
大数据技术之即席查询——Presto
Presto
Presto简介
Presto是一个开源的分布式SQL查询引擎,数据量支持GB到PB字节,主要用来处理秒级査询的场景。目前对PB以上级别的数据量实现亚秒级查询只有Kylin等少数,都会用到预计算。PB级别以上数据基于亚秒级的很难通过内存来实现。
注意:虽然 Presto可以解析SQL,但它不是一个标准的数据库。不是 MYSQL、Oracle的代替品,也不能用来处理在线事务(OLTP)。
Presto原理
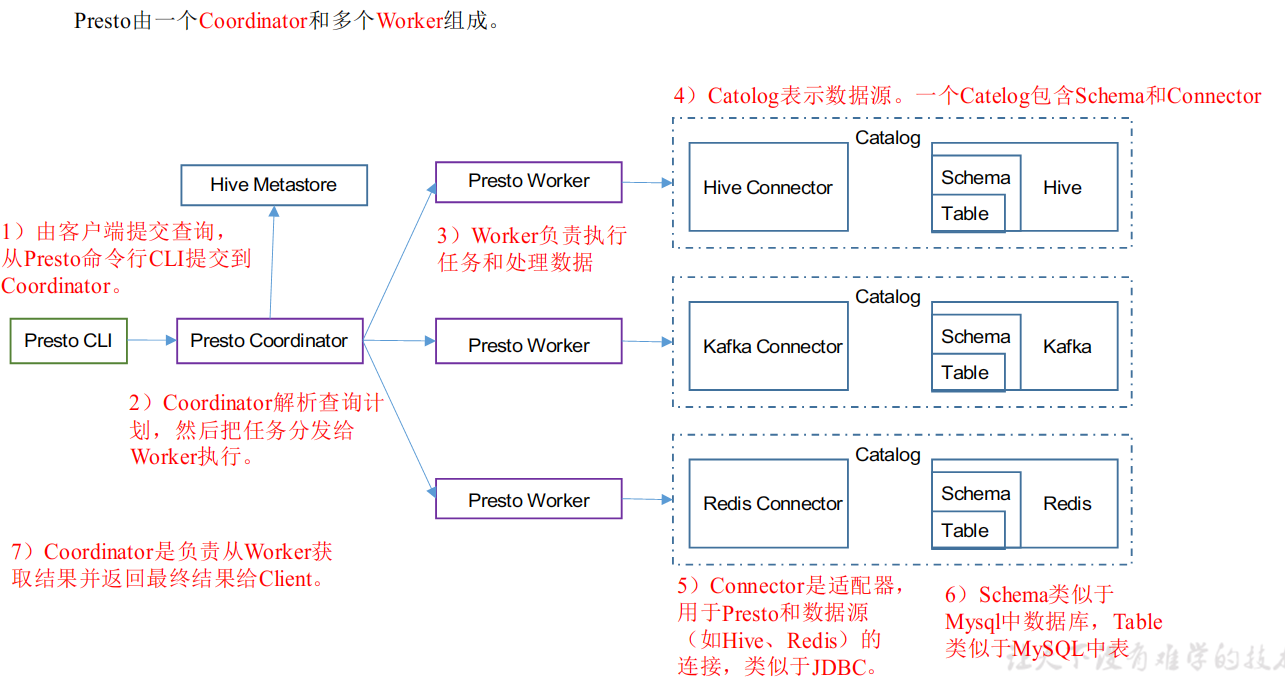
Presto架构
Catolog是Presto的一个数据源,每当我们想要对接一个数据源就需要配置一个catolog。
假设,我们想要获取HIve数据源,就需要配置一个hive connector对接hive元数据地址,获取hive的元数据(库表、及HDFS上路径)。connector可以通过mysql获取hive元数据也可以通过metastore获取。
presto 的hive connector主要通过hive的metastore获取元数据。
假设我们想读取Kafka,那么kafaka的connector就应该获取kafka集群地址和要消费的kafka的topic。
无论数据来自于哪儿,数据在presto底层都是数据库和表的形式。(schema —> table)
Presto的优缺点

