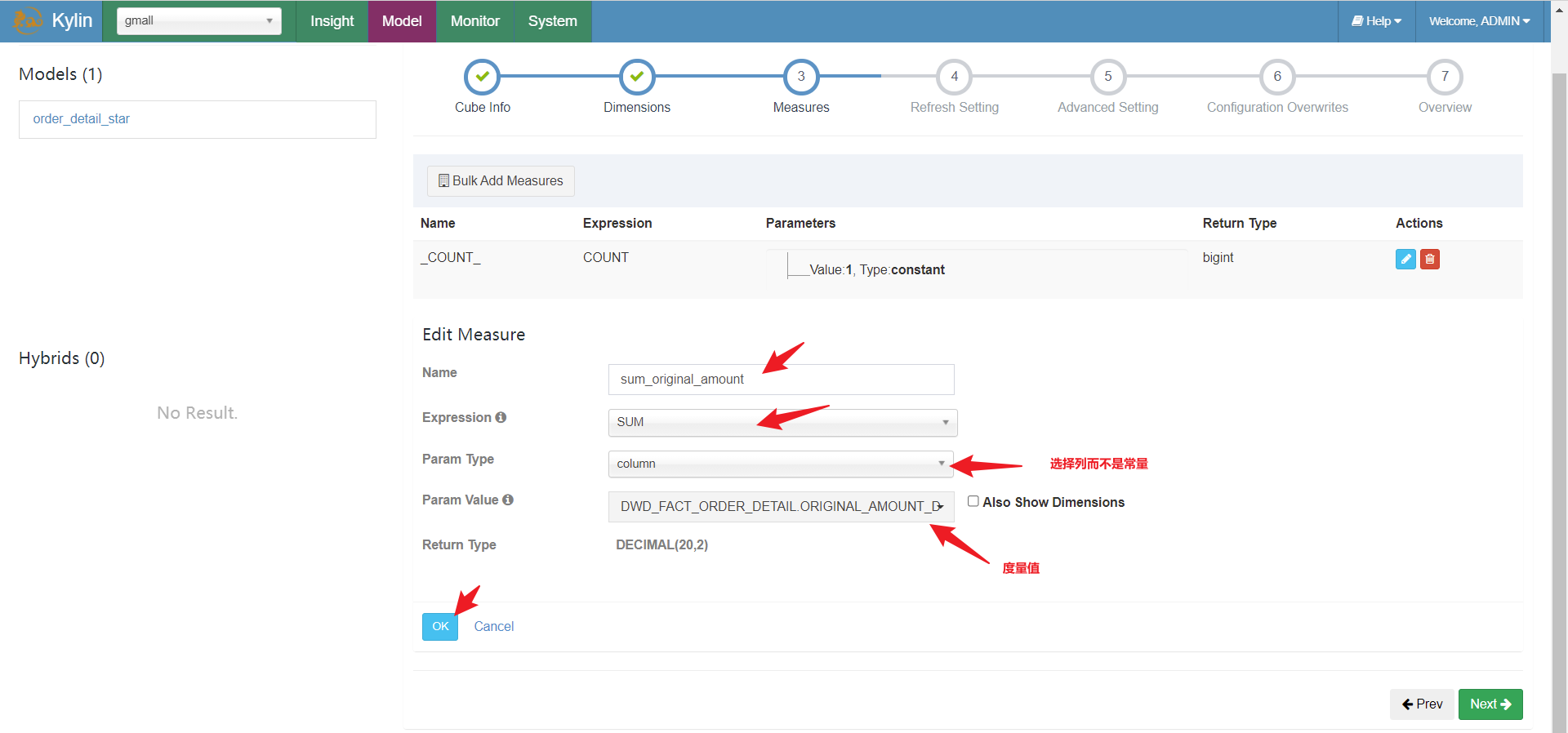
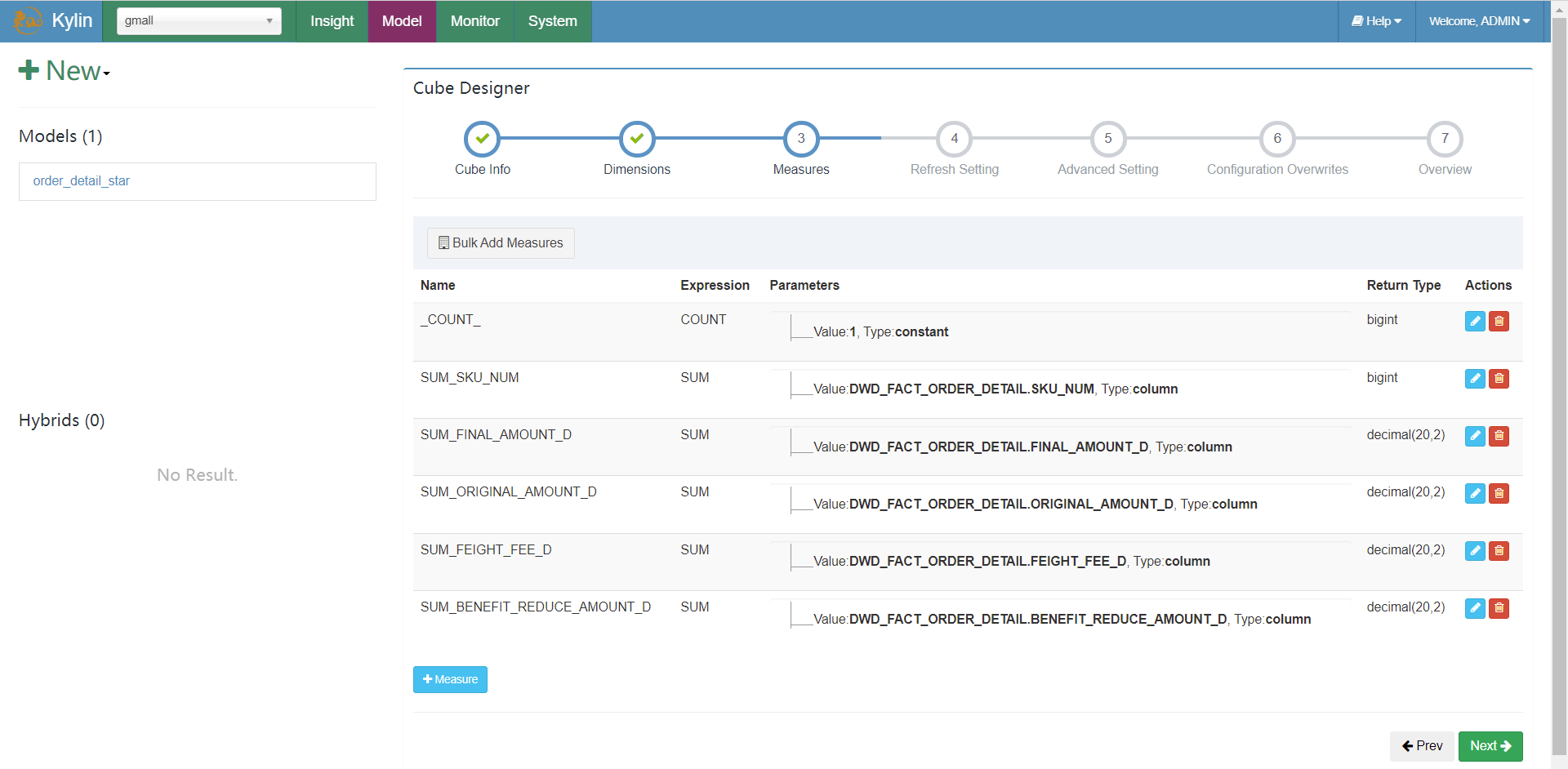
到目前为止,基本计算参数已经配置完成,下面是优化的参数设置:
在Kylin中,定义好cube后会进行计算,一天计算一次,每次算一次都会往Hbase新建一张表插入,随着表越来越多会产生跨表查询,因此会产生性能问题,所以这里参数会自动对表进行合并(不是hfile合并),底层逻辑是:
- 随着kylin每天计算一次生成一张表,到第7天判断是否满足7,满足7合并成7天的表;
- 继续生成表,当满足28天时,就合并成28天的一张表;
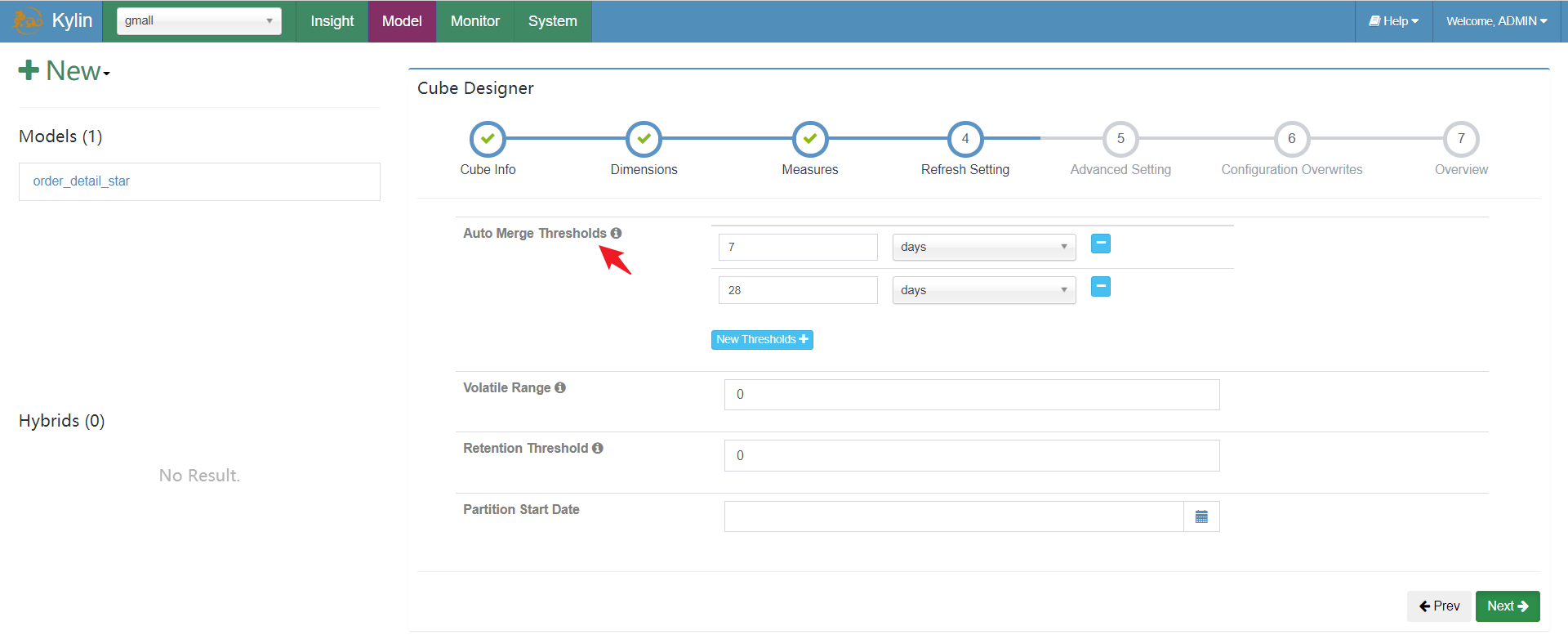
之后就是一些高级配置,可以略过。
开始计算:
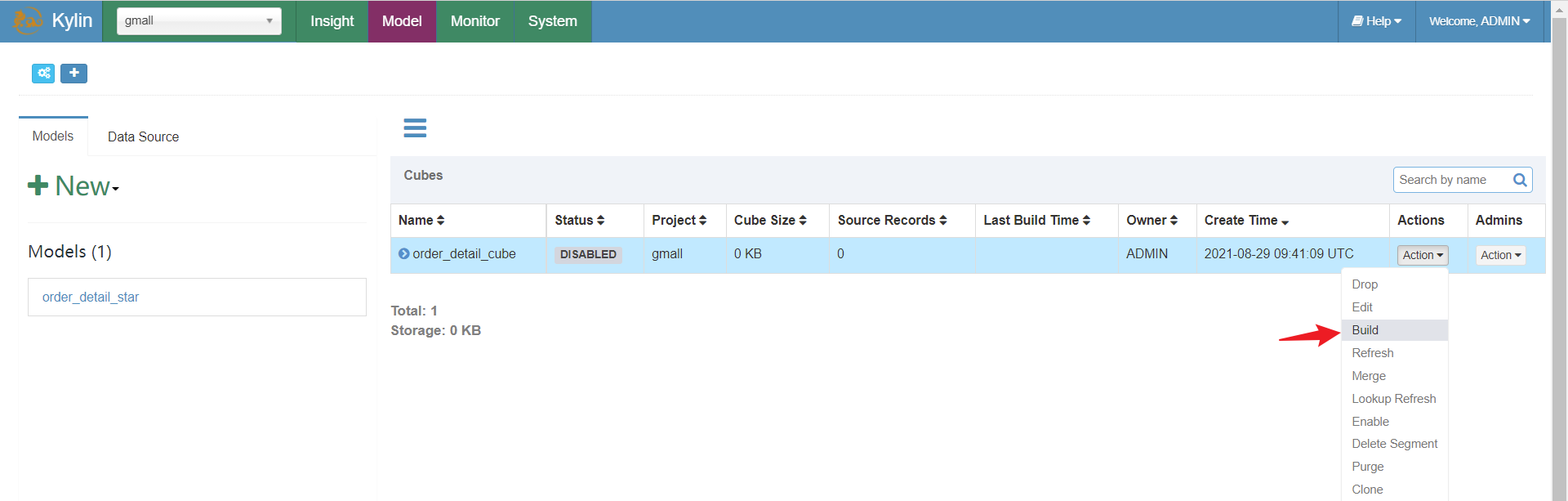
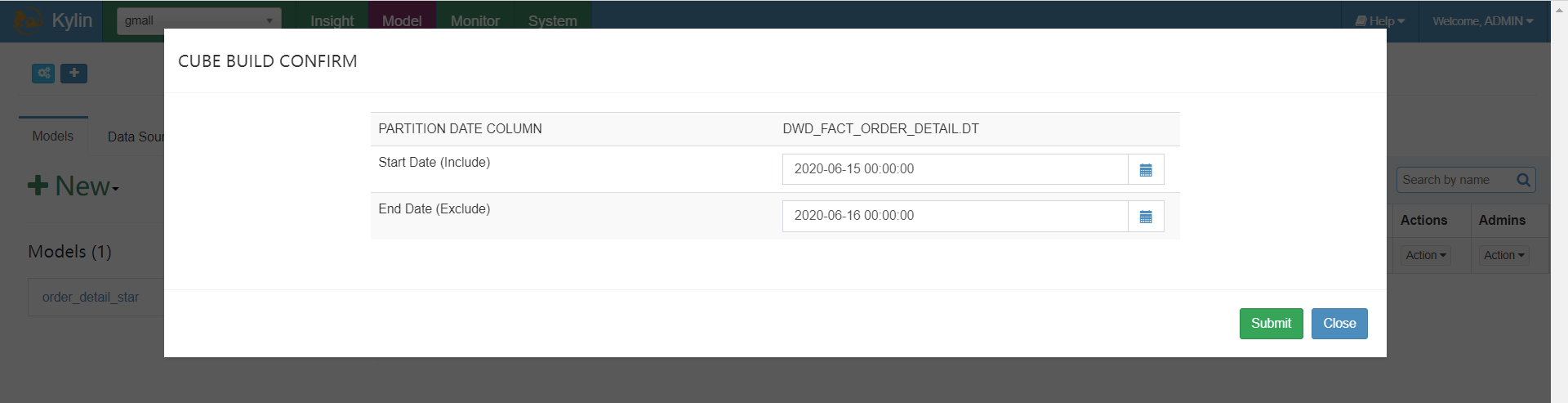
提交后,任务已经提交到yarn上去运行,可以到monitor上查看任务:
