数据仓库从0到1之日志采集平台搭建 [TOC]
数仓技术选型
项目功能需求
项目技术选型
数据采集传输
Flume、Kafka、Sqoop
数据存储
HDFS、MySQL
数据计算
Hive、Tez、Spark
数据查询
Presto、Kylin
数据可视化
superset
任务调度
Azkaban
集群监控
Zabbix
元数据管理
Atlas
数据质量监控
Apache Griffin
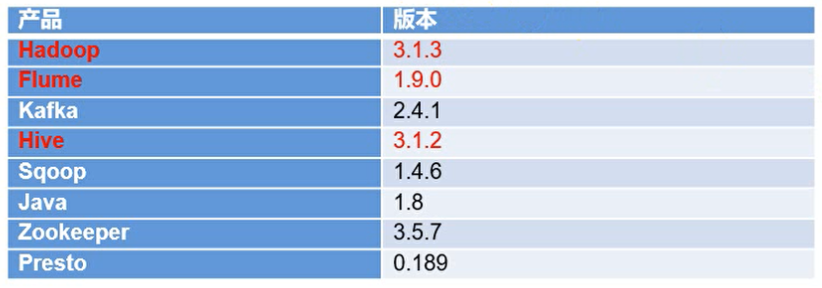
框架版本选型
测试集群配置
服务名称
子服务
服务器hadoop116
服务器hadoop117
服务器hadoop118
HDFS
NameNode
1
DataNode
1
1
1
SecondaryNameNode
1
Yarn
NodeManager
1
1
1
Yarn
ResourceManager
1
集群推断 服务器是物理主机还是云主机?
以128GB内存,20核物理CPU,40线程,8THHD和2TSSD硬盘,戴尔单台报价4W出头。一般物理机寿命5年左右。
需要有专业的运维人员,平均一个月1W,电费的开销也不小。
以阿里云为例,差不多的配置,每年5W,很多运维工作都由阿里云完成,运维相对较轻松。
金融有钱公司和阿里没有直接冲突的公司选择阿里云。中小公司,为了融资上市,选择阿里云,拉到融资后买物理主机。
有长期打算,资金充足,选择物理机。
集群规模多大?
假设每台服务器8T磁盘,128G内存
每天活跃用户100万,每人一天平均100条数据,则:100万 * 100条 = 1亿条数据
每条日志1K左右大小,每天1亿条:1亿/1024/1024 = 约100G (1K的日志数据足够大了)
如果半年不扩容服务器: 100G *180天 = 约18T
保存3副本:18T * 3 = 54 T
预留20% ~ 30% Buffer = 54T / 0.7 = 77T (预留的buffer用于运行其他应用程序)
到此,大约需要约8T服务器10台
如果考虑数仓分层,数据采用压缩(50%压缩率),则需要重新计算
日志采集平台环境准备
链接:https://pan.baidu.com/s/12Owy1sc8Jh5DVJQzOuJHWA 提取码:xp0b
Hadoop版本:3.1.3 ZooKeeper版本:3.5.7 Kafka版本:2.11-2.4.1 Flume1.9.0 Java版本: jdk-8u251-linux
