
JVM入门到放弃之基础篇
JVM成神之路—凡人篇
从官网开始学习JVM
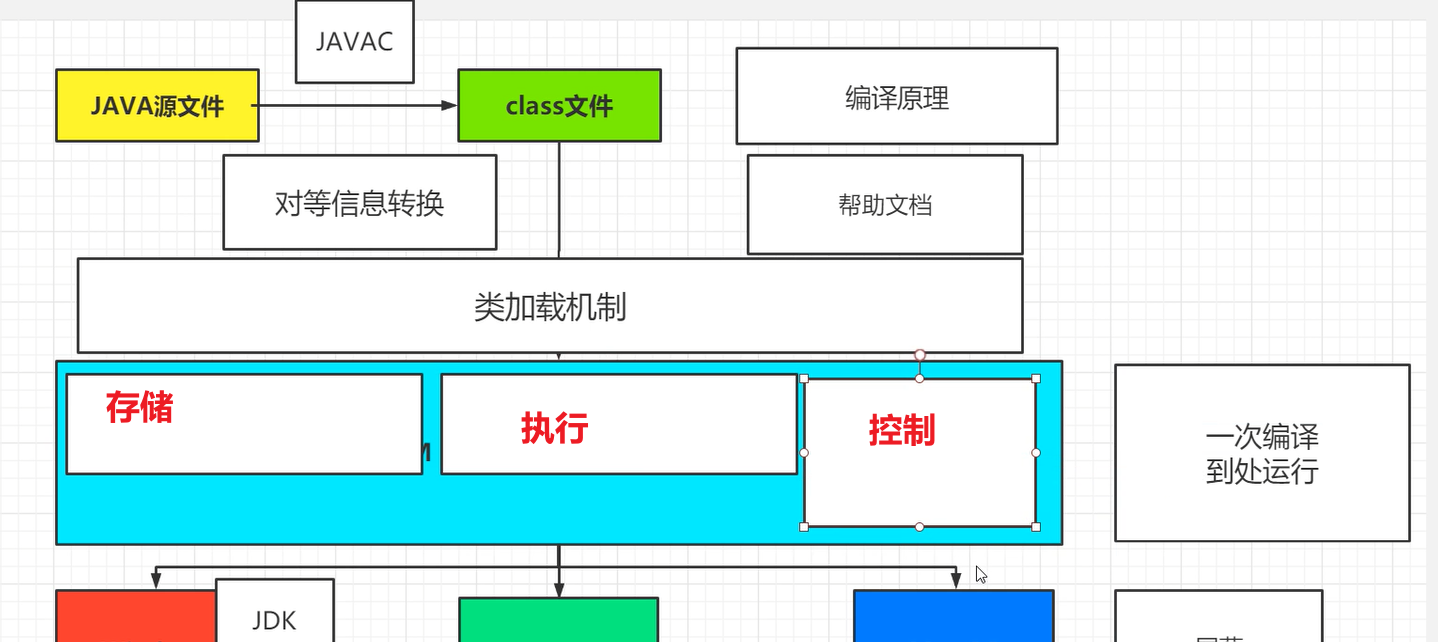
Java编译流程简介
java源文件由javac编译器编译成class字节码文件,然后交给JVM去执行,目的是为了实现跨平台,能够跑在装有不同操作系统的机器上面。不管操作系统是什么类型,其底层的支持都是硬件,而硬件只能识别0101这样高低电频的机器码。(0为低电频,1为高电频)
自从电子计算机诞生以来,经过晶体管再到集成电路和大规模计算机,他们能识别的就只是0101这样的高低电频的机器码。不同操作系统对源码解析的情况可能不同。
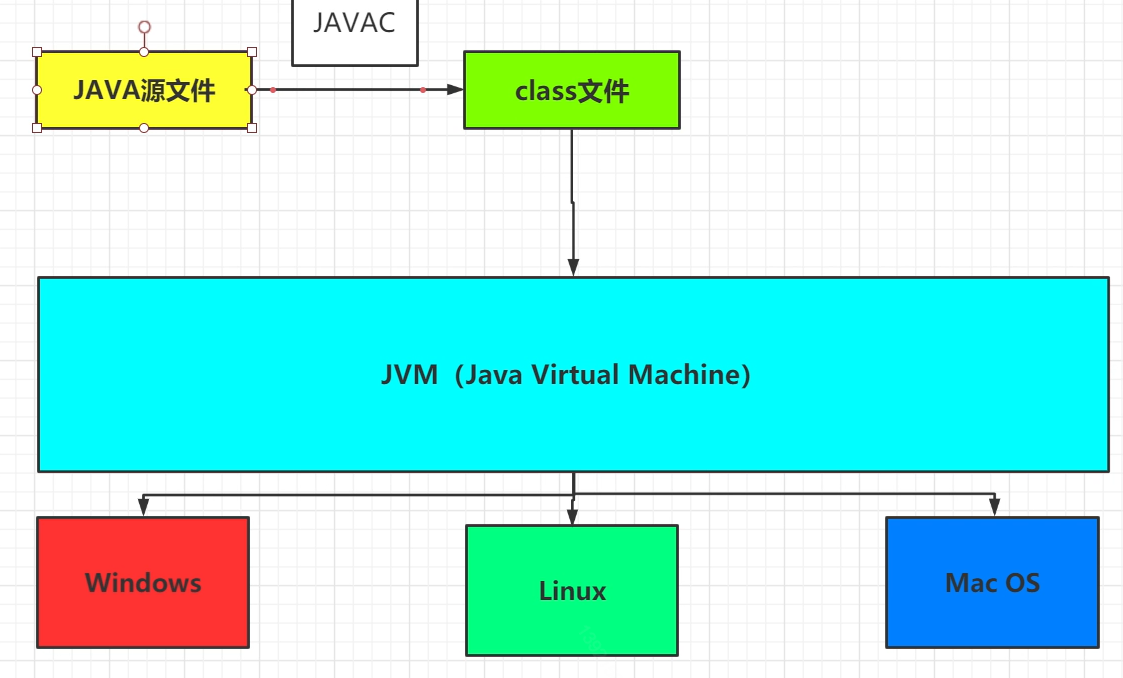
为了让Java源文件跑在不同机器码的平台上,因此通过JVM去屏蔽不同的操作系统,通过JVM的适配,不管你原操作系统解析是怎样的,Java程序归根结底是跑在这个机器上,使得Java实现一次编译到处运行。
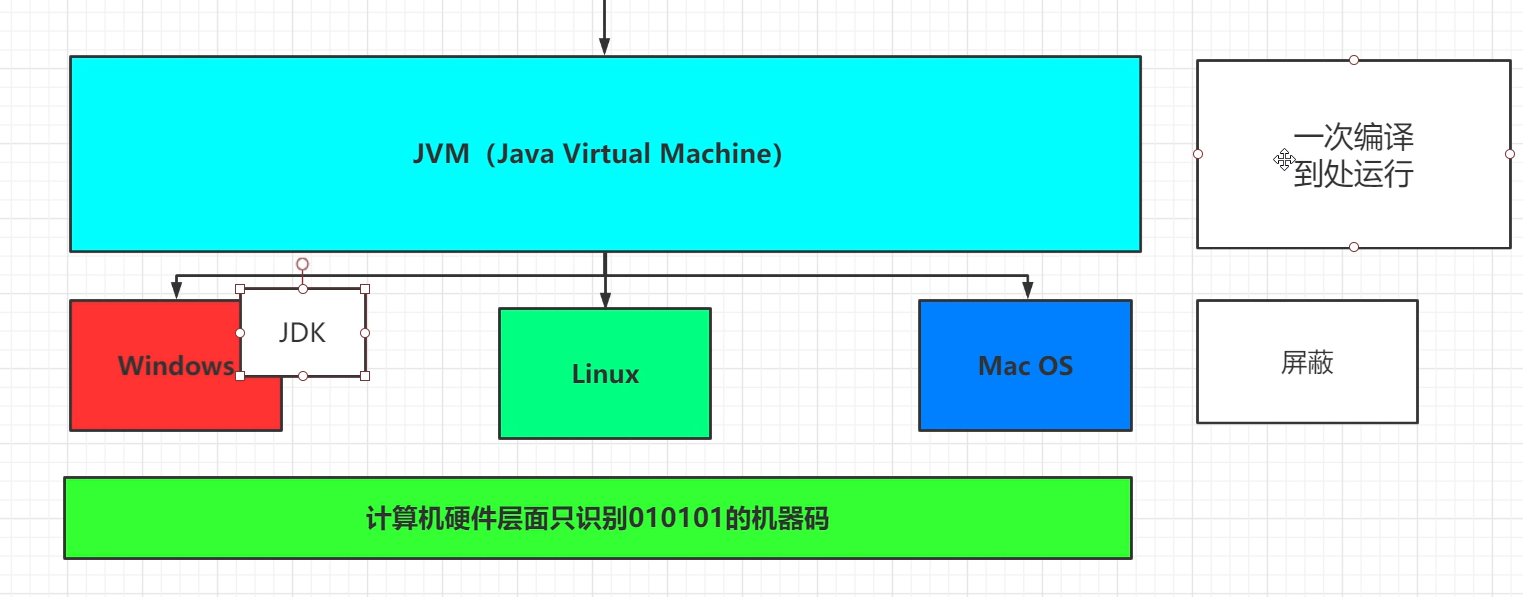
我们下载Java时,会发现下载的都是JDK,我们由此可以推断JVM是包括在JDK里的。
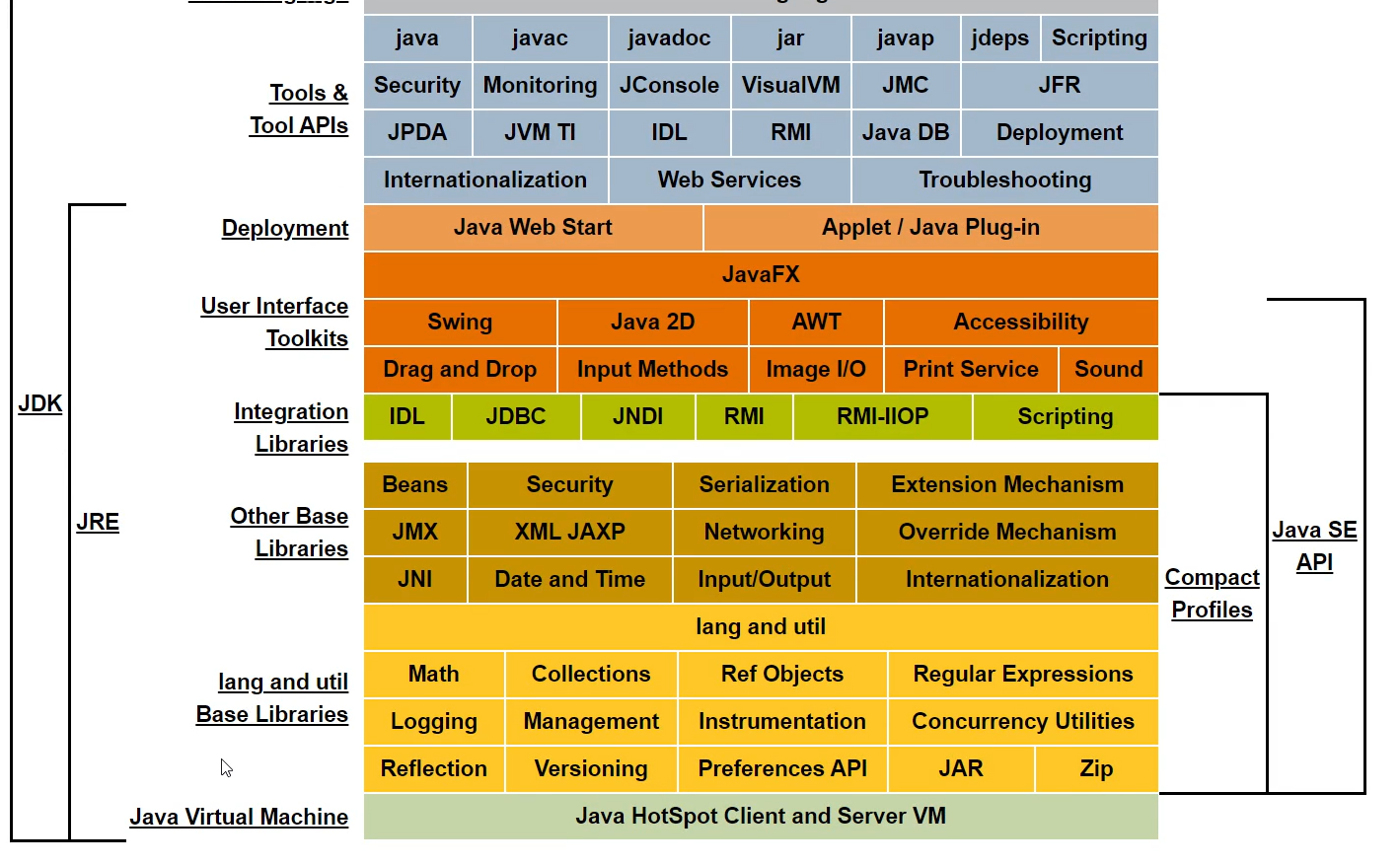
在JDK里会有Tools和Tools API非常多的工具集,这些工具集是帮助进行开发的。而JRE的作用是帮助我们去运行class文件。而最底层的支撑就是JVM,也就是虚拟机。
JVM是最底层的,与操作系统打交道。上层是个运行环境JRE,再上层是帮助开发的一些工具API。
JVM有不同的版本,目前最主流的是Sun研发的Java HotSpot Client and Server VM。