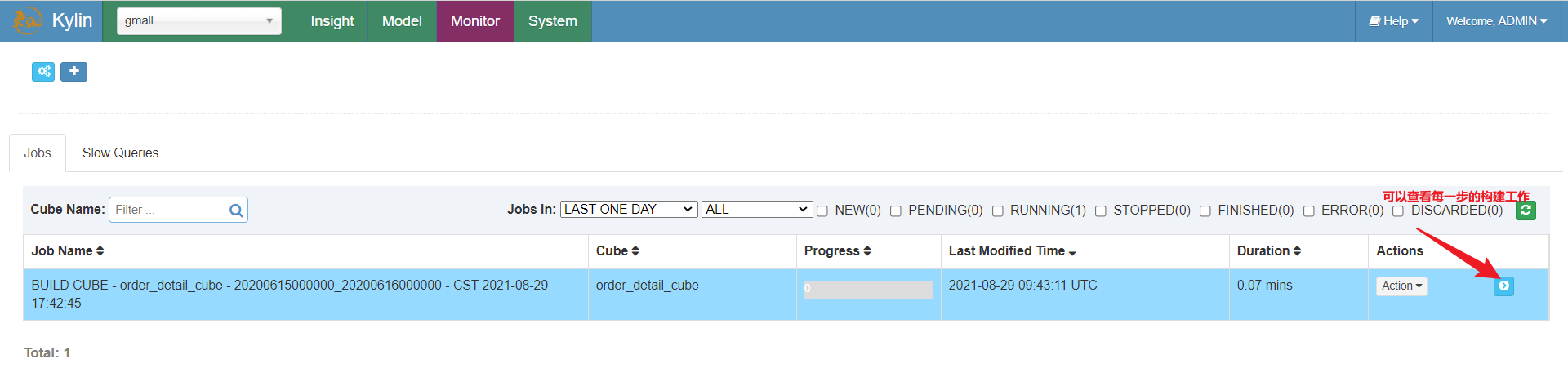
蓝色代表正在执行,绿色代表执行完毕,红色代表报错:
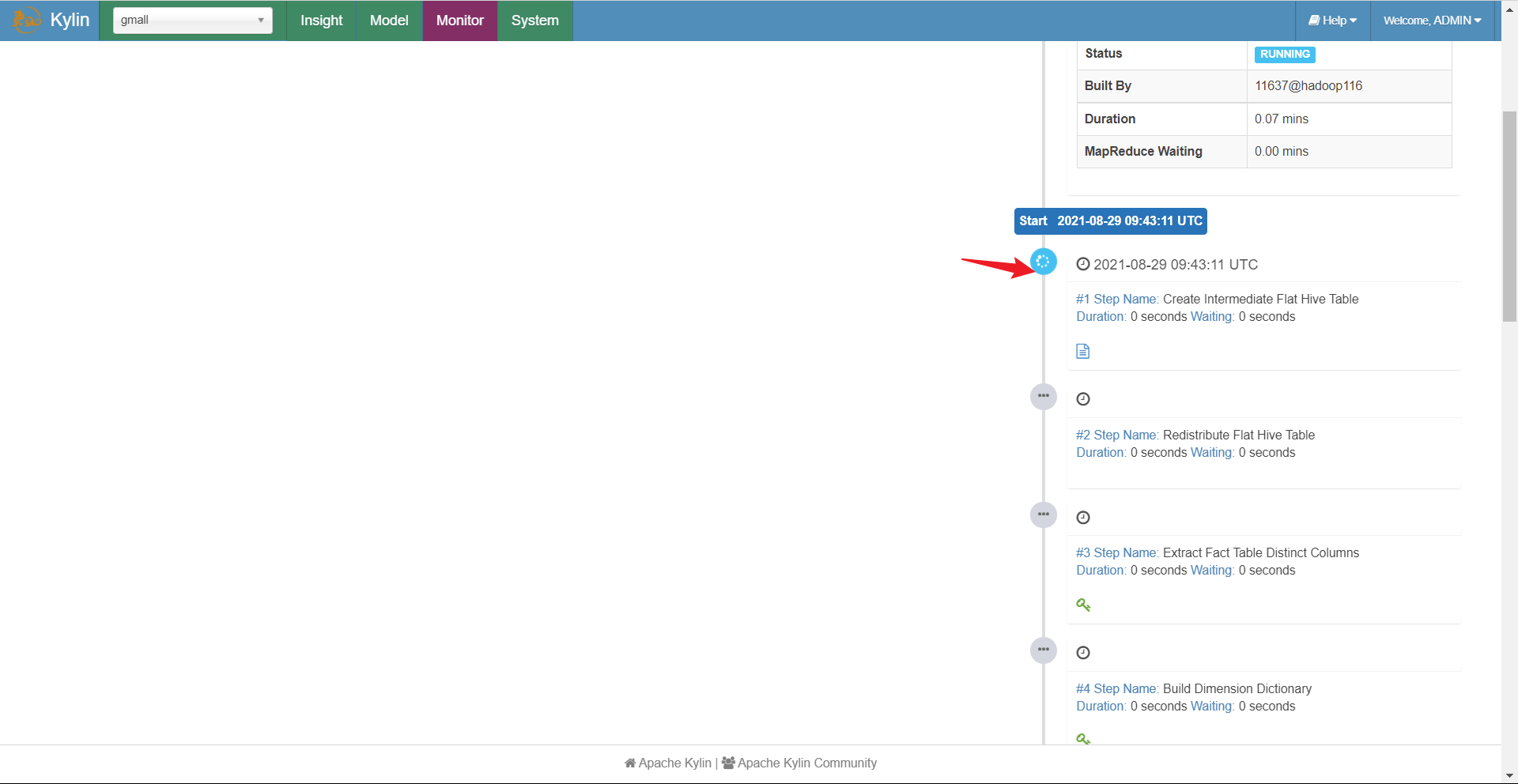
上面是kylin构建cube的整个工作流程,kylin通过jobhistoryserver判断任务执行情况,执行成功就会跳到下一个任务继续执行。
报错问题
可以看到,任务报错,主键重复。因为我们的表DWD_DIM_USER_INFO_HIS是拉链表,记录了同一个用户的不同状态,所以存在多个主键相同的记录。此外,由于商品维度表采取的是每日全量分区,而在join维度表的时候我们并没有地方可以选择join哪个分区,默认是全量join。所以这也会造成多条主键重复的数据。
解决方案1
不能直接让事实表去join维度表,采取每次从维度表拉取当日全量数据到一张临时表,用事实表去join临时表的方式去解决这个问题。
这种方案比较繁杂,要增加一环的调度去生成临时表。
解决方案2