链接:https://pan.baidu.com/s/1gqlmJi4SSBinGd5qcc-zkg 提取码:c2hw
可以官方下载,然后百度激活码
Centos7环境准备 1.创建虚拟机 可百度教程。
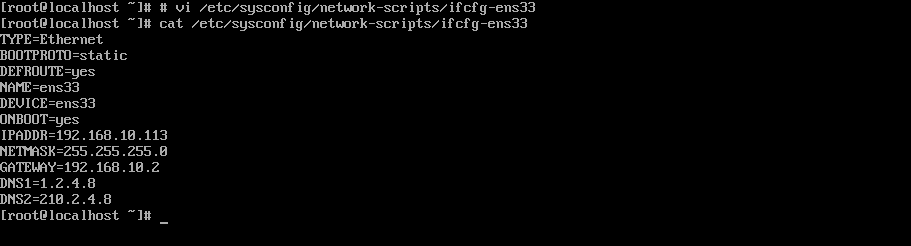
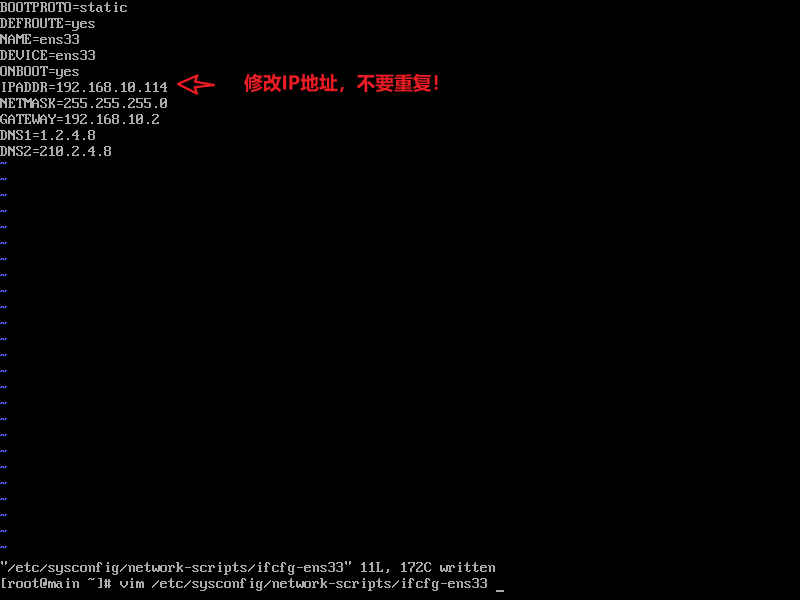
2.修改网卡 配置网卡时要对VMNET8网卡进行配置,注意不要和本地的IP地址冲突。
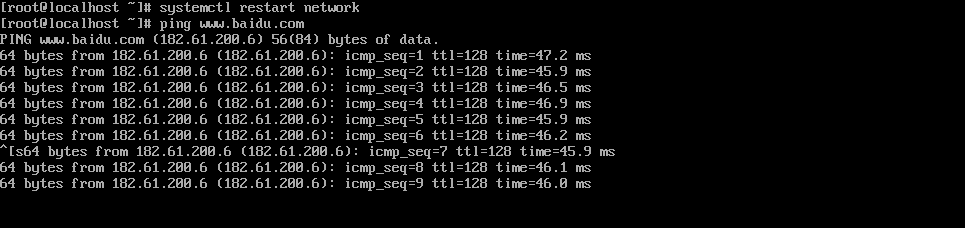
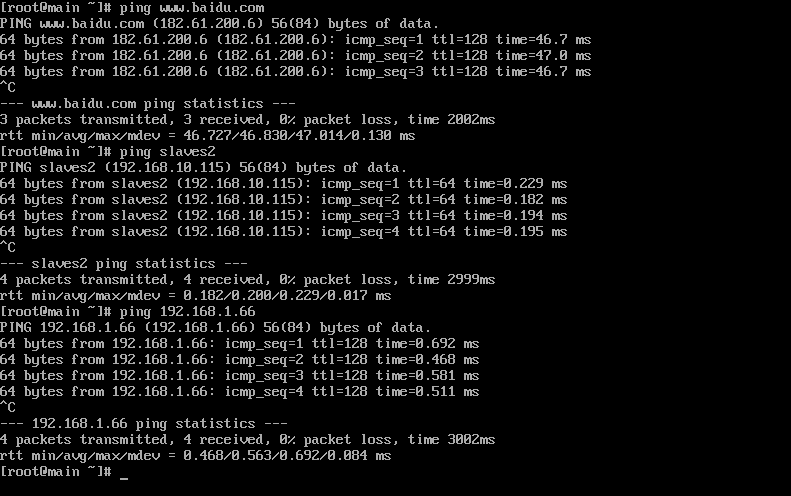
测试网络,能够ping通百度和本机即可。
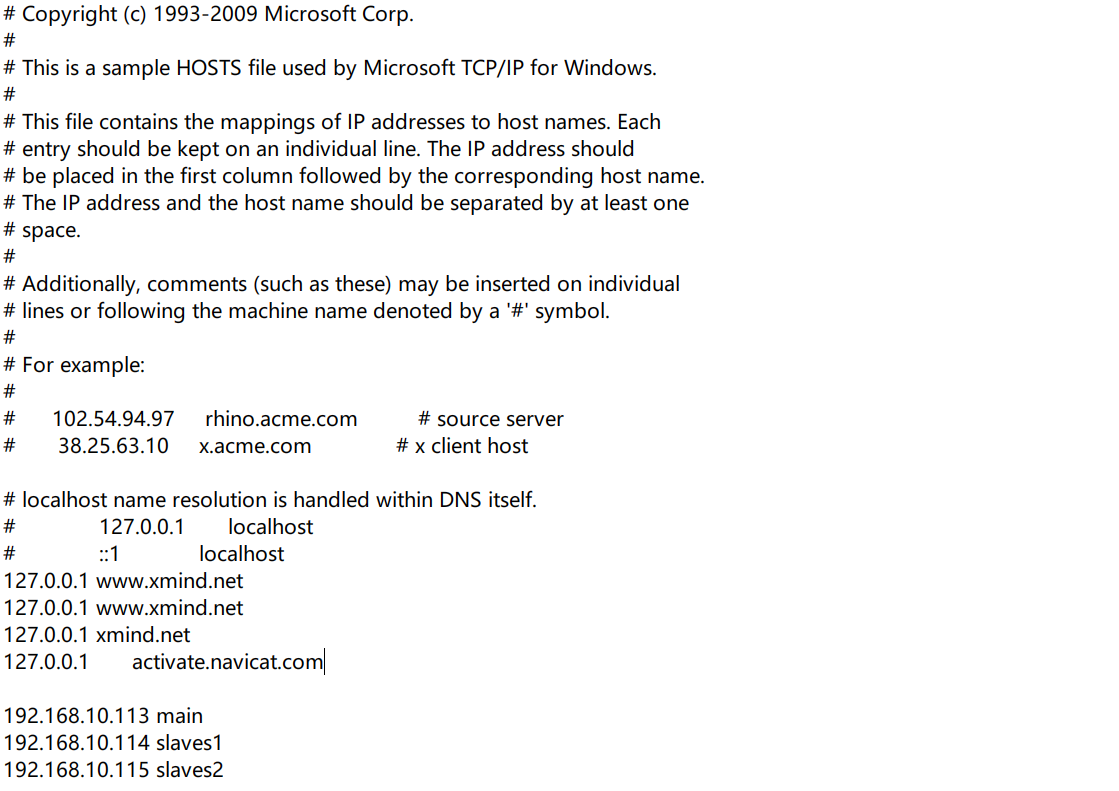
3.配置hosts 这里配置的是hadoop集群中机器的网络ip地址和别名。
虚拟机配置完后到本机的C:\Windows\System32\drivers\etc目录下修改hosts文件,加入上面三行配置。
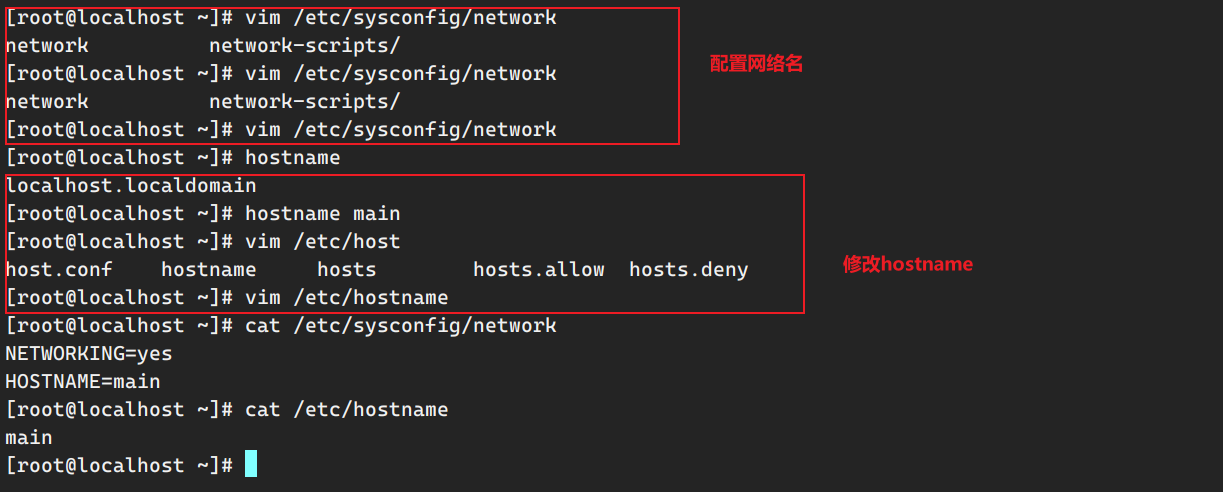
4.配置网络名+修改hostname 网络名
1 2 3 4 [root@localhost ~] [root@localhost ~] NETWORKING=yes HOSTNAME=hadoop116
hostname
1 2 3 4 5 6 7 [root@localhost ~] [root@localhost ~] hadoop116 [root@localhost ~] [root@localhost ~] hadoop116
5.关掉网络管理 1 2 3 4 5 [root@localhost ~] [root@localhost ~] Removed symlink /etc/systemd/system/multi-user.target.wants/NetworkManager.service. Removed symlink /etc/systemd/system/dbus-org.freedesktop.nm-dispatcher.service. Removed symlink /etc/systemd/system/network-online.target.wants/NetworkManager-wait-online.service.