Javac仅仅是把java源码格式编译成.class字节码文件,只有字节码文件才是JVM能认识的能跑的文件。这就好比播放器支持MP4的视频,但是你的视频是avi的,这时候你会去找格式工厂去将avi转成mp4格式的。只是转格式并不会改变文件的内容。简单来说,javac将java源文件转成class字节码文件,是对等信息转换。那么这个对等信息转换是怎么做的?
我们来借助编译原理的书来进行分析。
如果想对Java源程序语法或格式进行格式转化,首先要知道java的语法结构,然后才能对Java语言源文件进行语法分析,之后进行词法分析,分析完后,需要找一个结构将分析完后的文件进行存储,比如用树这个结构来存储,生成一个对应的语法树。(语法树、抽象语法树、注解语法树)
最后,存储起来后,再对语法树进行语义解析,分析每一个词的意思然后转换成我们的一个class文件这样的格式。解析完毕后再用对应的生成器(要转成class文件用class字节码生成器),来生成对应格式文件(.class)。
以上就是编译原理中介绍到的。我们甚至可以根据这样的解析,定义对应的语法,有对应的生成器,生成其他的语言都可以!
Java字节码文件分析
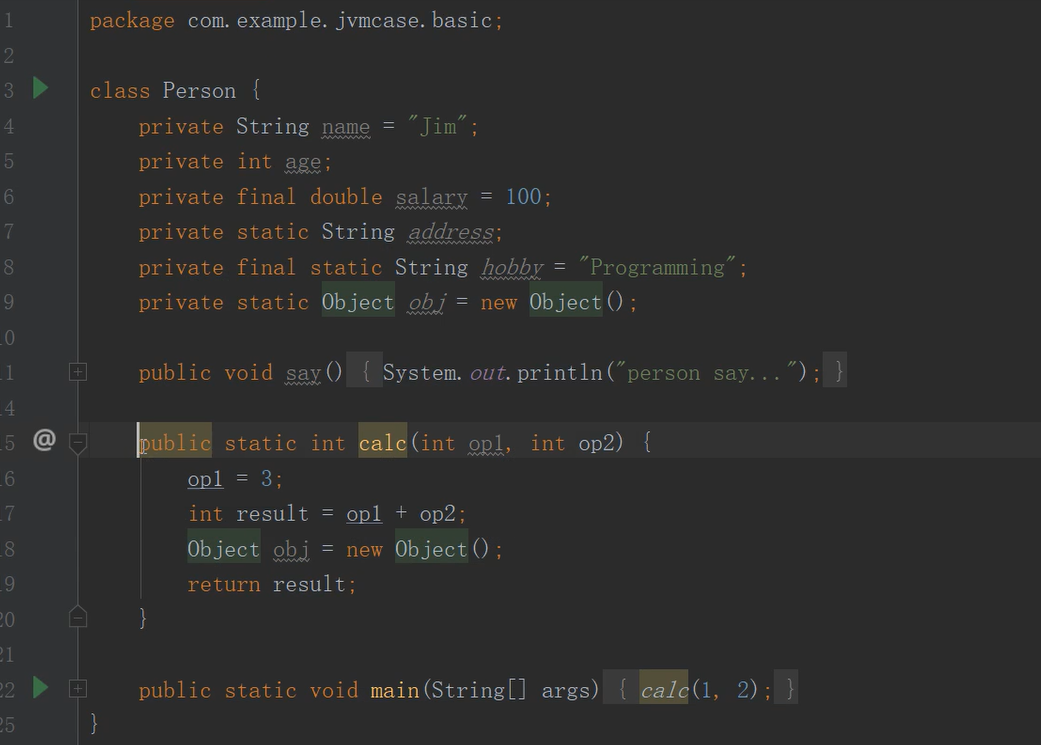
那么接下来我们用Javac编译器对Java源程序进行编译,查看生成的class文件。
Java源文件:
Class文件:
我们可以看到一堆乱码,这个时候可以通过官方文档去解读。
打开Javase开发帮助文档,可以看到有很多版本的Java SE。
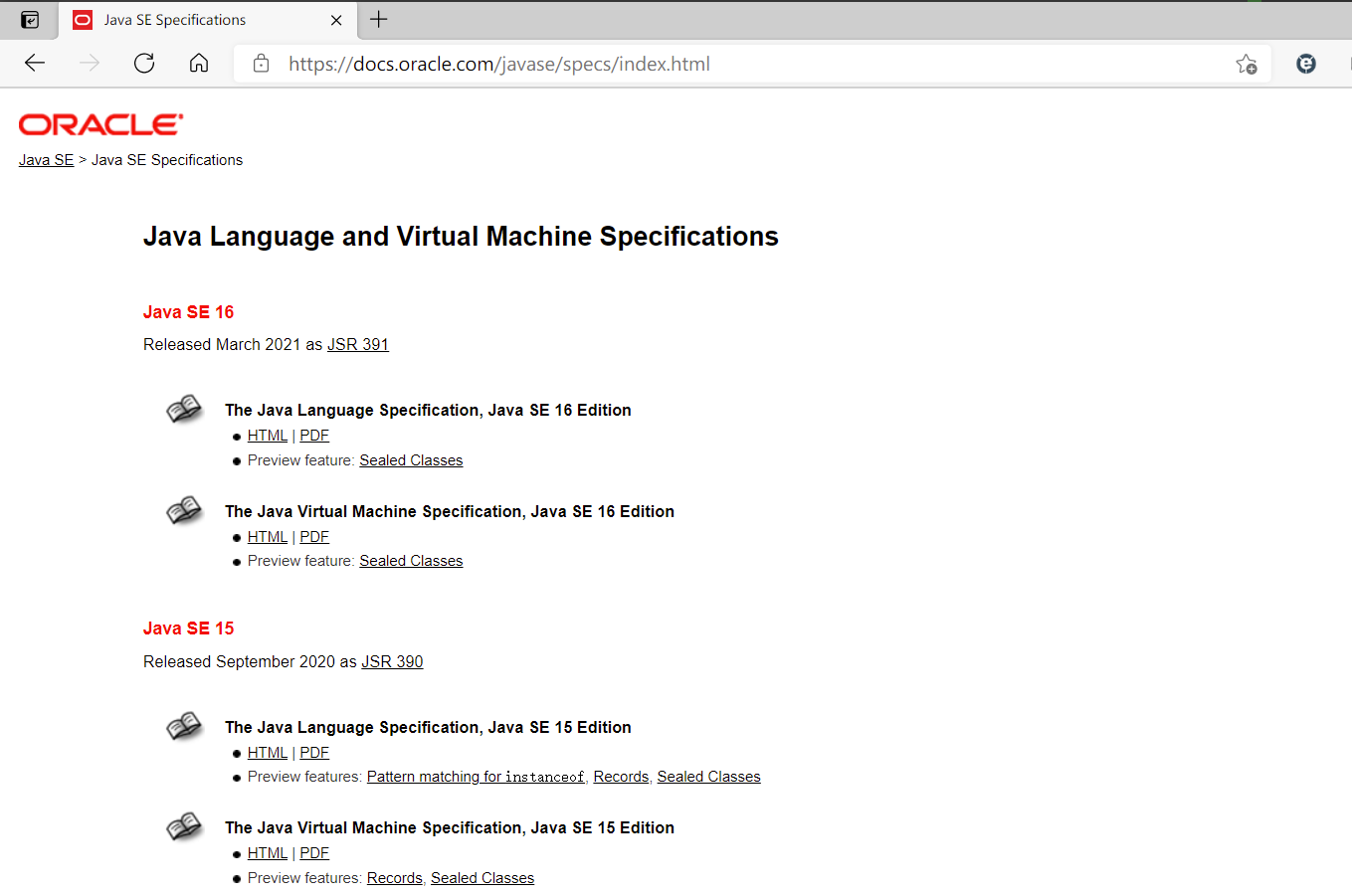
目前生产环境上,最新的稳定版是Java SE11。(稳定版还有JDK7、JDK8)。但是不建议将JDK11运用到生产环境上。因为JDK11太吃内存,公司经济能力使用不起。一般公司使用的是JDK8。
JDK11要求通用服务器得是8核16G以上的程度,也就是要配16核,32G的才能跑的起。
而JDK8,2核4G甚至1核2G的服务器都可以运行。
我们继续查看字节码结构文件帮助文档:
Class文件的范式:
范式里罗列了class文件应该有的东西,这里面的就是上面那一串的乱码的内容。