与方案一思路相同,但不使用物理临时表,而选用视图(view)实现相同的功能。视图就是一张虚拟表,可以从表里select数据,但表下面不存在数据,数据是动态的,什么时候用视图就什么时候去找数据。
创建视图:
直接在hive客户端上写即可。
1 | --拉链维度表视图 |
删除原来的任务
- 先删除任务,因为kylin考虑到失败任务会重试所以需要我们手动删除任务;
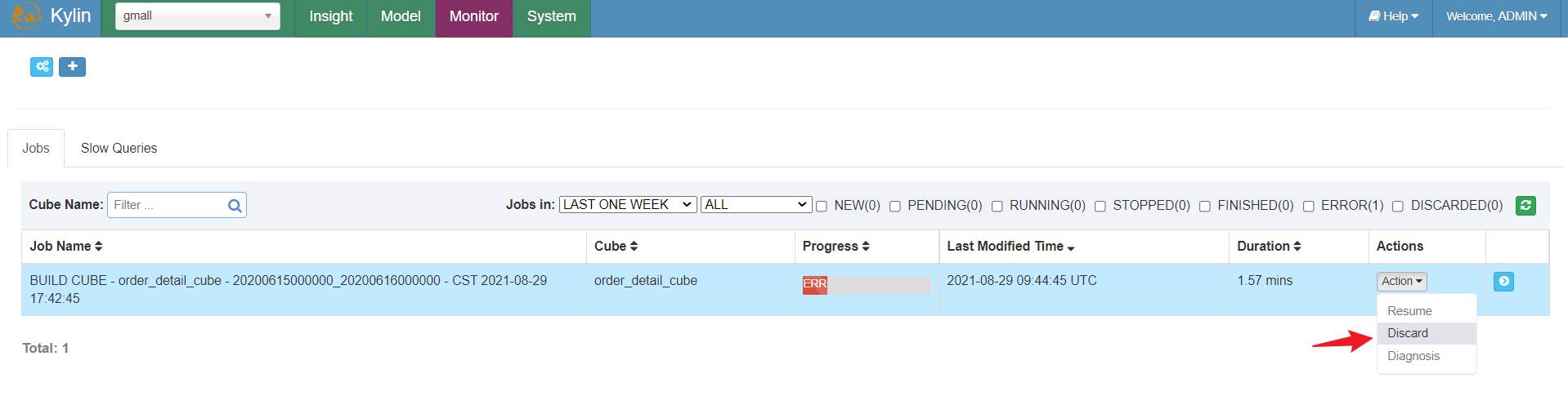
- 去删除cube,因为任务执行成功后是为了构建cube,所以去删除cube;
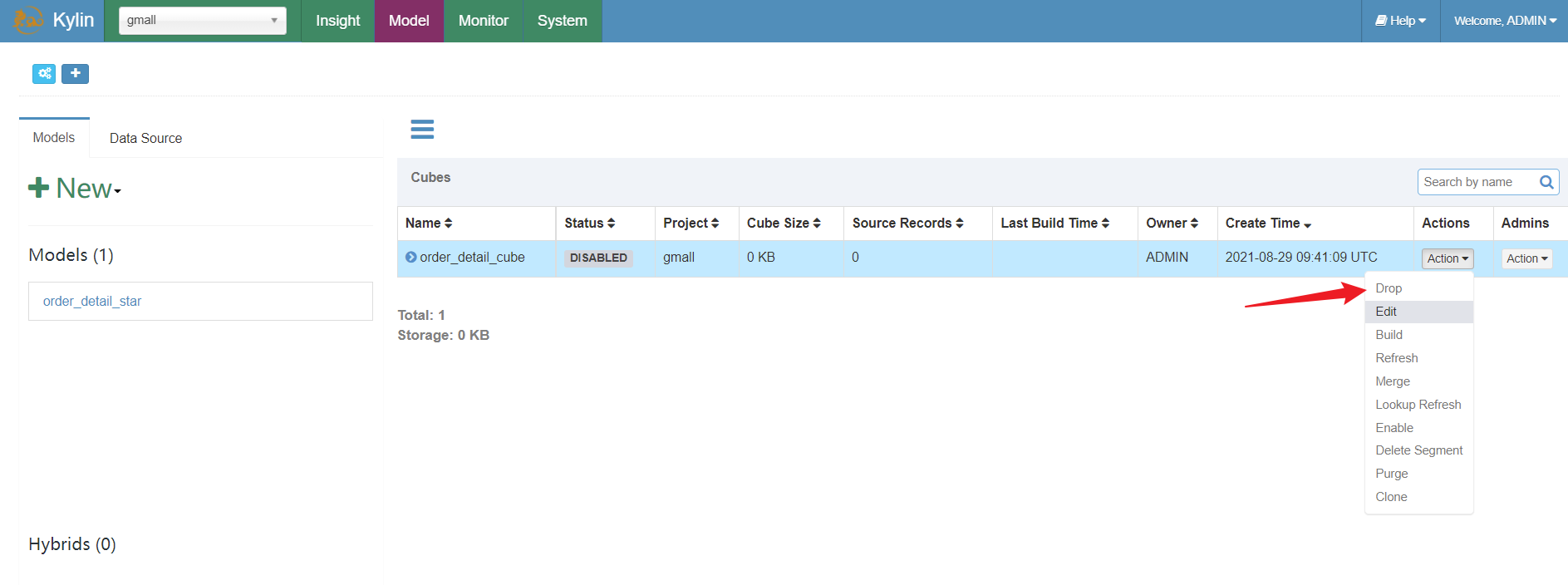
- 去删除model,因为model使用的还是之前的那几张维度表,所以需要删除model,才能删除先前表,重新选表;
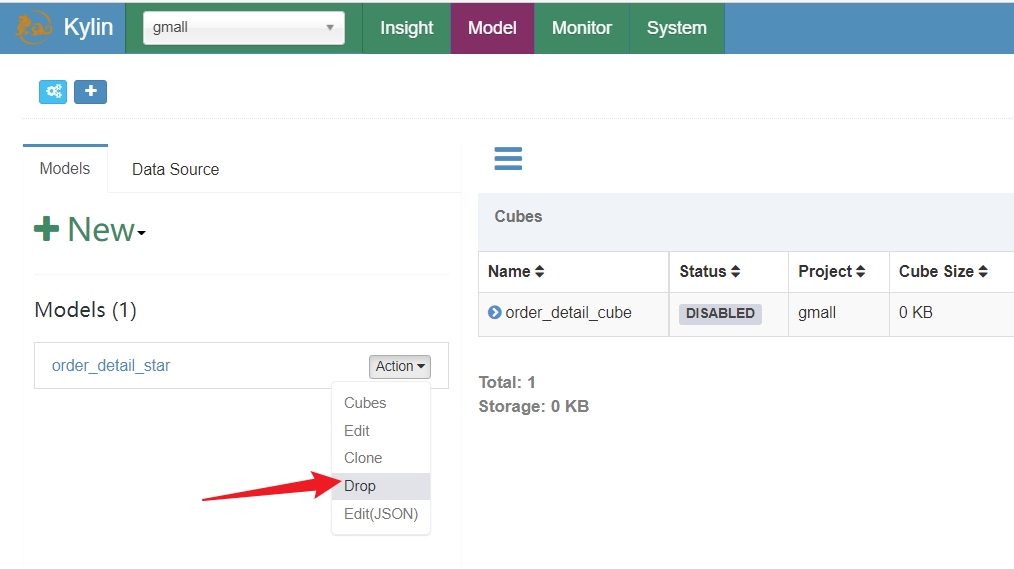
- 删除table,重新引入视图表后重新建model;
最后重新执行,执行成功:
如何使用Kylin进行查询
Kylin查询