优点
Presto基于内存进行计算,减少了硬盘的IO,计算更快。当然,当内存不够使用时,该落盘的还是得落。
由于基于内存,中间不需要经过shuffle,直接从头计算到尾,就像一个pipeline,更高效。
能够实现连接多个数据源,能同时对接Hive和Mysql,实现两方数据源的连接,主要因为数据在Presto中的存储结构都是一致的。
缺点
Presto能够处理PB级别的海量数据分析,但 Presto并不是把PB级数据都放在内存中计算的。而是根据场景,如 Count、AVG等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表査,就可能产生大量的临时数据,因此速度会变慢。这也是大部分引擎锁存在的问题。
Presto与Impala的比较
Impala是CDH平台里面的一个即席查询引擎。 两者的架构十分相似。
https://blog.csdn.net/u012551524/article/details/79124532
测试结论:Impala性能稍领先于Presto,但是Presto在数据源支持上非常丰富,包括Hive、图数据库、传统关系型数据库、Redis等。
Presto读lzo压缩格式文件问题
由于presto不支持lzo压缩,所以要读取lzo压缩的表得引入lzo的包。注意:我们这里读取的表是采用parquet先进行了压缩,然后再根据各内部列采用lzo去压缩,总体还是parquet列式存储格式,简单来讲就不是纯的lzo压缩。

要把lzo的依赖包放在presto根目录的plugin文件夹下:
从hadoop的common目录下复制lzo的jar包。之后关闭presto客户端,重启presto服务器节点。重新执行查询即可。
这次我们读取ods里的单纯lzo压缩的表会发现报错:

因为presto不支持读取,需要修改hadoop.LZO的源码,重新编译,才能够使得presto直接读取lzo。但是可以读取parquet+LZO。
Presto优化
数据存储
合理设置分区
与Hive类似,Presto会根据元数据信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能。
使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好。
使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,建议采用Snappy压缩。
优化之查询SQL
只选择使用的字段
由于采用列式存储,选择需要的字段可加快字段的读取、减少数据量。避免采用*读取所有字段。
1 | [GOOD]: SELECT time, user, host FROM tbl |
过滤条件必须加上分区字段
对于有分区的表,where语句中优先使用分区字段进行过滤。acct_day是分区字段,visit_time是具体访问时间。(能以分区作为过滤条件尽量以分区作为过滤条件)
1 | [GOOD]: SELECT time, user, host FROM tbl where acct_day=20171101 |
Group By语句优化
合理安排Group by语句中字段顺序对性能有一定提升。将Group By语句中字段按照每个字段distinct数据多少进行降序排列。
1 | [GOOD]: SELECT GROUP BY uid, gender |
Order by时使用Limit
Order by需要扫描数据到单个worker节点进行排序,导致单个worker需要大量内存。如果是查询Top N或者Bottom N,使用limit可减少排序计算和内存压力。
如果要order by获取top100,第一种:不limit,获取全局有序的数据集,则会把所有数据放在一个worker里,对单台节点造成较大的压力,最后再获取前100。第二种:采用limit取前100,则会并发执行多个worker,分别取这些worker里的前100,再放到一个worker里去进行取top100。
1 | [GOOD]: SELECT * FROM tbl ORDER BY time LIMIT 100 |
使用Join语句时将大表放在左边
Presto中join的默认算法是broadcast join,即将join左边的表分割到多个worker,然后将join右边的表数据整个复制一份发送到每个worker进行计算。如果右边的表数据量太大,则可能会报内存溢出错误。(类似mapjoin,缓存小表去join大表)
1 | [GOOD] SELECT ... FROM large_table l join small_table s on l.id = s.id |
注意事项
字段名引用
避免和关键字冲突:MySQL对字段加反引号`**、**Presto对字段加双引号分割
当然,如果字段名称不是关键字,可以不加这个双引号。
时间函数
对于Timestamp,需要进行比较的时候,需要添加Timestamp关键字,而MySQL中对Timestamp可以直接进行比较。
1 | /*MySQL的写法*/ |
不支持INSERT OVERWRITE语法
Presto中不支持insert overwrite语法,只能先delete,然后insert into。
PARQUET格式
Presto目前支持Parquet格式,支持查询,但不支持insert。