我们利用插件,将class文件转成16进制可以看到,变的可读规范点了,对应的就是右边一列乱码文件。
对比官方的class文件结构,我们可以看到class文件开头规范是magic:
The
magicitem supplies the magic number identifying theclassfile format; it has the value0xCAFEBABE.魔术项目提供用于标识类文件格式的魔术数字; 它的值为0xCAFEBABE。
即是以16进制的CAFEBABE标识开头的。
minor_version:最小版本数
major_version:最大版本数,指java的

constant_pool_count:指常量池的元素个数,这里是3A,转成十进制就是58个。但是回去看java源文件一共才25行,就算全都是常量也不到58。
可以看到Javac对Java源文件文件进行了一个转换,变成了结构化的class file。
常量池放了啥

上面可以看到常量池里存放的东西介绍,这里我们分析下:

什么是符号引用?
这里先简单说一下,假设说下面是 一个方法,是java语言的一个方法,我们知道它是java语言的方法,而这个方法没有任何定义,仅仅是我们将它叫做方法,而在源码文件中,一定有一个定义去告诉别人,这是一个方法,不然无法对其进行解析。而我们的符号引用,就是存储这些所谓的描述信息。

从类文件到虚拟机
在上面,我们分析了Java源文件到class字节码文件的过程,那么接下来我们就来继续分析字节码文件放到JVM里面去进行数据的流转,将class文件的信息解析出来,一条条放入JVM中去进行流转。
Class文件如何在Jvm中流转?**
class文件如何交给jvm呢? 这就需要一个叫类加载机制的东西了。
JVM如果需要将数据加载到内存,我们访问这些数据必然存在一个入口或媒介来访问这些数据。类加载机制是不属于JVM内的一个内容,因为类加载机制只是将字节码文件放入到JVM中。严格来说,类加载机制是游离在JVM之外的一个代码片段。
我们继续去JDK文档找类加载机制内容来学习。
Loading、Linking、Initializing(装载、链接和初始化)
装载
类装载器介绍
从装载到初始化,就是一个类加载机制,而下面的整个流程就是类的一个生命周期。
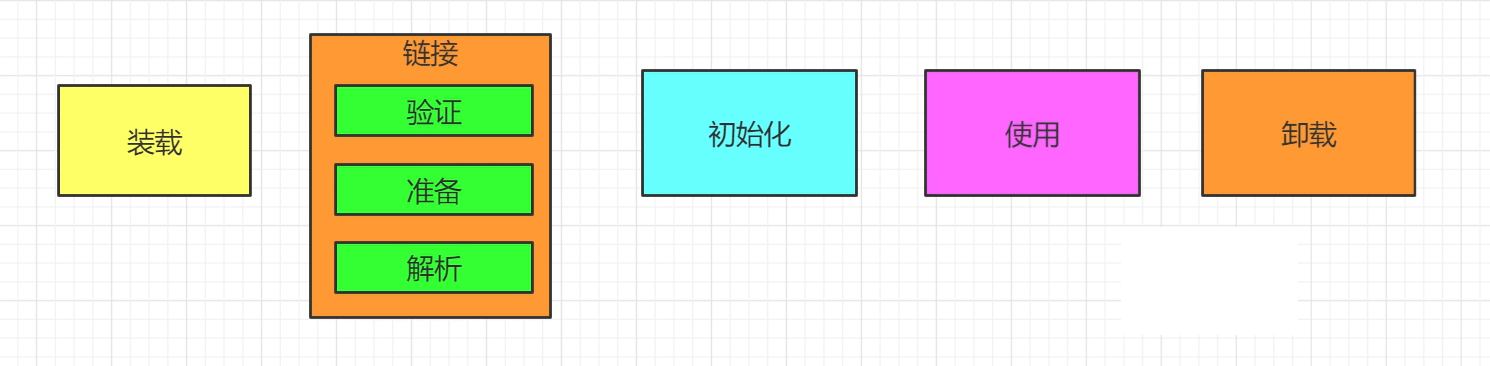
当然如果直接回答类加载机制就是装载、链接、初始化未免显得有点枯燥和单调了,对你的入职薪资影响也很大,所以我们可以说的生动点:
一个class字节码文件要加载到JVM中,需要读文件。读文件的第一步就是将Class文件打成字节流,然后通过一个寻找器找到字节流。java当中就有一个特定的寻找器,叫做类加载器。
class文件在JVM中的流转
找到流之后,将流的内容提取出来,在JVM中进行流转。那么这个过程是怎么设计的呢?
我们来看看Java的JVM文档。我们来看看图中第一二段的第一句话,分别说了:1.JVM是Java平台的基石;2.JVM是抽象的计算机;