进入该页面写sql查询,所能使用到的字段只有我们构建cube时用到的字段。
在查询的时候,要注意join的方式只能和我们先前创建cube选择的链接方式一致,同时事实表要join在维度表前面。
kylin查询是亚秒级的响应,这里因为初始查询需要和Hbase建立链接,所以时间花费的会多一点。
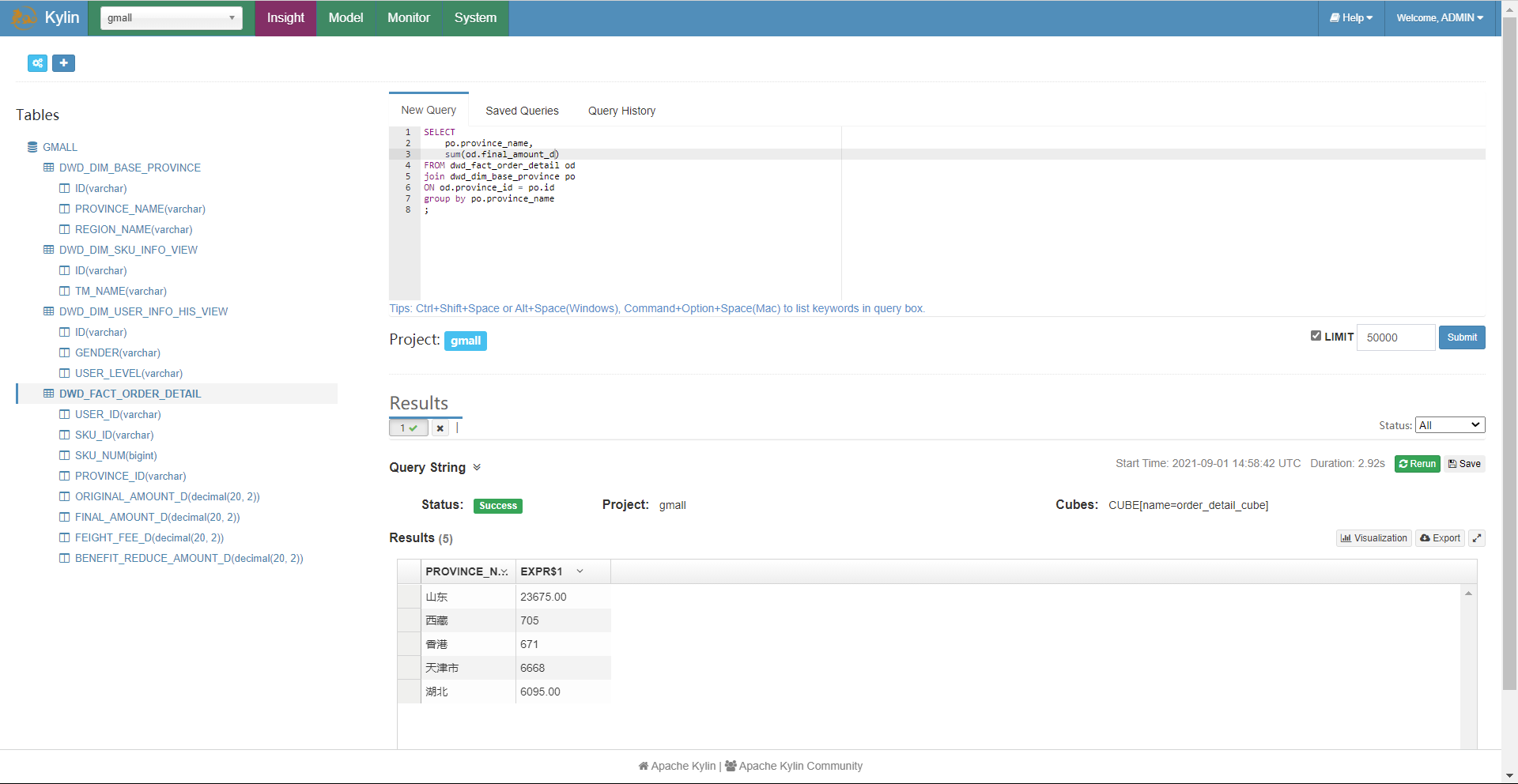
点击右下角的visualization可以图形化展示数据:
Kylin自动调度
借助Kylin提供的RestApi实现将调度任务封装到脚本,自动执行任务。
案例一
通过curl传递json,post给kylin,执行查询。注意在认证传递”账户名:密码”时,需要对这个字符串使用base64加密传递。
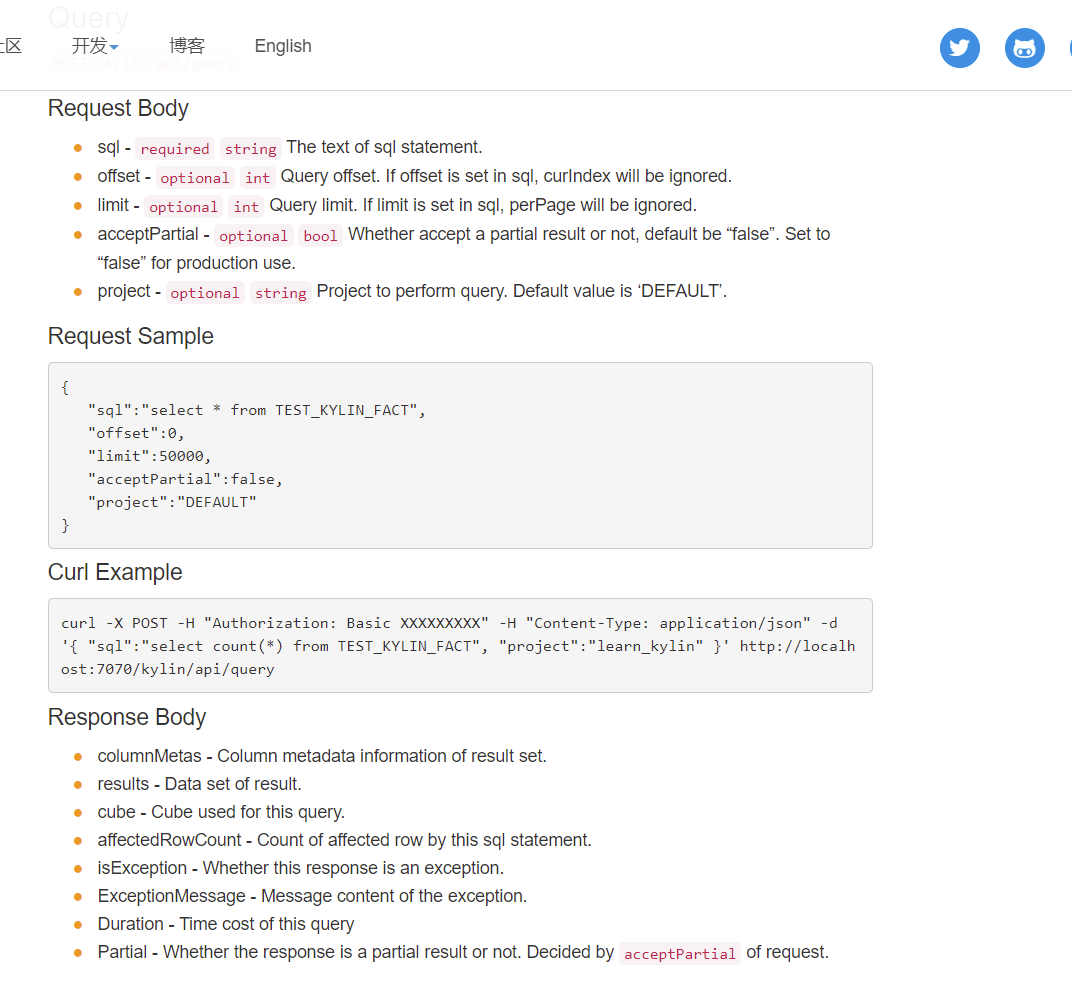
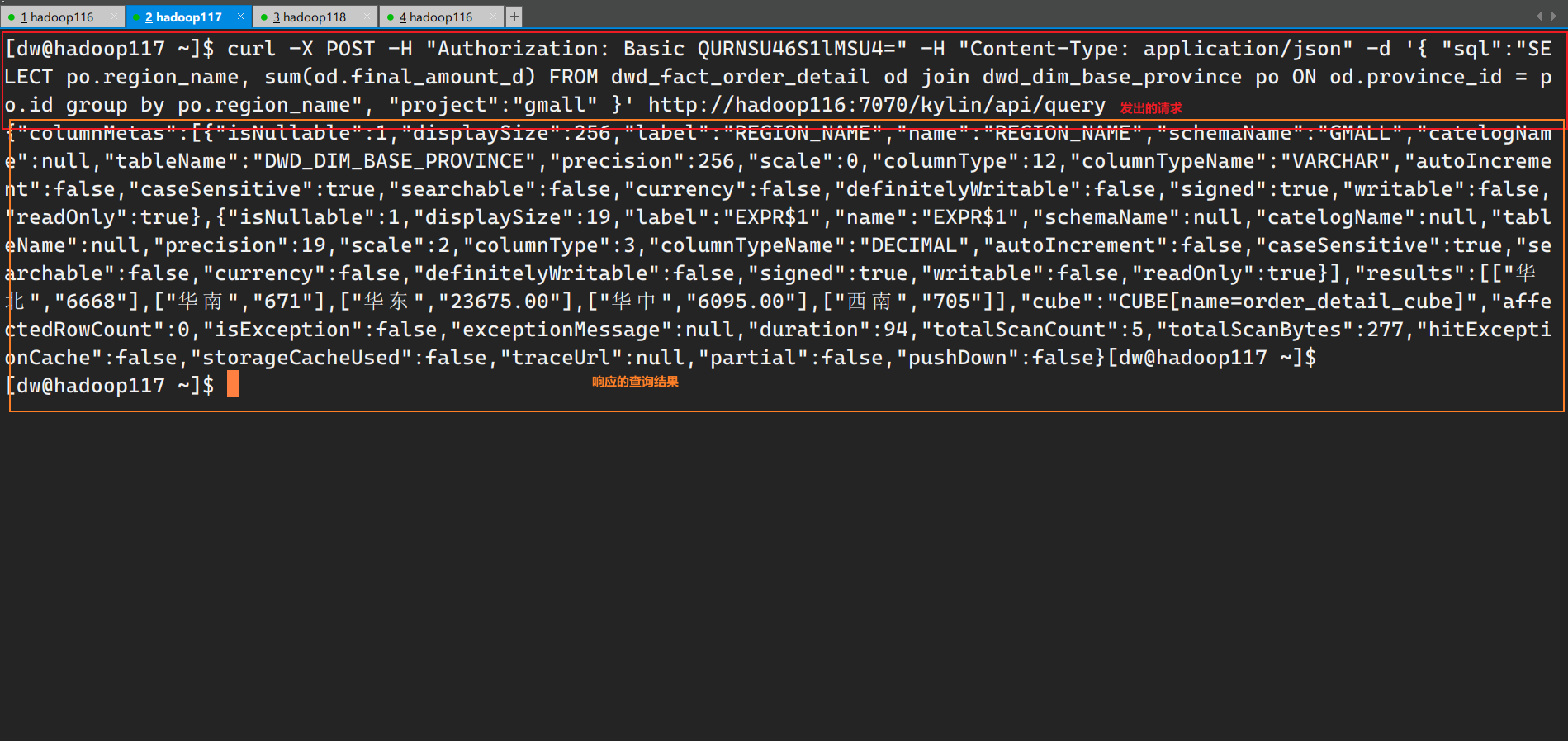