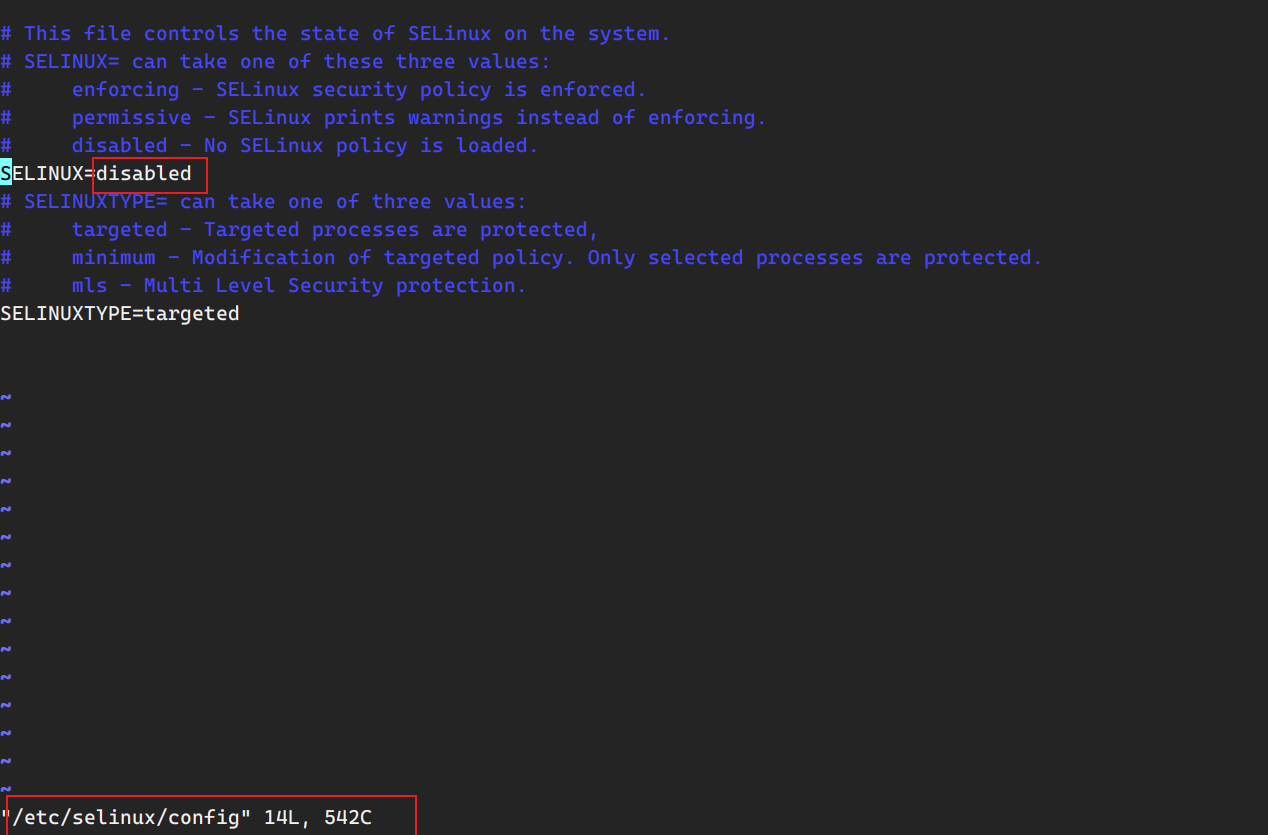
6.关掉Linux的内核防火墙 1 2 [root@localhost ~] [root@localhost ~]
查看selinux状态
7.关闭linux防火墙,禁用其开机启动 1 2 3 4 [root@localhost ~] [root@localhost ~] Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
查看防火墙状态
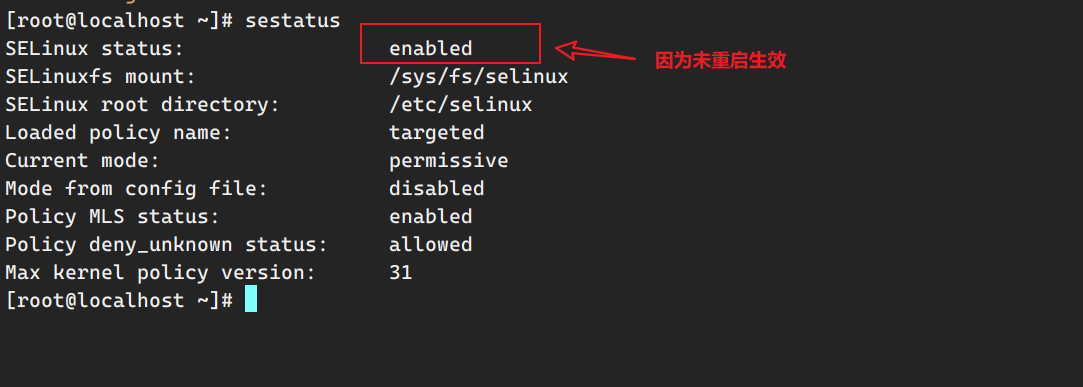
8.重启,再次查看selinux
至此,虚拟机环境配置完成。
9.配置普通用户具有root权限
10.创建文件夹用于存放软件包 1 2 [root@hadoop116 ~] [dw@hadoop116 ~]
11.配置Java环境 1 2 3 4 [dw@hadoop116 software] jdk-8u212-linux-x64.tar.gz [dw@hadoop116 software]
配置环境变量
1 [dw@hadoop116 software]$ sudo vim /etc/profile.d/my_env.sh
1 2 3 export JAVA_HOME=/opt/module/jdk1.8.0_212export PATH=$PATH :$JAVA_HOME /bin
两个文件都是设置文件的,/etc/profile是永久性的,是全局变量,/etc/profile.d/设置所有用户生效。
/etc/profile.d/比/etc/profile好维护,不想要什么变量直接删除/etc/profile.d/下对应的即可,不用像/etc/profile需要改动此文件。
1 2 3 4 5 6 7 CentOS 中每个用户都要指定各自的,其中包括可执行的 path路径,这些路径决定了每个用户在执行时的命令工具。 一般情况下,可以再每个用户的环境变量里设定各自的 path变量值,然后再执行export PATH使其生效,但如果用户比较多,安装命令工具也原来越多,且出来本身用户可以执行这些工具,root用户或其他用户也可以执行命令,这时在每个用户环境变量里添加就比较复杂了。 所以可以用另外一种方法: 可以在 /etc/profile.d/ 目录下创建一个 path.sh 脚本,脚本内容如下:
激活环境
1 2 3 4 5 [dw@hadoop116 software]$ source /etc/profile.d/my_env.sh [dw@hadoop116 software]$ java -version java version "1.8.0_212" Java(TM) SE Runtime Environment (build 1.8.0_212-b10) Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
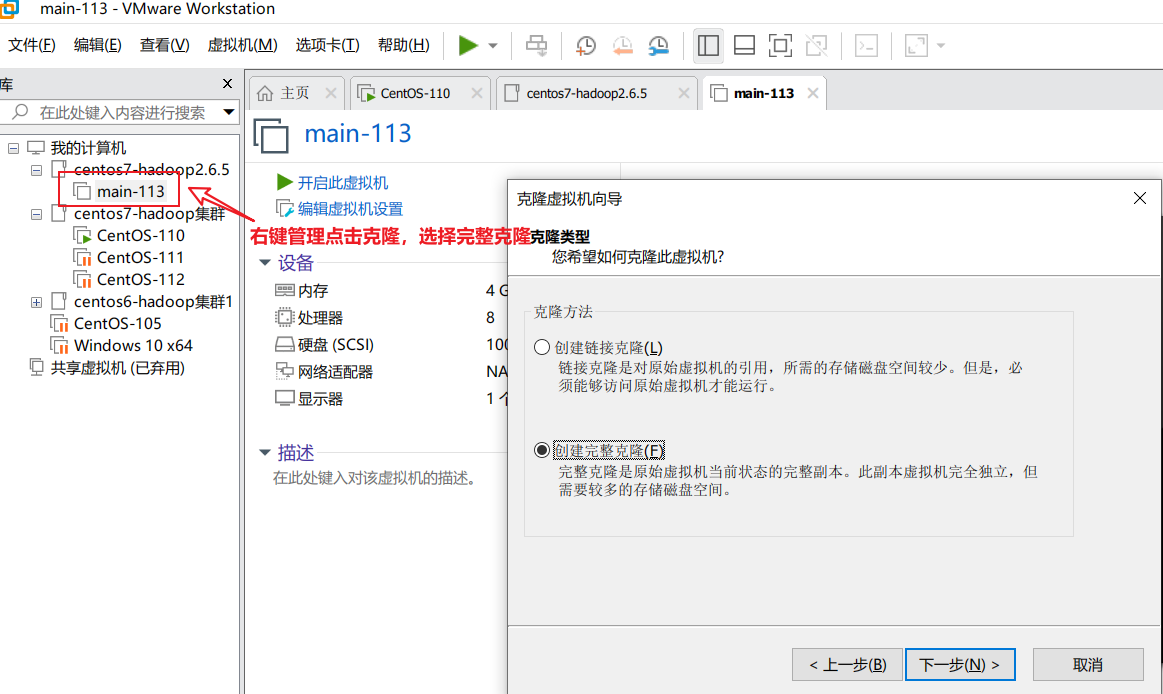
克隆虚拟机配置
克隆两台虚拟机,分别命名为slaves1、slaves2。
修改hostname 分别开启两台虚拟机,分别修改他们的hostname。
修改IP 对于slaves1,slaves同理。
修改网络名称 slaves1的修改也同slaves2的修改一样。
最后重启网络:
1 systemctl restart network
分别对slaves2和主机互相ping:
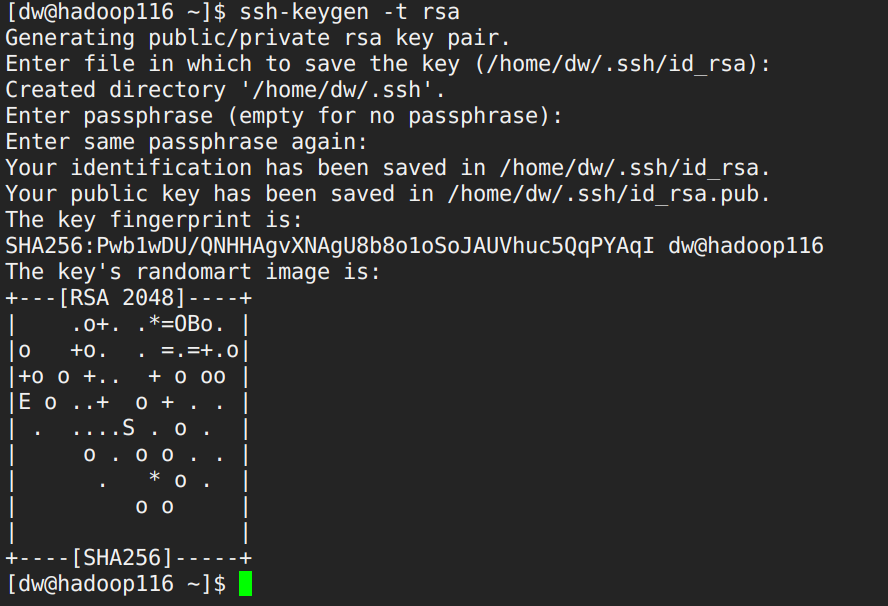
配置虚拟机之间免密通信 首先ssh登陆主节点机器-hadoop116。
1 2 [dw@hadoop116 ~]$ ssh-keygen -t rsa Generating public/private rsa key pair.
首先生成本机的公钥,之后分别切换到 hadoop117,hadoop118生成各自机器的公钥。
可以查看.ssh目录下会产生两个文件。
1 2 3 4 [dw@hadoop116 ~]$ ls [dw@hadoop116 ~]$ cd ~/.ssh/ [dw@hadoop116 .ssh]$ ls id_rsa id_rsa.pub
接下来是授权公钥,实现免密登陆,分别在hadoop116,hadoop117,hadoop118机器上分别对hadoop116,hadoop117,hadoop118分发公钥。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [dw@hadoop116 .ssh]$ ssh-copy-id hadoop116 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/dw/.ssh/id_rsa.pub" The authenticity of host 'hadoop116 (192.168.10.116)' can't be established. ECDSA key fingerprint is SHA256:5Et/sd5AKEm8Jso4gl6td6wp5TnXPa00mfga95dPYVI. ECDSA key fingerprint is MD5:d8:c0:d0:dd:e9:8a:b5:5a:f7:82:10:bb:db:9b:d4:03. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys dw@hadoop116' s password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop116'" and check to make sure that only the key(s) you wanted were added.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [dw@hadoop116 .ssh]$ ssh-copy-id hadoop117 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/dw/.ssh/id_rsa.pub" The authenticity of host 'hadoop117 (192.168.10.117)' can't be established. ECDSA key fingerprint is SHA256:5Et/sd5AKEm8Jso4gl6td6wp5TnXPa00mfga95dPYVI. ECDSA key fingerprint is MD5:d8:c0:d0:dd:e9:8a:b5:5a:f7:82:10:bb:db:9b:d4:03. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys dw@hadoop117' s password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop117'" and check to make sure that only the key(s) you wanted were added.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [dw@hadoop116 .ssh]$ ssh-copy-id hadoop118 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/dw/.ssh/id_rsa.pub" The authenticity of host 'hadoop118 (192.168.10.118)' can't be established. ECDSA key fingerprint is SHA256:5Et/sd5AKEm8Jso4gl6td6wp5TnXPa00mfga95dPYVI. ECDSA key fingerprint is MD5:d8:c0:d0:dd:e9:8a:b5:5a:f7:82:10:bb:db:9b:d4:03. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys dw@hadoop118' s password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop118'" and check to make sure that only the key(s) you wanted were added.
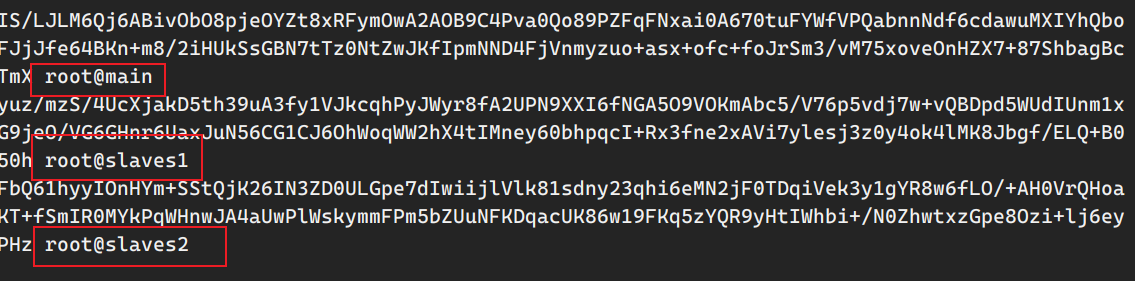
完成各个机器间密钥的分发后,可以查看.ssh目录下的authorized文件,可以发现三个机器的公钥都有了:
1 2 3 AAAAB3NzaC1yc2EAAAADAQABAAABAQC87e4EXt4RWXC3jbjYpnET42s4mTUfbEEh7IkV3Q5ayZCB2KUQM9raVLbkYdtrd+oKGR7W/yEJKUyRnMyWjZGz6c1fF3zh73/pzCbonsXZ7GPIeuK1z+5F5vZxR2Fx62a3Fp1RXLbUIXz4hdPDSfXqpdQRyPTYyDiiRSKwGpg5SBsBCp38iWTaJSDc9NzUEyw3DcuaXETE79wzCccvJ1r0F5RJZ1OMu8Uyck7nKWph7xwc92cPqwaGPfAPgjITxh20jUK0ja+9Zja+TxTl1W9SZLE2Tjwpqe6lcgaiYwCI7gJ4lYDxetka3idke+cu1sxiNp/D5FxCOukTZ29DKn+b dw@hadoop116 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDpmI/Z35OaDQWzBd6MZCcjO2f2HMoKBLqTsQ7DyAASfXruqQW5xy7zHr+7bsHkTG3YPRcMYGlbLACkJnTQTar0woxIxlZzVAQ2+MvlwfbExVTnZFaLVPz6caG8GM+uOJRrGTCn3a8W5UlEP4UJgp+MZL9OHTNb8Az6bTYwKXJJAuNG1dK4nOYlIG0i9RFpmoGZiB5siRXFkTtAbY2YZclyVK4Fx1fPKdDBUNYRxBxryg7csFfOfZgw4BV5FNv9+ZCCvY5/F0sgKpOvRoKuTB10ztQLOA5OMXLDfolUq5sWZTZu+4dgNYqnlYsqHZRAhM7kslS7sOxtOwqKw15waUjj