JVM是一个抽象的虚拟计算机,只要是计算机就要遵循冯诺依曼计算机模型体系。对比来看,对于JVM来说,输入无非就是类的加载,而输出就是输出成机器码,在硬件平台上进行run。
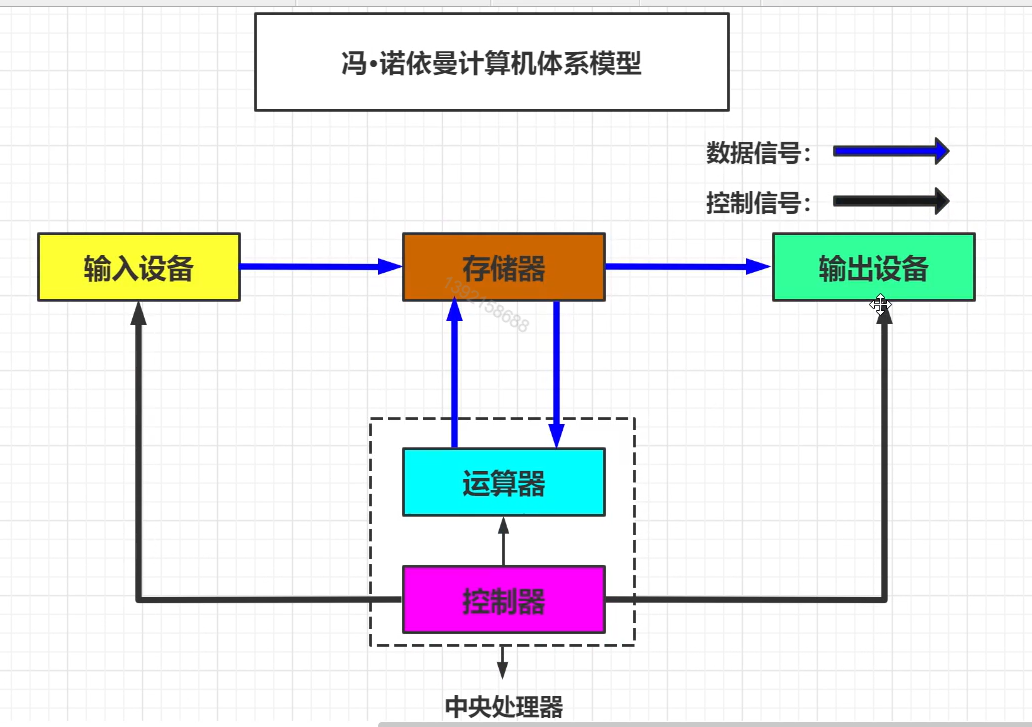
这里我们分析输入,数据输入进来后,就需要有一个地方存储,存储完成后还需要有一个地方进行执行、流转、运算。所以说,JVM内存不应该是一个单单的内存,还要有一个存储单元和执行单元。
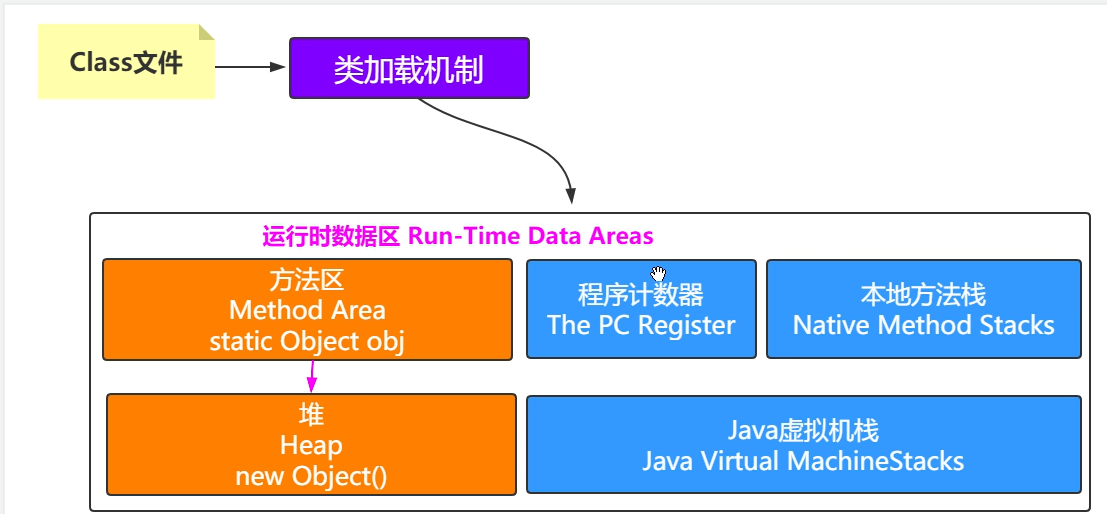
所以,JVM在运行时,必然会有这么些区域,对数据进行存储、执行、控制等等进行操作,这些操作只有在JVM运行时才会进行,因此我们可以将这个区域命名为运行时数据区。
接着,我们来分析JVM是java平台的基石这句话。一看到基石,就要想到可拓展性!就比如Spring是Spring系列的基石,Spring系列都是基于Spring拓展出来的。JVM是Java平台的基石,它作为一个基石,中间留了很多的接口,允许其他语言使用,比如scala等。
运行时数据区
我们来猜一猜运行时数据区有什么?
方法区
我们先来看看Java的Person类源文件:
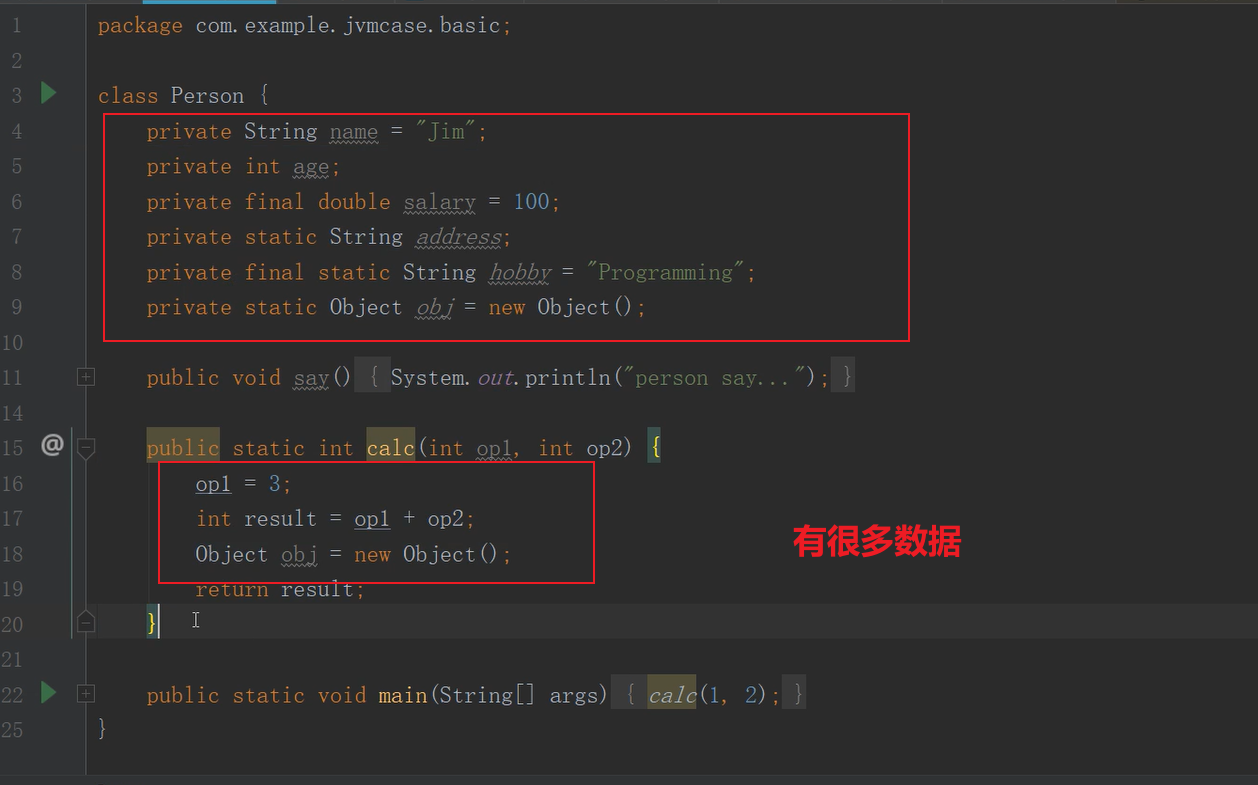
可以看到,源文件中有许多的数据要执行,这些数据一开始并不需要进入运行时数据区。对于整个的class文件,我们用一个评判标准,什么时候是装载进来了呢?
一定是有一些模板信息装载进去了之后,就算这个class文件装载进来了。而它的业务数据装不装进来后续再说。所以,这个时候我们需要对模板数据划分一个单独的区间来进行存储。这个区间就叫做方法区。方法区专门用来装载一些模板数据信息,比如说静态的数据,包括类的模板数据(比如类信息)。
堆
对于堆,我们举个例子,就好比一个人有年龄、身高、地址、类等信息,我们通过这些信息就能定位到你这个人,而这个人是不会住在这些信息里的!所以,我们将这些模板数据存放在方法区当中。
Java是一门面向对象的开发语言,既然它是面向对象的,那么万事万物,所有对象的创建也需要一个区域对它进行存储,所以说,同时我们对象也是业务产生的数据,需要单独的划分出一个区域进行存储。这个区域我们采取一个特殊的数据结构进行存储,用堆(heap)进行存储。
那么这个时候,我们装载下面要做的事情就很简单了,我们就从字节流拿信息,将字节流当中代表的静态存储结构转化为方法区的运行时数据结构。这也就将类当中的信息存入了方法区中。当然,类信息放入到方法区不能算是将class文件装载进去了。
因为我们仅仅是将一堆数据放入了“数据库”,但是我们无法拿到它们,无法访问。所以,这个时候,我们还要给它开一个入口,就是数据访问的入口。而这个数据访问的入口,Java是通过什么来访问这些数据?
通过一个对象,才能访问到这些数据,因为java是面向对象的语言。所以,每个类就会有一个特定的对象,叫做Class对象。所以,我们做的是在堆中生成一个代表这个类的Class对象,作为方法区的数据访问入口。
这个时候,我们才真正的把class文件给装载入JVM中。
至此,这三个过程才代表装载:

链接
验证
装载完成后,我们的下一步就是链接,而链接又分为验证(验证类的格式是否正确,文件格式是否正确,元数据是否正确,字节码是否正确,符号引用关系是否正确,即文件不能有问题)、准备、解析。
- 一般文件格式是否正确,我们在class文件进入JVM时就需要验证文件格式是否正确。
- 元素据是否正确,只有当用到这些数据才能确定。
- 字节码是否正确,只有需要去解析的时候才能判定。
- 符号引用关系是否正确,需要到用到符号引用的时候才能判定。
总的来说,链接虽然是验证放在第一步,但是在整个过程当中,都在执行验证这一步,验证并不仅仅是执行一步,它跟我们整个流程是并行的。
准备
对于准备阶段,官方描述:为类变量(类的静态变量)分配内存,并且初始化为当前类型的默认值。
例子:private static int a = 1;这里我们写了一个静态变量,这个静态变量在准备阶段赋予一个默认值:a = 0,让它提前去占用这块内存。(int 类型默认值是0,String类型默认值是null)。
解析
解析阶段是面试最常问的,我们要多看官网!!!
这句话的意思是:符号引用转变成直接引用。之前符号引用是在常量池中,我们对于符号引用的描述是:接口、类、方法、字段这样一些元素的描述信息。而在我们解析阶段,符号引用变成了直接引用。
为什么会变成了直接引用呢?我们这里进行反编译一下,将编译生成的数据写入到a.txt文件当中。
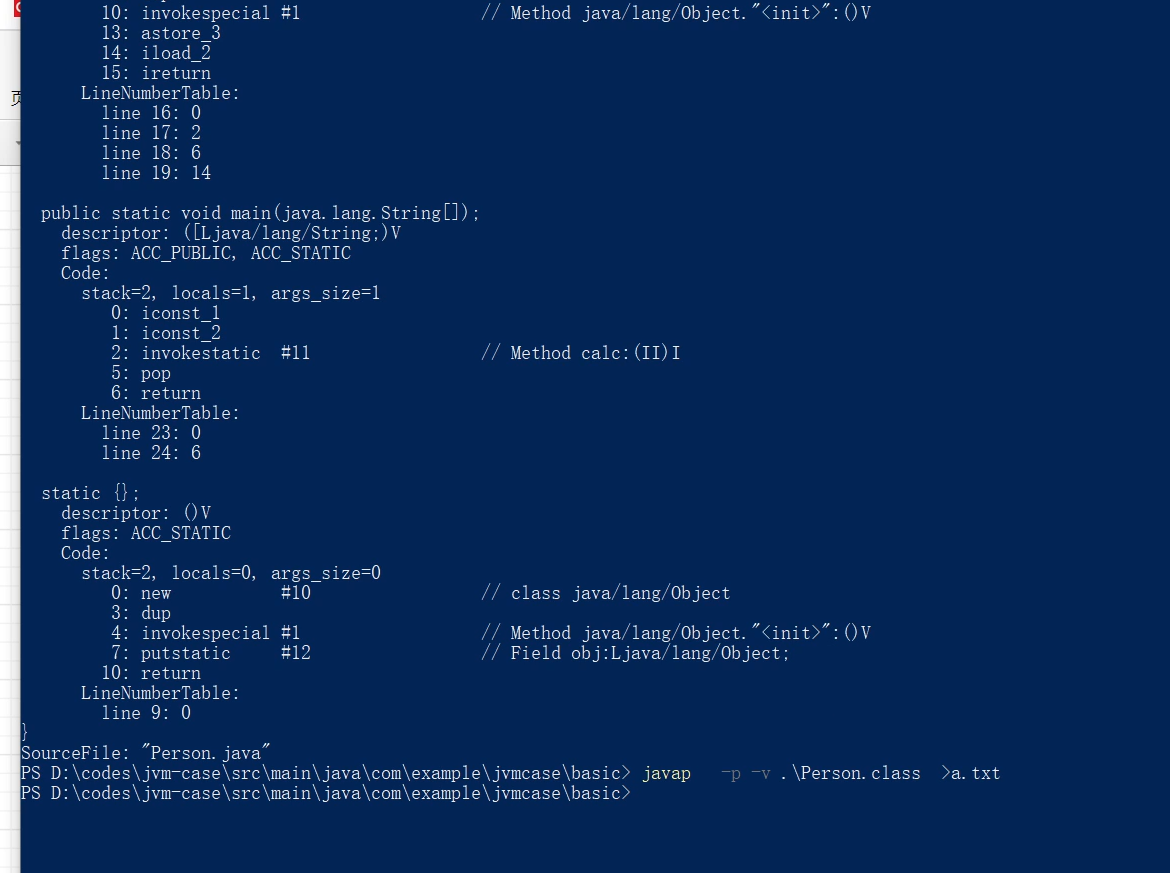
可以看到文件内容,发现常量池中也有很多这样的符号引用。
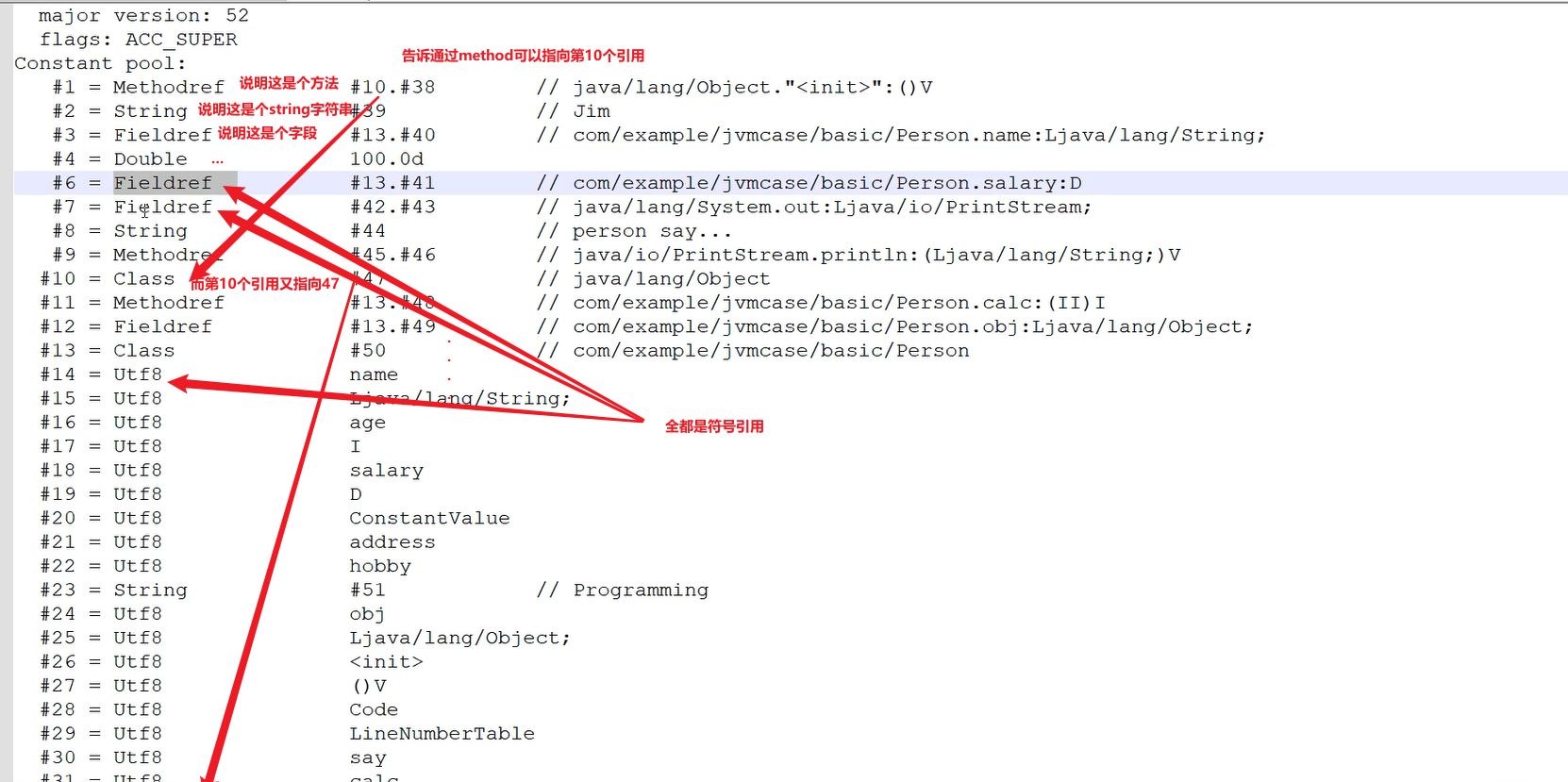
这个时候,我们将符号引用转变为直接引用代表什么?
首先,这一系列的符号引用都是在字面上的,我们的符号引用需要真正的去加到物理内存当中,给它一个真正的物理地址。这就是所谓的一个解析。将字面上的符号落到物理内存中的一个过程就是解析。
举个例子来理解:假如你在网上刚交了一个女朋友,这个时候你是网恋,你没见过她人,可能你聊的对象是一个抠脚大汉,在商量着如何杀猪盘。因为你不知道那个微信后面代表的到底是谁,你有可能被坑。这就是符号引用。
而直接引用就是,比如你和她见面,见到了发现是一个女孩,这个时候你才正真认识她人,真正的指向了那个人,这就是符号引用真正的变成了直接引用。
也就是这个符号引用,所谓的描述,可以真正变成直接引用,指向一片物理地址,而那片物理里地址,代表的就是method。
初始化
初始化整体描述,它就是执行了一个Clinit(class initial),类初始化的方法,而这个时候我们会给静态变量赋值,同时初始化静态代码块,还会初始化当前类的父类。
类加载机制到类加载器
ClassLoader 类加载器
类加载器怎么去加载类呢?
假设存在这个ClassLoader,我们自己定义了一个java.lang包下的一个String,已知java.langString原始时.rt包下的,这个时候,类加载器会怎么加载呢?
首先,类加载器会优先去加载源码包里的java.lang.String,源码包里没找到才加载我们自己定义的String。那么这个怎么实现呢?
我们通过多个层级的加载器,在类加载器这块就进行了一个优先级的划分。类加载器有四个层级:
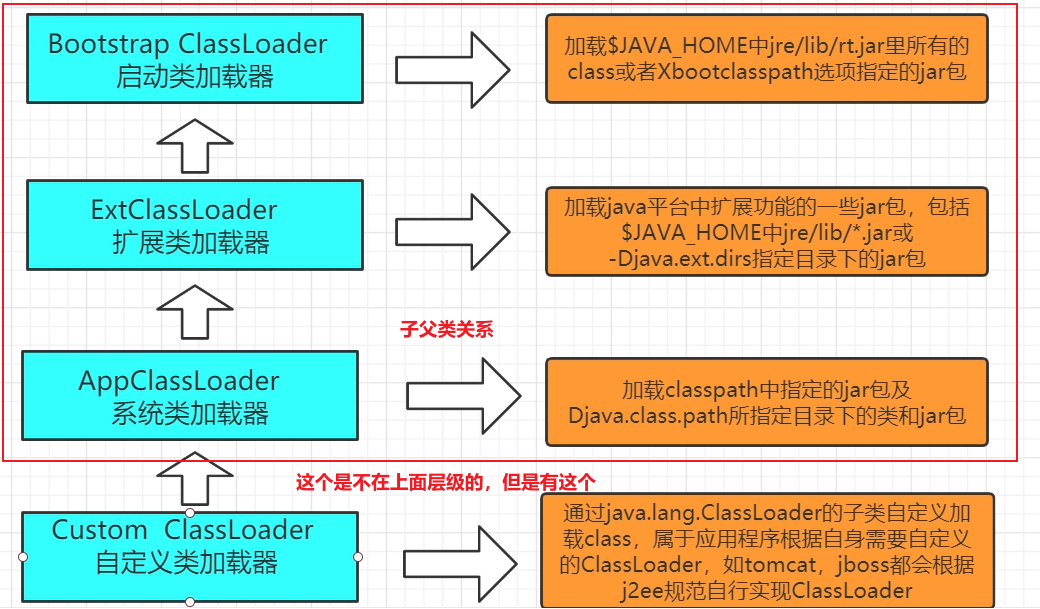
我们的Boostrap类加载器加载的是.rt包下的内容,而且它是由C语言编写的,所以我们在Java里是看不到它的。
而自定义类加载器是不属于这个层级之类,之所以放进来是因为确实有这个自定义的功能在。不属于这个级别划分范围之类。
这个时候,我们来看下源码,看它是如何进行加载的。
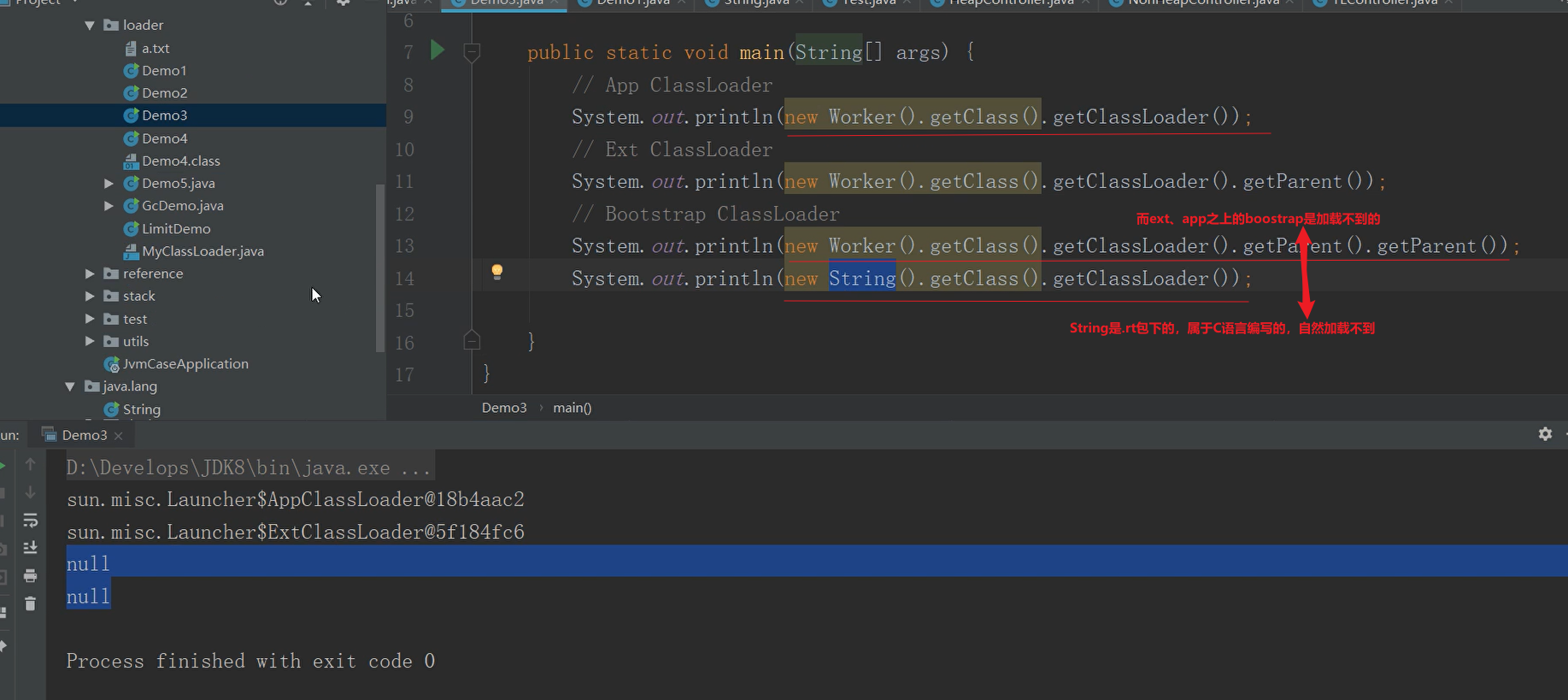
上面所展示的,就是我们所说的双亲委派,也叫做父类委托(更贴切点)。
我么来看一下ClassLoader的源码:
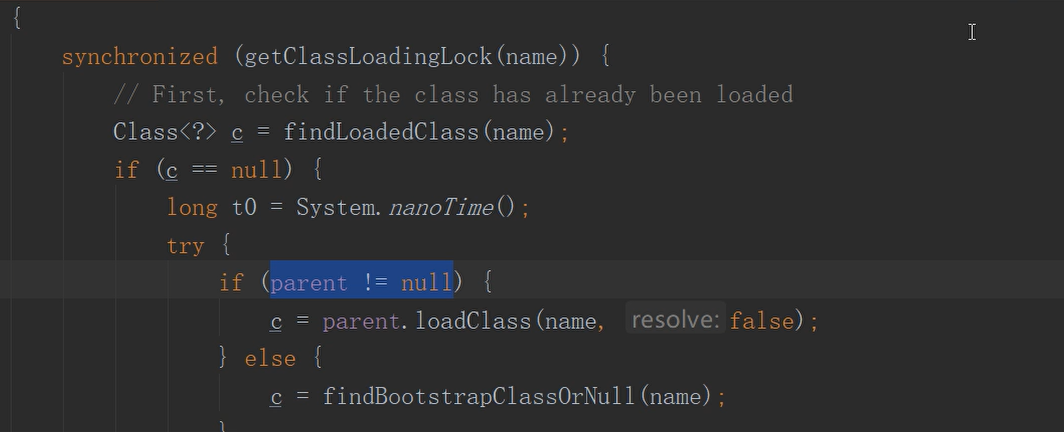
可以看到里面的loadClass方法里面有个找parent父类的情况,而父类又会递归调用自己,这里顶多调用两级到bootstrap,只要这个String最顶层有,就不会去调用下级的。永远只会加载层级比较高的。这就是所谓的双亲委派机制(双亲指最多只能调两层,其实父类委托才准确点,永远委托父类)。
那么我们如何打破这个机制呢?比如说我们不想找业务,只想找自己。有两种方式:
- 我们可以通过自定义类加载器,去复写类加载器(复写classloader或删除loadclass这段代码,使它调用自己)。
- SPI(Service Provide Interface)服务提供接口,比如说JVM的规范会非常复杂,我们能做的就是把JVM复杂的规则给定义的简单点,把JVM提供的接口自己去实现。
- OSGI,就是将代码进行模块化,一个模块就用一个类加载器,当这个模块不再使用的时候,我们将这个模块和它的类加载器统一卸载。这种方式是为了实现热部署(但是java自身不太支持热部署)。
运行时数据区
运行时数据区分区
至此,我们的类加载过程已经讲完了,接下来就是把数据放进运行时数据区进行存储。运行时数据区一共被划分成了五块:
- The PC Register(程序计数器)
- Java Virtual Machine Stacks(Java虚拟机栈)
- Heap(堆)
- Method Area(方法区) 方法区内包含了Run-Time Constant Pool,即运行时常量池,属于类信息一部分,放在方法区中
- Native Mrthod Stacks(本地方法栈)
方法区
我们来看看我们的方法区,可以看到,我们的线程是共享的。也就是说,生命周期与进程相绑定。里面装载着运行时常量池、字段和方法的数据和一些结构方法。如果内存不够,我们会抛出Out Of Memory。