1 | curl -X POST -H "Authorization: Basic [base64加密的密码]" -H "Content-Type: application/json" -d '{ "sql":"SELECT po.region_name, sum(od.final_amount_d) FROM dwd_fact_order_detail od join dwd_dim_base_province po ON od.province_id = po.id group by po.region_name", "project":"gmall" }' http://hadoop116:7070/kylin/api/query |
通过restful api来build cube
先找到文档build cube位置:
1 |
|
Kylin优化
Kylin构建优化
主要集中在计算和查询的优化上。即提高计算速度和查询的效率。
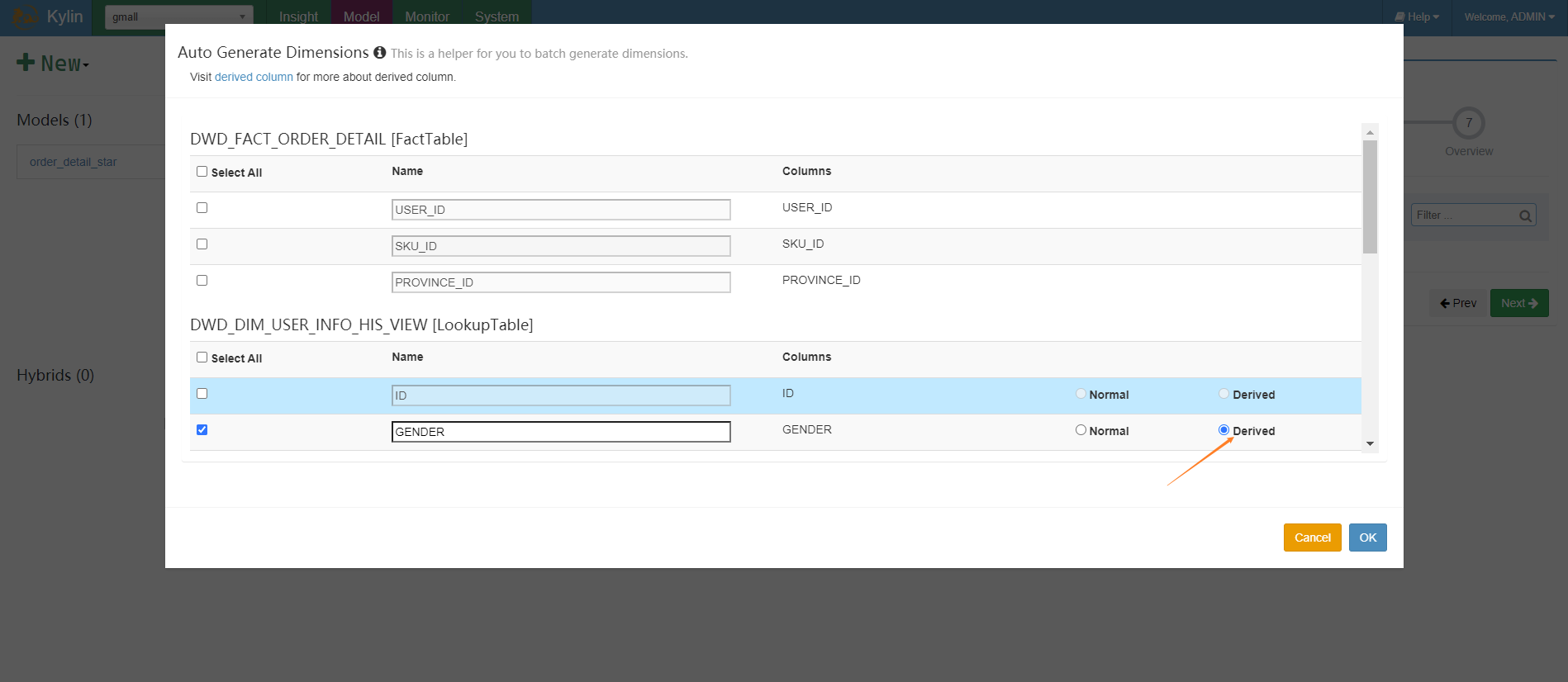
使用衍生维度