dw@hadoop117 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDEtdG4Z/y2LM5T6Nk6LXD7PxmsAph9o0sguniozo7MpvZywQKjRA6QxpO+Lob3Z8WO8S03jqv5O6zoss8WRnDI8pqCVK6CMR9vToziSFDw5omOG046X06+otJEqcSIUYwv6dookBS5qJWezjR44kNGQE2Tp/pEEHMNGNAdFWGZfVx0jNdN3tUxOymhJXn6pM8D+2Exx1KjRHyF7fa7mjbkwVZAEk9KMuDxHFGcGyO+GnXMBJc7QjqUZxUP8hhar/IHTm/wwM1a3hfoey6PO+JHpXL60LDkffWc2E3mdMcKXJSOpCJuhlkFxWNoK9nLfCkoYvJPb3A5ukP5twjal5bZ dw@hadoop118
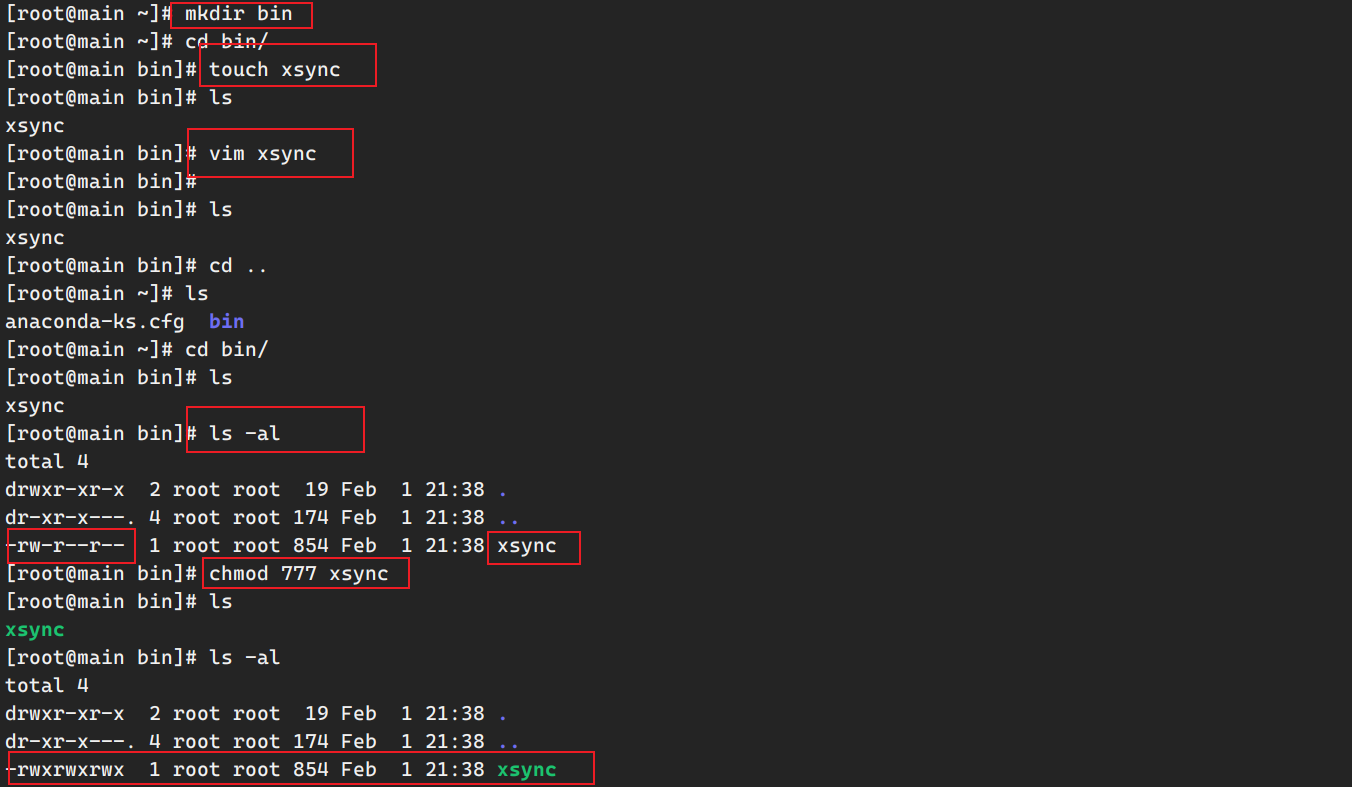
创建xsync脚本命令实现机器间数据更新 安装rsync命令
1 sudo yum install rsync -y
在root的~目录下创建bin文件夹,在文件夹内创建xsync脚本文件,并给其赋予可执行权限。
xsync脚本文件:
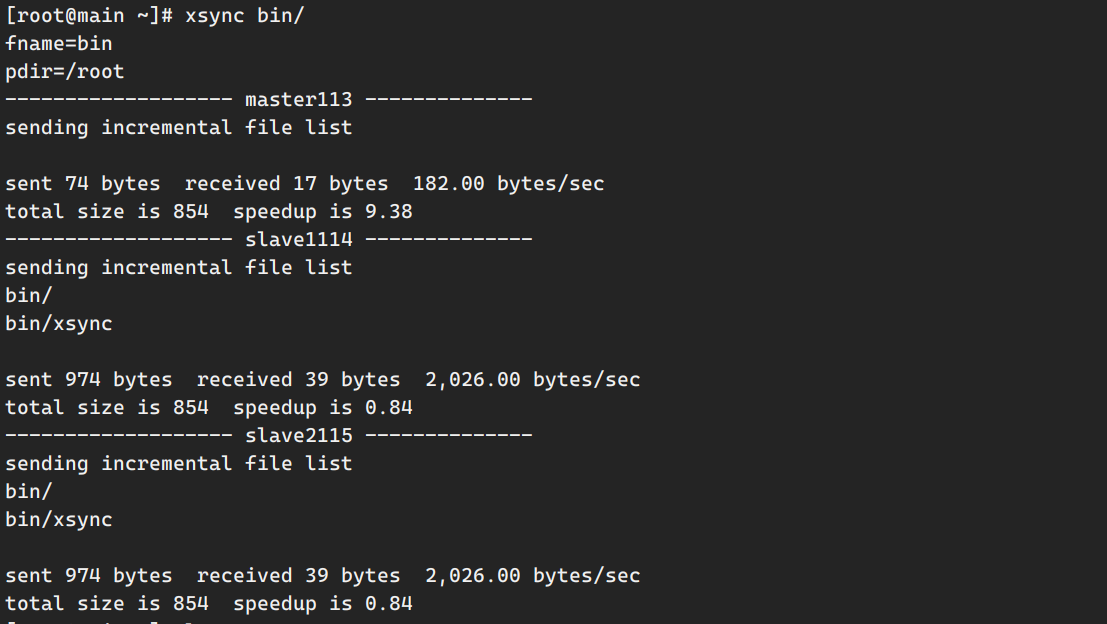
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #!/bin/bash pcount=$# if ((pcount==0)); then echo no args;exit ;fi p1=$1 fname=`basename $p1 ` echo fname=$fname pdir=`cd -P $(dirname $p1 ); pwd ` echo pdir=$pdir user=`whoami ` for ((host=116; host<119; host++)); do case $host in "116" ) echo ------------------- master$host -------------- rsync -rvl $pdir /$fname $user @hadoop116:$pdir ;; "117" ) echo ------------------- slave1$host -------------- rsync -rvl $pdir /$fname $user @hadoop117:$pdir ;; "118" ) echo ------------------- slave2$host -------------- rsync -rvl $pdir /$fname $user @hadoop118:$pdir ;; esac done
之后,便可以在虚拟机之间实现数据的传输和更新。测试一下,把main机器的bin目录同步到其他机器上:
配置集群时间同步 编写脚本实现三台机器同时执行一个命令,同上面一样将脚本放在bin目录库下。
1 2 3 4 for i in hadoop116 hadoop117 hadoop118;do echo "==========$i ==========" ssh $i "$*" done
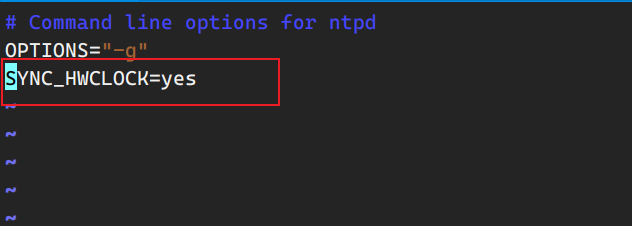
查看时间配置服务器ntp是否安装 1 sudo ~/bin/ae.sh yum install ntp ntpdate -y
查看ntp状态:
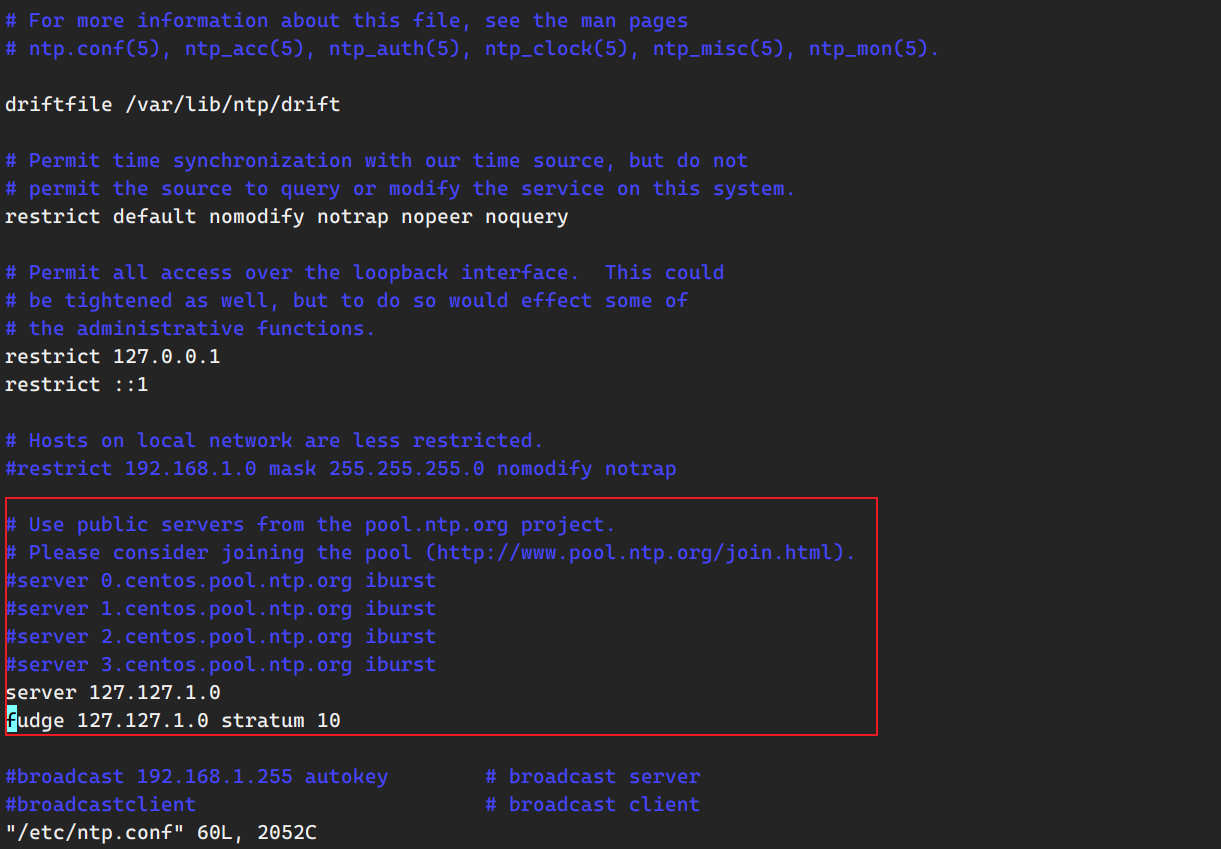
使该NTP服务器在不联网的情况下,使用本服务器的时间作为同步时间
以上修改都在主节点机器上进行。
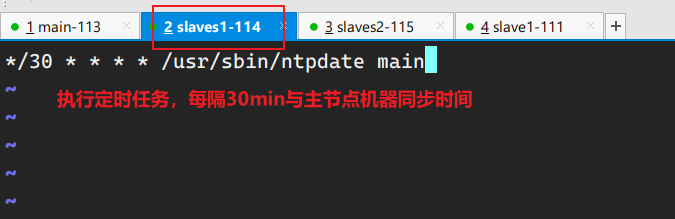
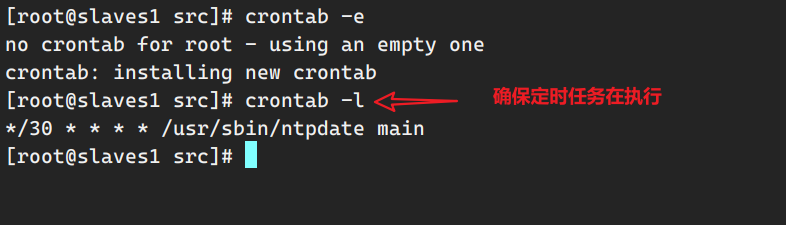
crontab配置节点机器定时与主节点机器同步时间 注意,如果执行crontab命令的是普通用户,任务不会生效,需要使用root用户权限执行crontab。
sudo crontab -e
Hadoop搭建 安装hadoop软件包 1 2 3 4 5 6 7 8 [dw@hadoop116 hadoop]$ pwd /opt/software/hadoop [dw@hadoop116 hadoop]$ ll total 610476 -rw-rw-r-- 1 dw dw 224565455 May 4 00:56 bigtable.lzo -rw-rw-r-- 1 dw dw 338075860 May 4 00:56 hadoop-3.1.3.tar.gz -rw-rw-r-- 1 dw dw 193831 May 4 00:56 hadoop-lzo-0.4.20.jar -rw-rw-r-- 1 dw dw 62282700 May 4 00:56 hadoop-lzo-master.zip
解压:
1 2 3 4 [dw@hadoop116 hadoop]$ [dw@hadoop116 hadoop]$ ls bigtable.lzo hadoop-3.1.3.tar.gz hadoop-lzo-0.4.20.jar hadoop-lzo-master.zip [dw@hadoop116 hadoop]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
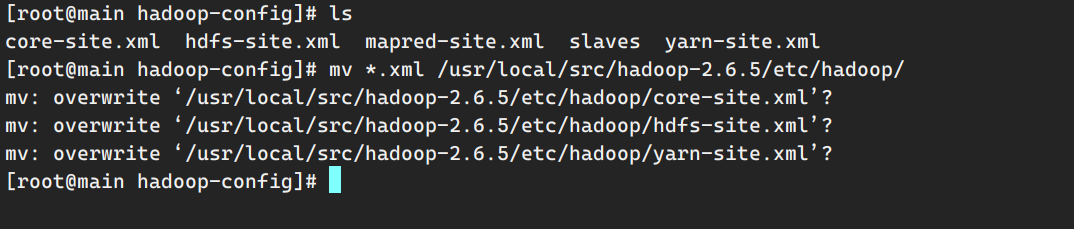
配置hadoop配置文件 这里要输入yes 记得!否则不会覆盖掉原文件,导致后面集群启动出错,最好再次查看是否覆盖掉原配置文件。
修改core-site.xml配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://hadoop116:8020</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /opt/module/hadoop-3.1.3/data</value > </property > <property > <name > hadoop.http.staticuser.user</name > <value > dw</value > </property > <property > <name > hadoop.proxyuser.dw.hosts</name > <value > *</value > </property > <property > <name > hadoop.proxyuser.dw.groups</name > <value > *</value > </property > <property > <name > hadoop.proxyuser.dw.users</name > <value > *</value > </property > </configuration >
修改hdfs-site.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <configuration > <property > <name > dfs.namenode.http-address</name > <value > hadoop116:9870</value > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > hadoop118:9868</value > </property > <property > <name > dfs.replication</name > <value > 1</value > </property > </configuration >
修改yarn-site.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 <configuration > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.resourcemanager.hostname</name > <value > hadoop117</value > </property > <property > <name > yarn.nodemanager.env-whitelist</name > <value > JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value > </property > <property > <name > yarn.scheduler.minimum-allocation-mb</name > <value > 512</value > </property > <property > <name > yarn.scheduler.maximum-allocation-mb</name > <value > 4096</value > </property > <property > <name > yarn.nodemanager.resource.memory-mb</name > <value > 4096</value > </property > <property > <name > yarn.nodemanager.pmem-check-enabled</name > <value > false</value > </property > <property > <name > yarn.nodemanager.vmem-check-enabled</name > <value > false</value > </property > <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log.server.url</name > <value > http://hadoop116:19888/jobhistory/logs</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property > </configuration >