堆
堆是运行时数据区分配的最大内存的地方,数组对象之类的都在堆中。堆的内存不足也会抛出OOM报错。

栈
方法区和堆是线程共享的。而程序计数器、本地方法/java虚拟机栈三块不一定是线程共享的。
java实际是一个进程,它的中间会有很多线程存在。在Java中,线程是帮助去执行方法的。那么线程去执行方法该怎么表示?
其实,每一个线程有一个执行方法的数据结构,我们将它称之为栈。先进后出,后进的先出。在Java中,方法分为两类:
- Java方法
- Native方法
也因此,栈也会被划分为两类。虚拟机方法栈执行的是java方法,本地方法栈调用本地方法,两者都是调用执行方法。
我们继续分析,方法调用的数据结构有了,每个执行的方法被压栈进去,那么方法的基本单位是什么呢?我们称之为帧。那么现在,我们一个栈帧就代表了一个方法的执行,也就是一个方法的Invoke。
通过下面的文档可以看到,java虚拟机栈是线程私有的,一个java虚拟机栈存储多个栈帧。同时,栈的内存不够也会抛出一个异常,叫StackOverFlow,即当栈的内存设置不够,压方法深度不够,就会报上面的错误。

The PC Register 程序计数器
我们继续分析,假设我们有两个Java虚拟机栈,线程方法要获得CPU的执行权,需要靠时间片的轮转,靠CPU的调度算法,也就是靠抢占CPU时间片轮转,也就是CPU自己调度分配的。其实,线程并没有主动争抢的权利。
这就会出现一个问题,比如说一个方法正在执行,执行到一半,另一个线程方法抢占到了CPU的时间片轮转,执行完后后再继续执行原来的方法,这个时候在线程来回切换当中,我们如何确定原方法执行到哪儿呢?
所以我们需要再线程当中维护一个变量,记录我们线程执行到的位置,这个就是程序计数器。
Java的虚拟机栈一次可以支持多个线程,但是每个Java虚拟机栈的线程,都只能拥有它们自己的程序计数器。