衍生维度能够极大的降低计算量。衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们。Kylin会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。
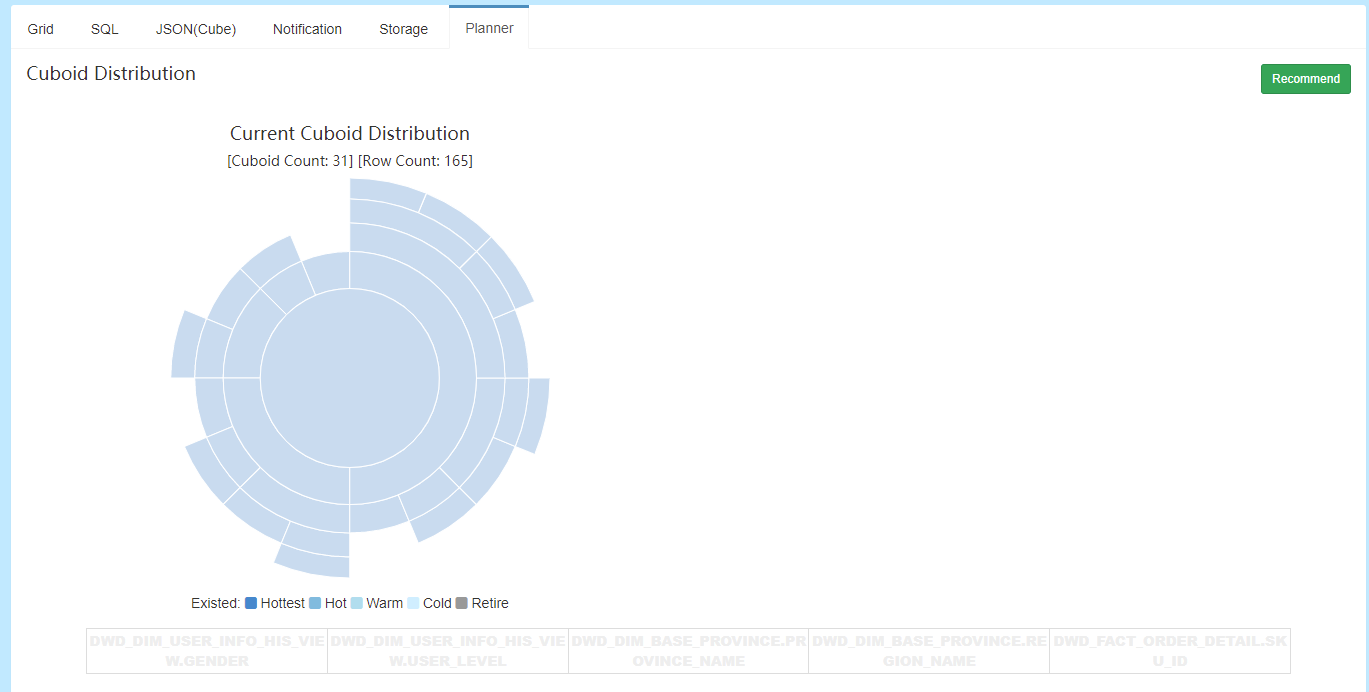
这里我们拿之前构建的cube planner来可视化分析下:
前面我们构建了5个维度的planner,如下图所示:
这次我们重新构建一个cube,采用衍生维度,维度字段数也同样是5个:
最后构建出来的cube如下图:
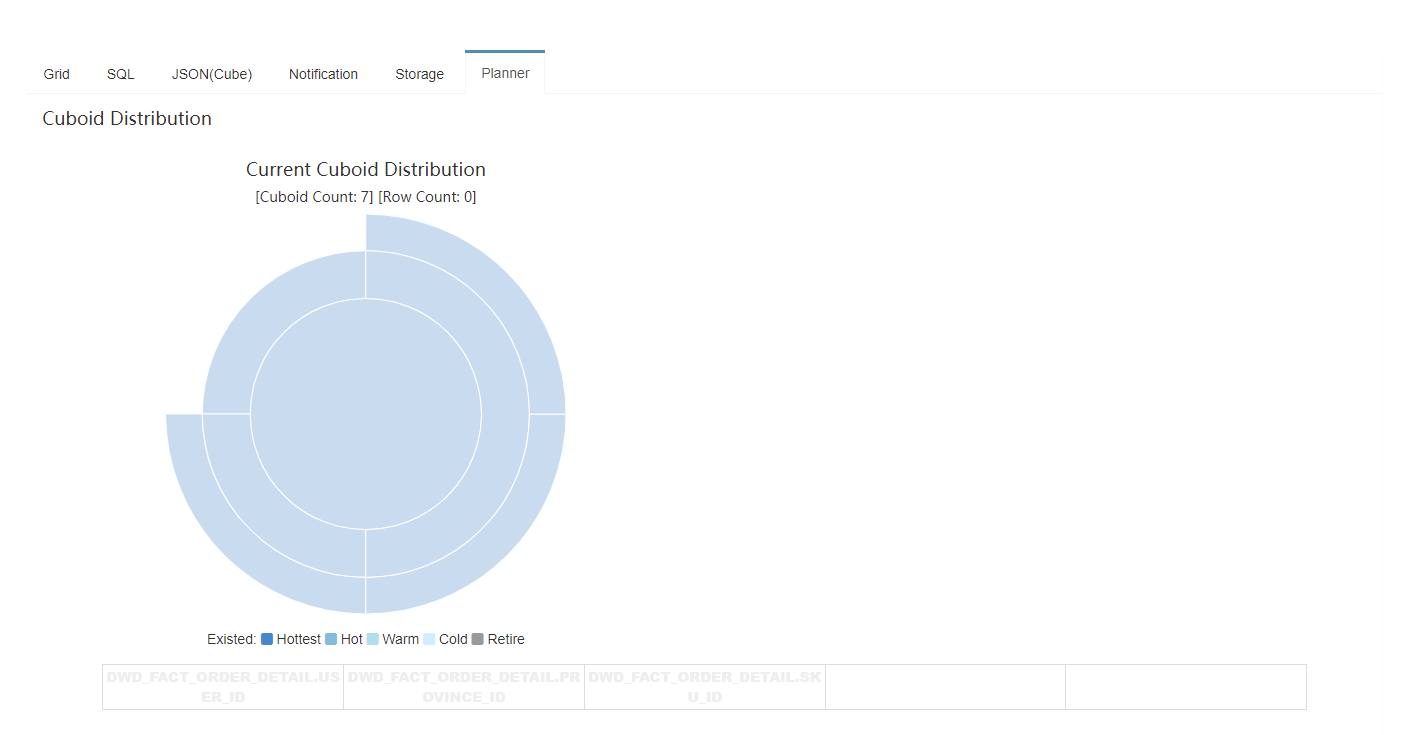
可以看到,明显比之前按普通计算构建的planner简化了很多,只有3个维度。
实际上,衍生维度并不是按照你所勾选的维度字段去进行聚合,而是根据维度字段所在维度表的主键去进行聚合计算,最后查询的时候还需要根据维度主键映射维度字段再根据维度字段去进行聚合计算。所谓衍生即是主键的衍生维度字段,区别于普通的维度,只是将计算量放在了查询的时候。

那么我们什么时候可以选择使用衍生维度呢?