配置mapred-site.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > mapreduce.jobhistory.address</name > <value > hadoop116:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > hadoop116:19888</value > </property > </configuration >
配置workers(以前是slaves,现在改成workers):
1 2 3 4 5 [dw@hadoop116 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers [dw@hadoop116 hadoop]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/workers hadoop116 hadoop117 hadoop118
配置环境变量 配置环境变量
1 2 3 4 5 6 7 8 export JAVA_HOME=/opt/module/jdk1.8.0_212export PATH=$PATH :$JAVA_HOME /binexport HADOOP_HOME=/opt/module/hadoop-3.1.3export PATH=$PATH :$HADOOP_HOME /binexport PATH=$PATH :$HADOOP_HOME /sbin
激活环境去配置Hadoop文件:
1 2 3 4 5 [dw@hadoop116 hadoop]$ source /etc/profile.d/my_env.sh [dw@hadoop116 hadoop]$ cd $HADOOP_HOME / [dw@hadoop116 hadoop]$ pwd [dw@hadoop116 hadoop-3.1.3]$ cd ./etc/hadoop/ /opt/module/hadoop-3.1.3/etc/hadoop
1 2 3 4 5 6 7 8 # JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_251 export PATH=$PATH:$JAVA_HOME/bin # HADOOP export HADOOP_HOME=/opt/module/hadoop-2.6.1 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
之后到hadoop根目录下的etc/hadoop目录下,修改hadoop-env.sh和yarn-env.sh中的JAVA_HOME的路径为配置的java路径(/opt/module/jdk1.8.0_251)。
配置完成后关闭虚拟机。
启动Hadoop集群 分发hadoop到各个节点上 1 [dw@hadoop116 hadoop]$ xsync /opt/module/hadoop-3.1.3/
分发环境变量(完成后要source激活)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [dw@hadoop116 hadoop]$ sudo /home/dw/bin/xsync /etc/profile.d/my_env.sh fname=my_env.sh pdir=/etc/profile.d ------------------- hadoop116116 -------------- root@hadoop116's password: sending incremental file list sent 46 bytes received 12 bytes 23.20 bytes/sec total size is 217 speedup is 3.74 ------------------- hadoop117117 -------------- root@hadoop117' s password: sending incremental file list my_env.sh
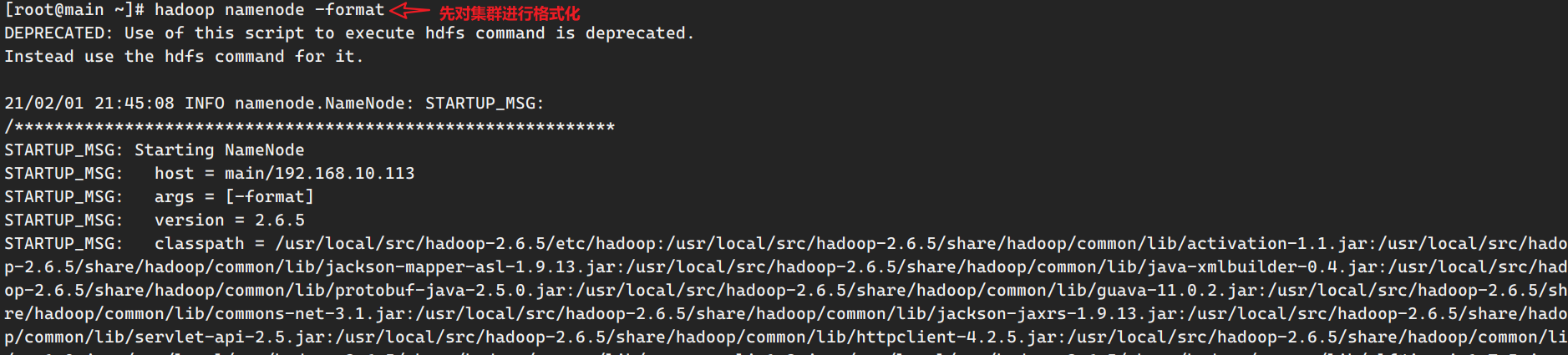
格式化集群 在主节点上执行:
1 2 3 4 [dw@hadoop116 hadoop-3.1.3]$ ./bin/hdfs namenode -format /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop116/192.168.10.116 ************************************************************/
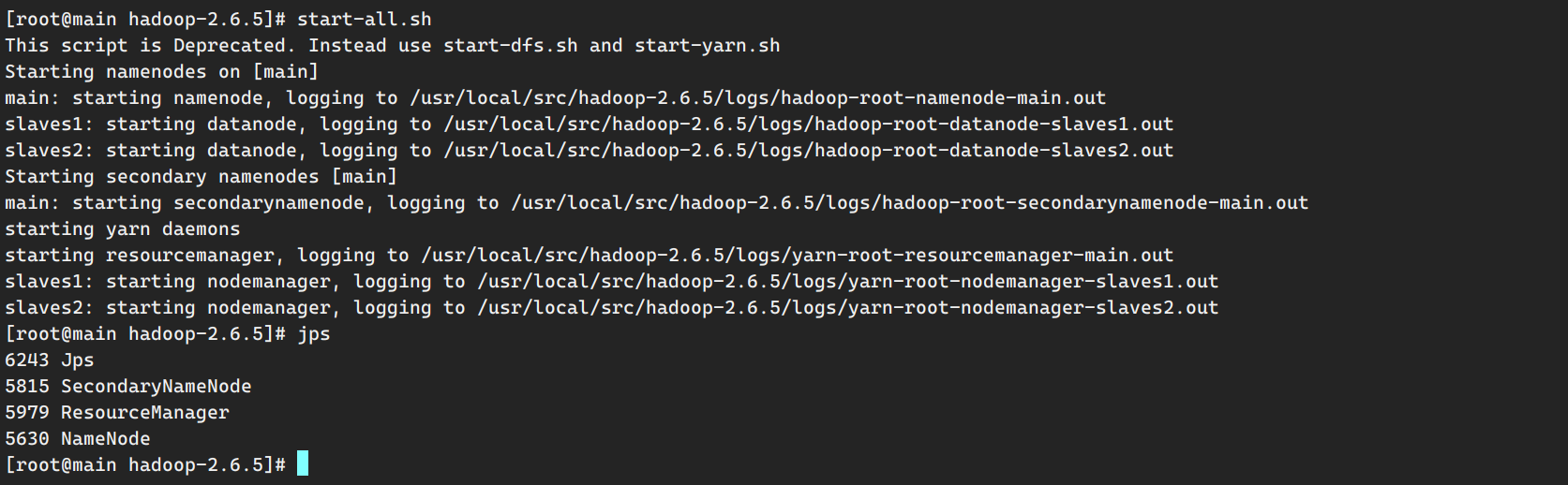