本地方法栈
继续看,通常会在创建每个线程的时候,为它分配一个native mthod stacks。也就是线程私有。

栈帧解析
这个时候我们来分析下,整个运行时数据区,我们能够聊的也就只有栈的栈帧frames和堆的heap存的对象和heap结构。
我们先来看看Frames中的内容,可以看到一个栈帧存放了局部变量、操作数栈、…、附加信息这些数据。
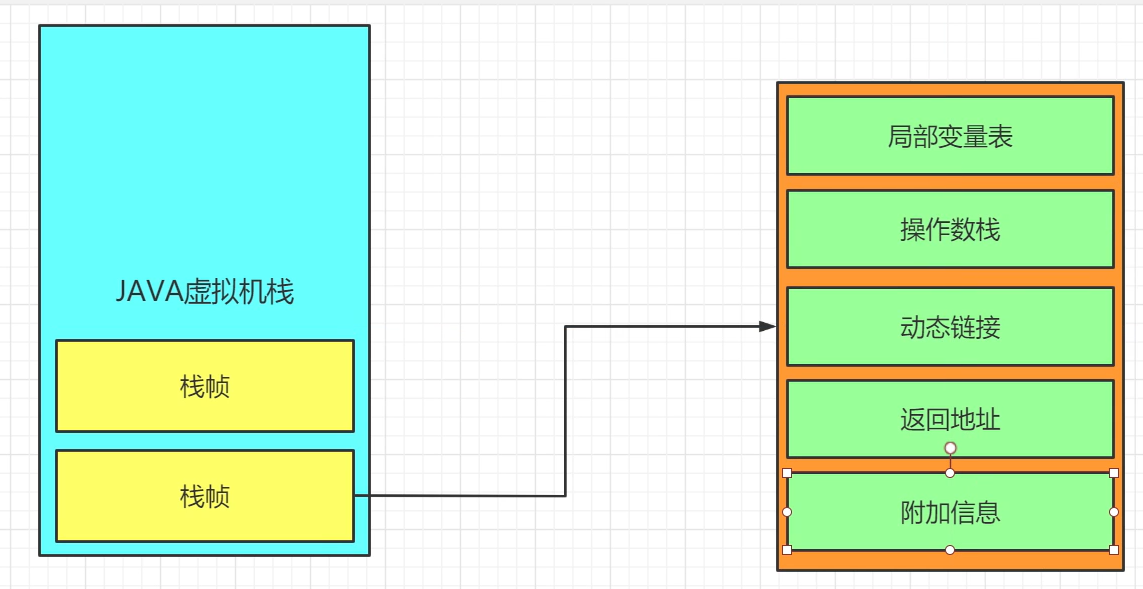
局部变量
局部变量表存放的是局部变量,是一个存储单元。(OOM不一定是堆,也不一定是方法区,还可能是栈。对象可以在栈上分配和逃逸)
操作数栈
操作数栈是执行单元,假如说a=1,b=1, c=a+b,其中a、b是局部变量存放在局部变量表中无法执行,而c放在数栈中,会将a和b的值拿到操作数栈进行计算后返回到局部变量中。
返回地址
返回地址,就是写方法的时候我们需要有一个return,return到哪个地址。分为两种,正常返回和异常返回。
正常返回是遇到返回的指令,记录下地址正常返回。而异常返回, 要分情况。首先看有没有全局异常处理器,如果有就跟着全局异常处理器走,如果没有,就会抛出异常。
附加信息
附加信息代表的是栈帧当前的版本、栈帧的高度等等一系列的附加信息。
动态链接
动态链接、返回地址和附加信息三者加在一起叫做栈帧信息。
动态链接是方法的符号引用变成直接引用。

假设这里有两个方法,我们会用方法a去调用方法b,这里b类可能是一个抽象类,它会有c和d两种实现。所以,在前期的装载阶段,不好判断这个b调用了c还是d。只有在方法的实际运行当中,我们才能知道调用的是哪个,这个抽象类是委派给哪一类的。
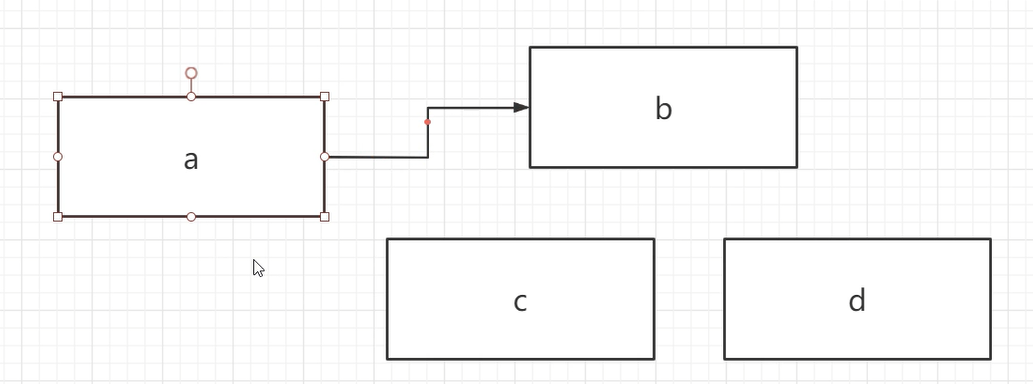
这就相当于委派模式。这是由于Java多态的存在,很多东西都需要运行了才能确定。这里可以结合Spring中的XML和BeanDefination来理解。
总的来看,方法区和堆是和进程相关的,而程序计数器、本地方法栈、Java虚拟机栈是和线程相关的,和线程相关的生命周期相对来说会比较短,存在的可能性不会太长。
所以,只要类文件、源码文件写好了,生成了一个class文件,那么右边蓝色三块所有内容和内存结构大小基本上就能够确定了。所以我们重点讨论的是方法区和堆。
方法区和堆分析
将方法区和堆进行落地后,结构如下图所示:
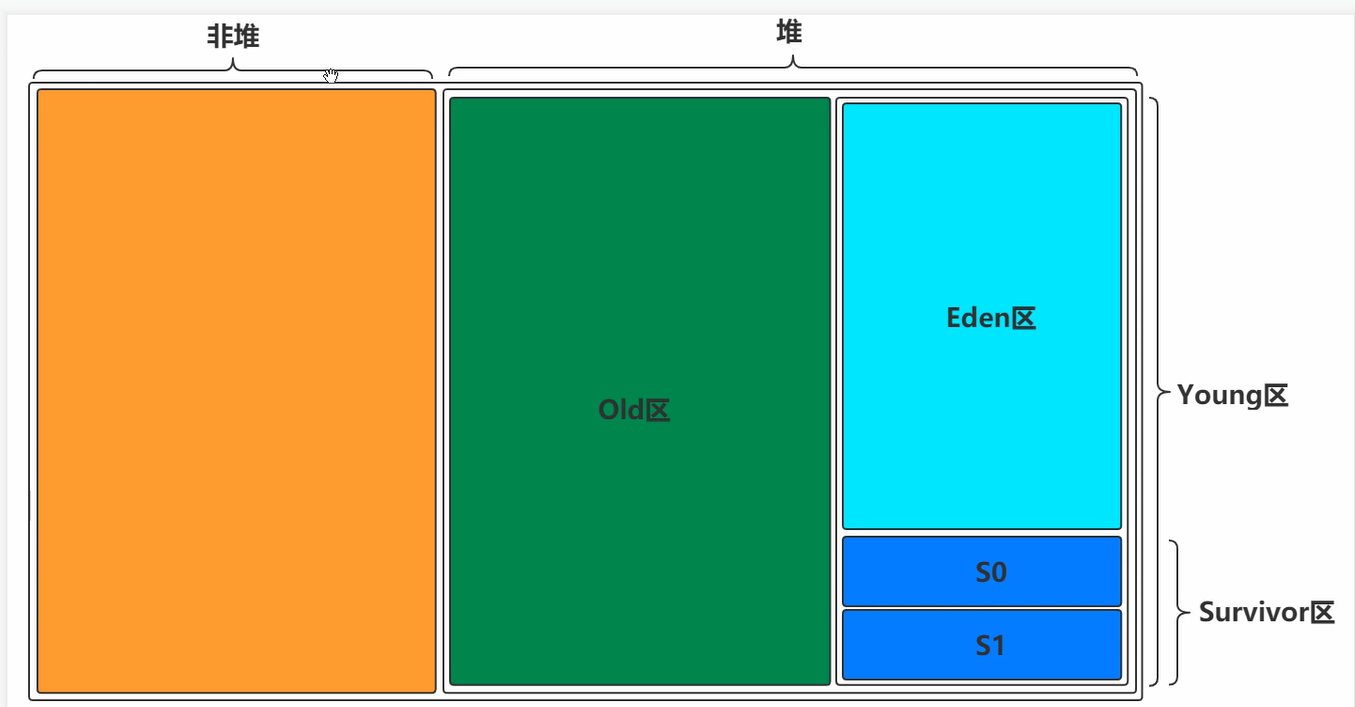
方法区实际上是堆的逻辑的一部分,我们可以将其称为非堆。