首先看从主键到衍生维度的聚合量大不大,如果主键到衍生维度是一一对应的,那么我们可以选择衍生维度。即通过主键和衍生维度的基数(count(distinct)数值),来判断是否要使用衍生维度。
总的来看,Kylin是即席查询工具,为了保证查询的效率应该尽量避免使用衍生维度,只有当聚合量过大,计算量太大,在需要用到数据的时候算不完,那么我们可以使用衍生维度。
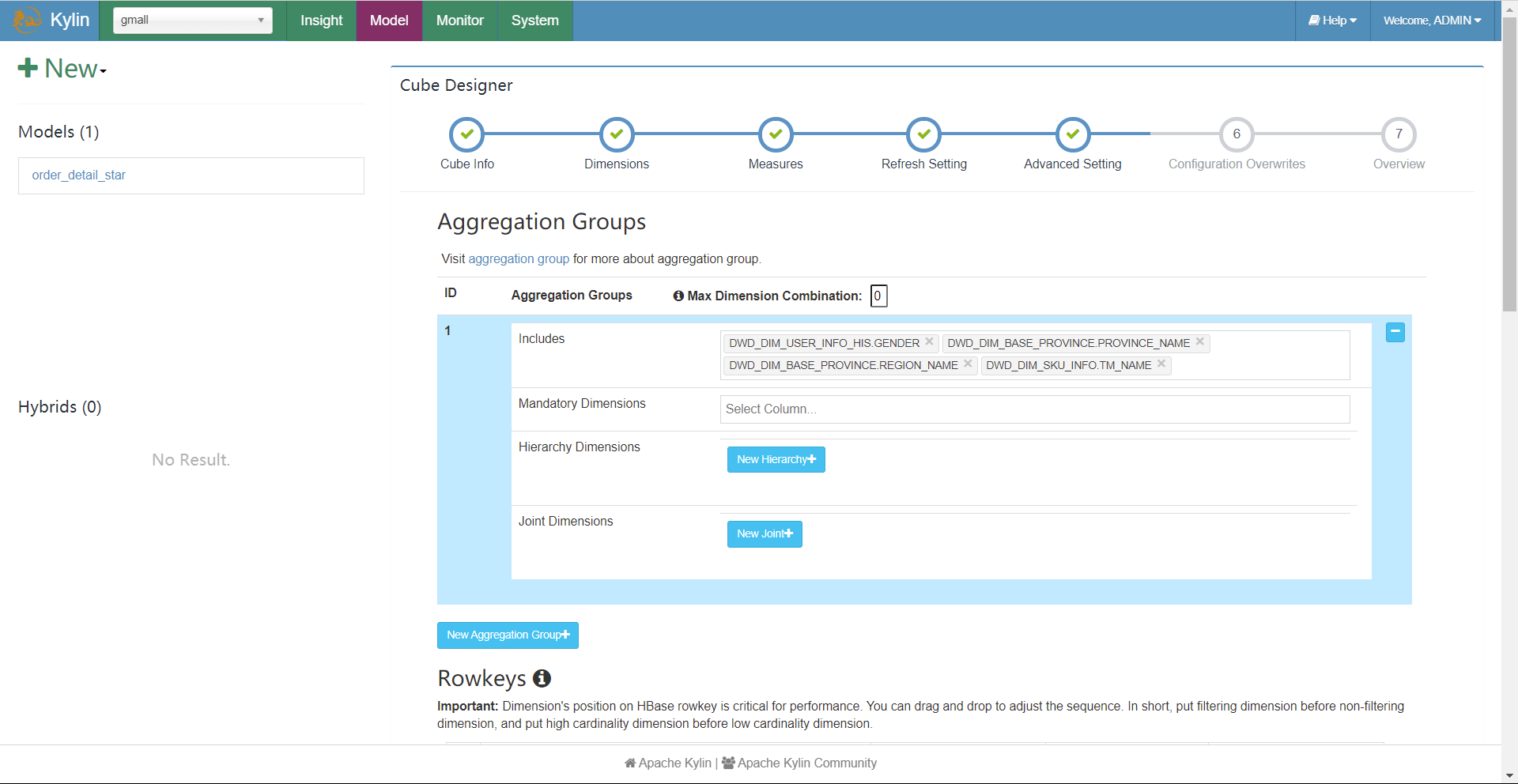
聚合组(Aggregation Group)
聚合组是一种强大的剪枝工具,剪的也是cuboid。它也是一种对计算进行优化的一种方案。在我们计算的所有维度组合中,可能存在一些维度组合没有实际的意义,这种没有实际意义的组合,基本上聚合了我们也不会去查询,如果我们能够提前将这些没用的cuboid计算出来,就可以大大降低我们的计算量。
聚合组一共有三种类型:强制维度、层级维度、联合维度。
强制维度
强制维度即强制后面进行分组统计时,每一个组一定会有某一个或某几个维度字段,不包含某一个或某几个维度字段的cuboid就不会被计算生成。
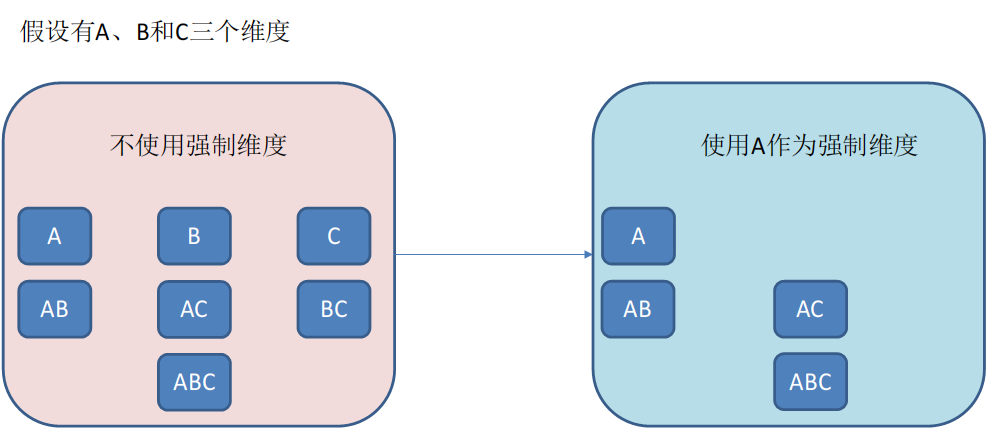
层级维度
假设有一张时间维度表,年、月、日三个维度。要获取具体某一天,我们需要指定具体哪一年、一月、一天的数据。要获取某一月的数据要指定哪一年、哪一月。
但我们在构建cube的时候,可能会出现“年日”、“日”、“月”这种没有意义的cuboid组合。类似的还有省市区镇这种维度。
因此通过层级维度我们可以不计算这种无意义维度,即层级维度有意义的组合是 有顺序的,是从最高级维度到低级维度才有意义(年—>月—>日)。
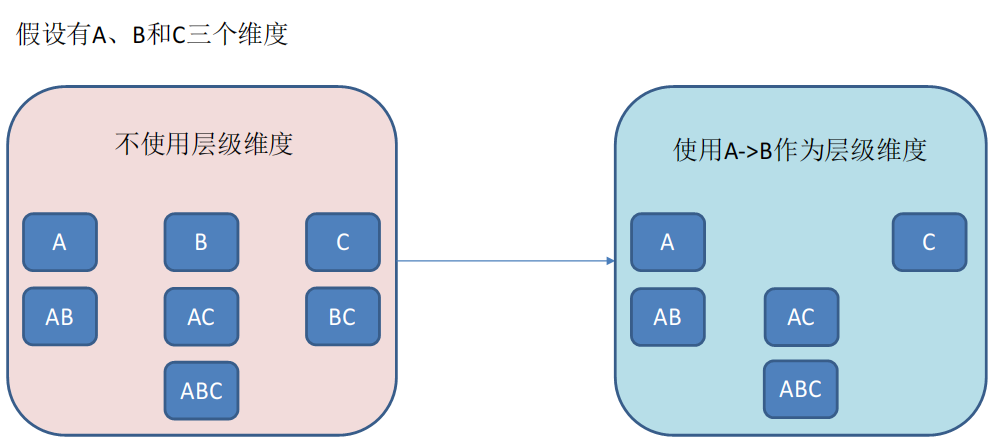
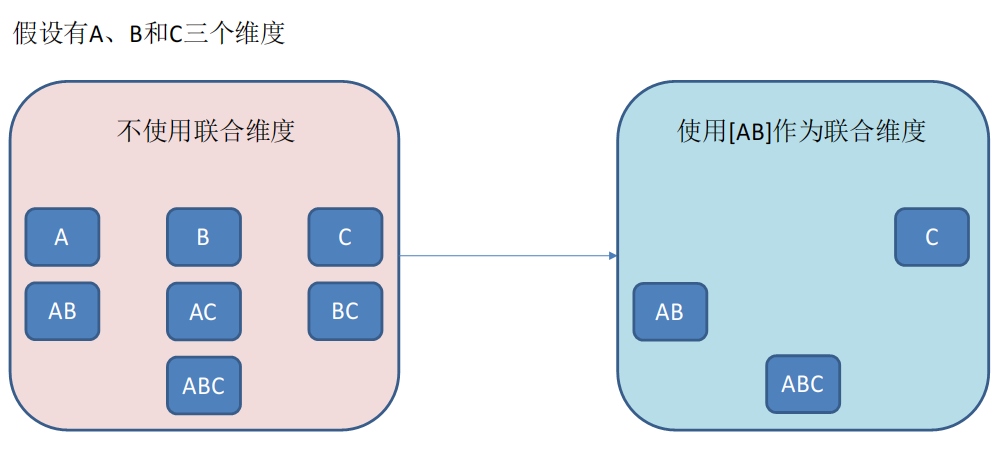
联合维度
联合维度即即将若干个维度当作一个整体,要么同时出现要么同时都不出现。即当某几个维度一定要放在一起才有意义的场景下可以使用联合维度。
聚合组配置
在构建cube时有一个高级设置,在此处可以设置聚合组。

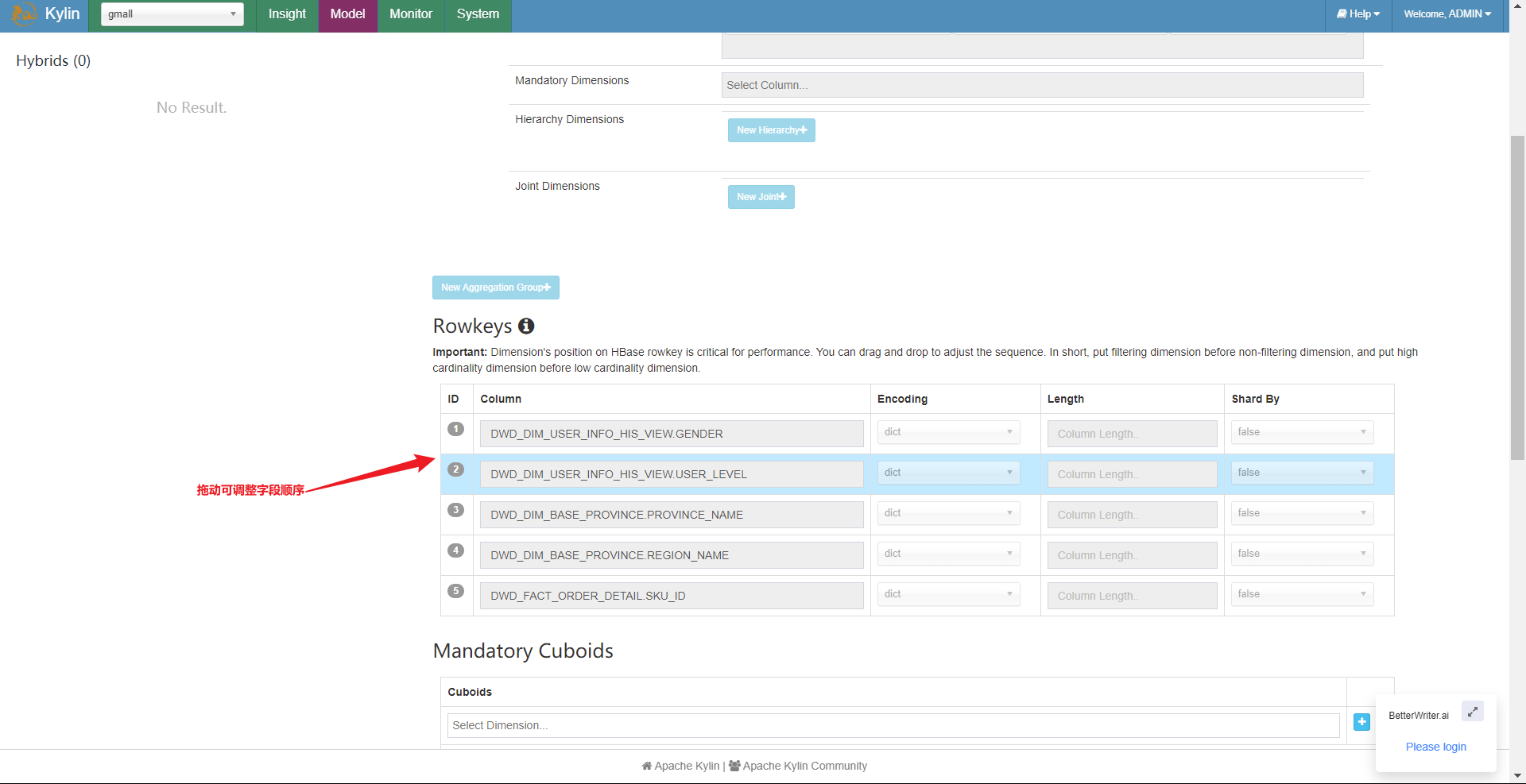
RowKey的优化
前面我们知道了存储在Hbase中的cuboid的是以rowkey为索引,rowkey是16进制的维度+维度对应编码形式,但是具体维度区间里每个值对应的维度我们并不清楚,所以这里来介绍下如何根据对应维度区间前后顺序来优化rowkey。
| RowKey | CuboidId(对应维度) | DimensionValue(对应维度里值的编码) |
|---|---|---|
| 111001 | 111 | 001 |
- 被用作过滤的维度对应放在rowkey的维度字段区间前面;(优化的是查询)

rowkey在hbase中是按照字典顺序排的,第一区间值相同比较第二区间值,以此类推。左边第一个表就展示了hbase中rowkey字典排序。(为了方便阅览,这里把rowkey拆分成A、B两列)
现在根据中间的查询语句去查询数据,sql转成hbase查询语句,从左边第一张表拿结果,可以看到结果在hbase中的分布是零散的,不在一块。
Hbase在查询数据时有get和scan两种方式。get是根据某个rowkey获取某一行数据。scan是根据rowkey范围去扫描一部分数据。
我们上面的查询就是scan的方式。scan这种查询查询方式,当我们指明了查询范围,并且这些范围数据在一块的时候查询效率是最高的。我们设置rowkey的原则之一有“将来一起查询的数据放在一块”。很明显,我们左边那张表的方式就不符合这个原则。
通过调整rowkey的顺序,B放前面,这样就能够满足这个原则了。这就是优化点1的底层原理。
- 基数大的维度放在小的维度前面;(优化计算)
对某一字段进行count(distinct)得到的数值就是基数。假设有年月日三个维度字段,我们可以知道“日”的基数要大于“月”,“月”要大于年,所以rowkey顺序就是:日月年+维度编码值。
下面以cube构建的过程举例:
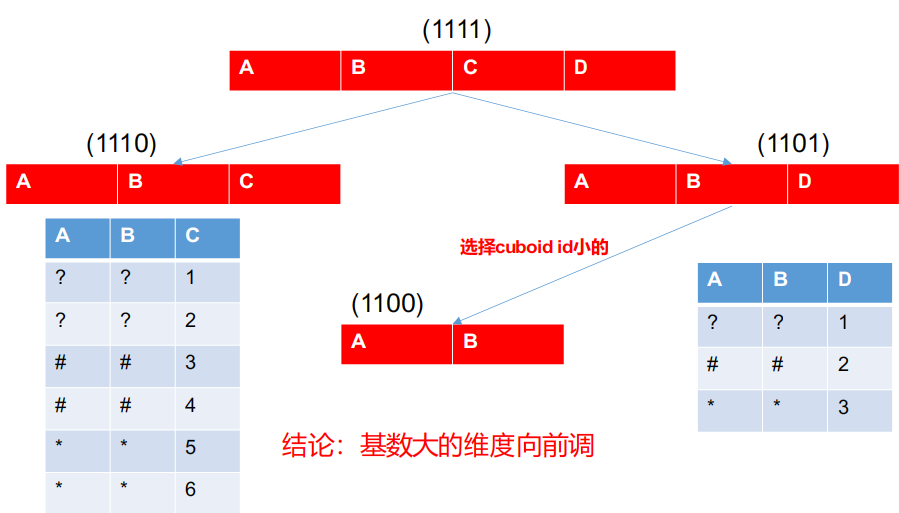
假设有四个维度进行构建cube,先聚合计算最高维度,接着聚合计算三维度。在聚合两维度的时候,上游有两个三维度的聚合结果,那么计算聚合两维度的数据是来源于其中一个还是两个呢?
因为我们要从ABC三维度得到AB两维度,只需要ABC维度按照C维度聚合即可,对于ABD也同理,但我们不需要计算两遍,只需要一遍即可,所以是其中一个。
那么既然两个只需要其中一个即可,那我们选哪个呢?
那么计算量大小是由什么决定呢?
因为AB字段是降维目标字段,所以可以不需要考虑,那么决定计算量大小的就是C和D字段的基数了。哪个基数大,哪个计算量就大。
Kylin底层是选择cuboid小的去进行计算(1110 > 1101)。由此,就得保证cuboid小的字段对应的基数值要小,这也就是优化2原则的底层原理。
RowKey优化配置
具体优化配置和前面聚合组配置是在同一页面:
这里除了调整顺序,我们还能调整编码的方式。
并发粒度优化
当Segment中某一个Cuboid的大小超出一定的阈值时,系统会将该Cuboid的数据分片到多个分区中,以实现Cuboid数据读取的并行化,从而优化Cube的查询速度。这里主要涉及的是HBase的分区region优化的知识点。
在HBase中,没张表会分成多个region,每个region会分布在不同的region store上。在Hbase中生成region的途径有:
- 自动分裂,随着表数据越来越大达到阈值,会自动分裂;
- 预分区,即在建表时指定分裂规则,比如指定分区个数,分区的键生成规则或者指定分区键;
在HBase中,用的最多的是预分区,因为我们能够指定哪条数据到哪个分区,很好的将数据打散到region中。而自动分裂会产生region热点的问题。
具体的实现方式如下:
构建引擎根据Segment估计的大小,以及参数“kylin.hbase.region.cut”的设置决定Segment在存储引擎中总共需要几个分区来存储,如果存储引擎是HBase,那么分区的数量就对应于HBase中的Region数量。kylin.hbase.region.cut的默认值是5.0,单位是GB,也就是说对于一个大小估计是50GB的Segment,构建引擎会给它分配10个分区。用户还可以通过设置kylin.hbase.region.count.min(默认为1)和kylin.hbase.region.count.max(默认为500)两个配置来决定每个Segment最少或最多被划分成多少个分区。
这里的segment指的是olap cube的一部分。在使用Kylin时,我们会先定义好一个cube,这个cube每天都会计算,每天计算的数据到HBase中都是一张新的表。每天一个表,Kylin会对这些表按时间进行合并(7天一并,28天一并)。
而segment就是指Hbase中属于该Cube的一张表。一张表对应有多个region。这里的并发粒度指的就是region的个数。