对于堆,我们可以发现,它被划分为了Old区和Young区,而Young区又被划分为Eden区和Survivor区。而Survivor区又分为Survivor0和Survivor1。
那么,为什么堆要这么划分呢?
我们假设一下,如果堆就是一整块而不划分成几块可以吗?我们来分析下。
假设堆是一整块,里面分配对象实例和数组,分配满了之后,触发GC去进行回收没用的内存对象空间之后,对象可以继续进入了。可以发现,GC触发是当堆空间满了或达到阈值(比如90%空间满)才触发。
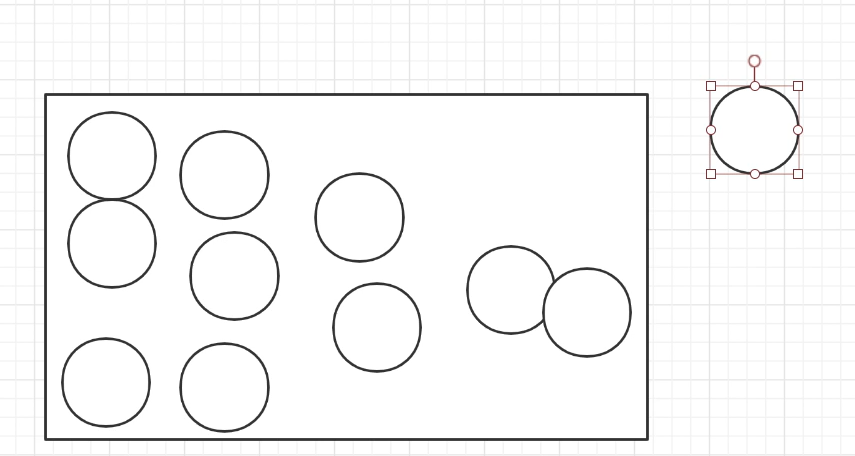
这个时候继续分析,如果堆是一整块空间,那么我们每次GC都要对这一整块空间进行扫描和标记,这样就很浪费性能。对于内存划分,对象会有一个生命周期的属性。根据生命周期的属性来划分区域。有些对象生命周期会比较短,比如说订单对象,订单下完后,这个对象就结束了。据IBM统计,大概有98%的对象是朝生夕死的。
因此,为了提高清理的效率,我们将内存划分为两块,一块young区,存放生命周期短的区域。一块Old区域存放生命周期长的。这样每次扫描的点只有young区这一块区域,只有Old区域满了我们才会去扫描Old区域。而old区生命周期长,等它满需要较长的时间。
所以就只会对Young区进行频繁的扫描,扫描的点没有整个堆内存那么大,提高了效率。
而young区每次GC一次后,我们要对对象划分一个属性叫age,每GC一次,这个age就+1,当这个age达到一个阈值(15),就将对象放到old区。为什么是15呢?
对象当中会有一个专门存储分代年龄的字段,而这个字段长度是二进制的四位,最大就是15(1111)。但是这也存在一些问题,可能存在一些较大的对象,它到不了15就把空间堆满了。这个时候,JVM有一个悲观策略,这种情况下大对象可以直接被放到Old区。常规情况就是age到15才会被放入Old区。
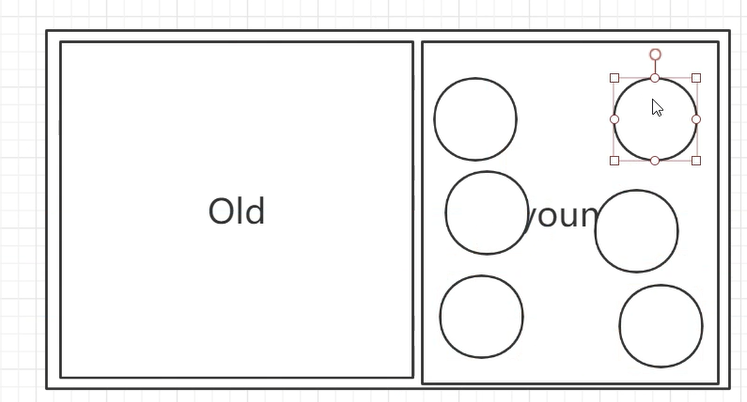
那么,Young区要分为Eden区和Survivor区呢?
假设young区有对象,现在存满了:
对它进行GC后,变成:
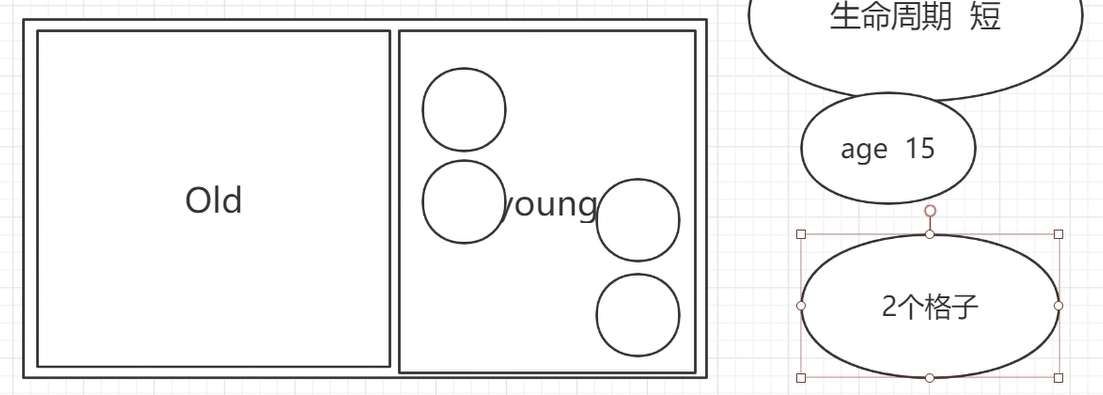
此时,有一个较大的对象来了,但是它进不去young区,因为GC后的young区空间是零碎化的。这就叫做空间碎片。
为了解决空间碎片问题,我们每次GC后,将young区分为两个区域,一块叫Eden区,一块叫Survivor区,只有GC后幸存下来的对象,我们将其放到Survivor区,而Eden区只要经过GC它就变成了一块空的区域。
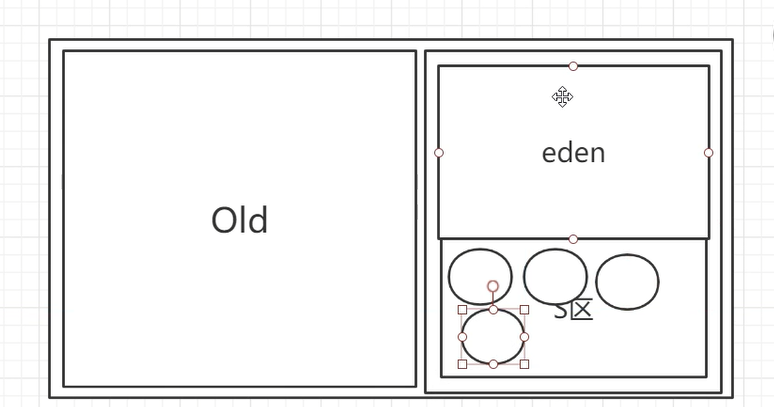
那么为什么Survivroe又分为Survivor0和Survivor1两个区间呢?因为Survivor区也会存在空间不连续的问题。
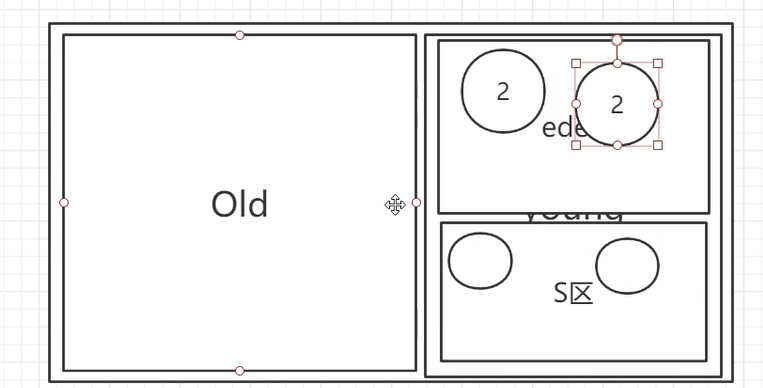
为了解决这个问题,继续将Survivor分为两个区,GC完幸存对象先放在Survivor中的一个区,下次GC完会有新对象进入Survivor区,这时把Survivor0/1区还存在的对象一起放入另一个Survivor1/0区,即来回的在Survivor两个区间倒腾,永远保证空出一个区来解决空间不连续的问题。即用空间的浪费来保证内存的连续性。
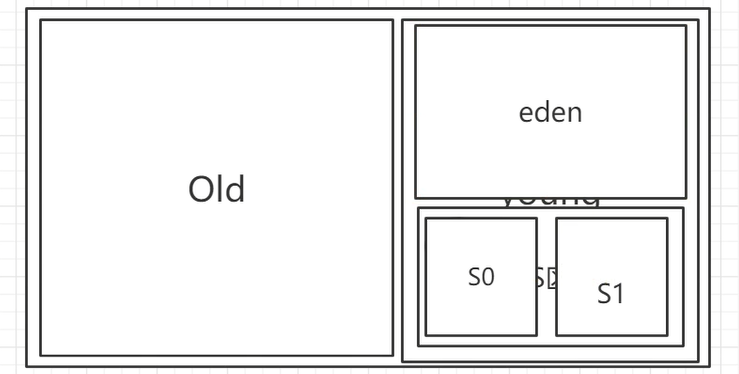
eden区存放新生区,survivor是经历过gc之后才能放入。
那么现在还会有个问题,假设Eden区80M,Survivor两个区分别为10M。这个时候new了一个大对象90M,此时JVM会将这个大对象直接放入老年代,即Old区。这是因为JVM有一个担保机制,当我们young区空间不够时,Old区会为young区进行担保,将大对象放入Old区。Old区的大小是young区的两倍,也就是200M。
而Young区的空间内存比例8:1:1是一个默认的划分。不管什么比例,一定要保证Eden区足够大,如果Eden区不够大就会频繁触发GC去占用线程资源,用线程找到垃圾去清理掉。
对象分配执行流程图
整体流程如对象分配执行流程图所示:

Full GC代表全局GC,相当于jvm整体的内存gc。
Full GC = Young区GC(回收新生代)+Old GC (回收老年代)+ MetaSpace(指代方法区,相当于方法区的一个实现) GC
这里的MetaSpace是方法区的一种实现,方法区只是JVM的一种规范,它有非常多种的实现。在JDK7前,方法区的实现叫做Perm Space(永久代),而JDK8之后叫做Meta Space(元数据区,元空间)。两者区别:
perm space用的是虚拟机自己的内存。
metaspace用的是系统内存。
因为方法区里面装的是类信息、静态信息和常量。这些类的总数和常量池大小和方法数量很难预估出来,所以在JDK7之前想设置我们的参数是很难的。比如说,整一个服务器16G,JVM设置内存2G。如果给方法区设置500M,对于Perm Space,这500M就只能在JVM内存里开辟。而对于MetaSpace,我们可以直接操作系统内存,去系统内存拿空间。
这个存在致命的问题,即MetaSpace可以直接操作系统内存和磁盘。在这之前,应用想要操作系统内存和磁盘都要通过操作系统内核才能进行操作。而现在,metaspace不通过内核直接操作系统资源。
所以,越往后jvm越变态。(JVMTI虚拟机可以轻易越过系统内核直接操作系统内存和磁盘)