启动集群 namenode在hadoop116启动,yarn在hadoop117启动,snn在hadoop118启动。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 dw@hadoop116 hadoop-3.1.3]$ start-dfs.sh Starting namenodes on [hadoop116] Starting datanodes hadoop117: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating. hadoop118: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating. Starting secondary namenodes [hadoop118] [dw@hadoop116 hadoop-3.1.3]$ jps 12917 NameNode 13352 NodeManager 13452 Jps 13069 DataNode [dw@hadoop117 ~]$ start-yarn.sh Starting resourcemanager Starting nodemanagers [dw@hadoop117 ~]$ jps 12513 DataNode 12805 NodeManager 12953 Jps [dw@hadoop118 module]$ jps 12385 NodeManager 12524 Jps 12190 DataNode 12302 SecondaryNameNode
编写脚本查看各集群进程 1 2 3 4 5 6 7 8 [dw@hadoop116 hadoop-3.1.3]$ cd ~/bin/ [dw@hadoop116 bin]$ vim xcall.sh [dw@hadoop116 bin]$ chmod +x xcall.sh [dw@hadoop116 bin]$ ls -ll total 12 -rwxrwxr-x 1 dw dw 162 May 4 00:51 log.sh -rwxrwxr-x 1 dw dw 143 May 4 03:11 xcall.sh -rwxr-xr-x 1 dw dw 910 May 4 02:34 xsync
1 2 3 4 5 6 params=$@ i=1 for (( i=116 ; i <= 119 ; i = $i + 1 )) ; do echo ============= node$i $params ============= ssh hadoop$i "$params " done
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ============= hadoop116 jps ============= 16897 NodeManager 17266 Jps 16613 DataNode 16461 NameNode ============= hadoop117 jps ============= 14513 DataNode 14994 NodeManager 15429 Jps 14685 ResourceManager ============= hadoop118 jps ============= 13858 NodeManager 14153 Jps 13663 DataNode 13775 SecondaryNameNode
运行一个mr任务检查集群是否正常 1 2 3 4 5 6 [dw@hadoop116 hadoop-3.1.3]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 1 1 Number of Maps = 1 Samples per Map = 1 Job Finished in 21.831 seconds 2021-05-04 03:08:30,989 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false , remoteHostTrusted = false Estimated value of Pi is 4.00000000000000000000
以上便是Hadoop集群搭建的所有步骤。
模拟日志产生 这里以hadoop116和hadoop117作为日志服务器。
将资料中的Mok09文件夹下的application.properties、gmall2020-mock-log-2020-05-10.jar、path.json、logback.xml上传到hadoop116的/opt/module/applog目录下:
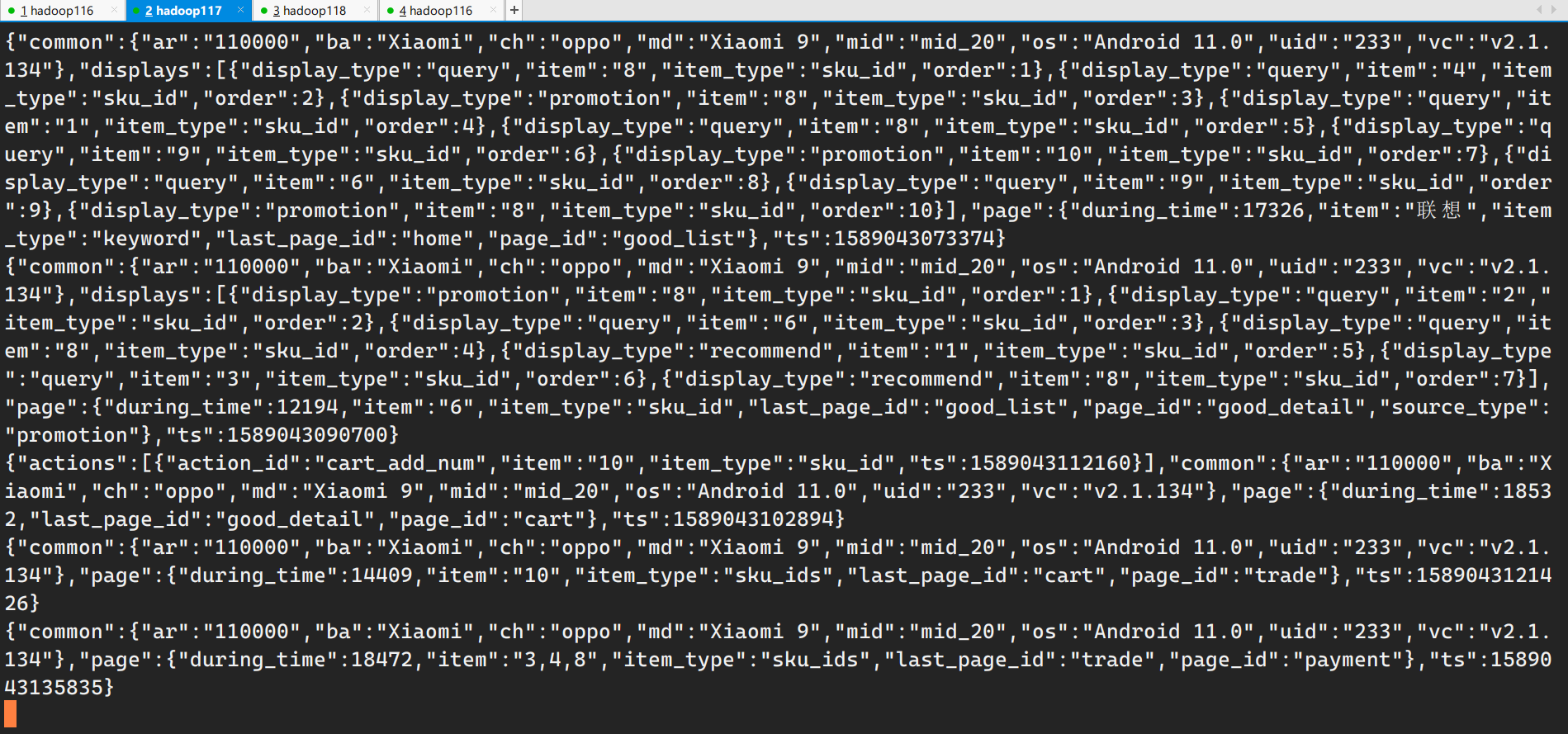
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [dw@hadoop116 ~]$ mkdir /opt/module/applog [dw@hadoop116 applog]$ ls application.properties gmall2020-mock-log-2020-05-10.jar logback.xml path.json [dw@hadoop116 applog]$ pwd /opt/module/applog `gmall2020-mock-log-2020-05-10.jar`是模拟产生业务日志数据的代码程序逻辑。 `logback`和log4j类似,都是日志框架的实现,logback配置文件是xml,log4j配置文件是peoperties。 logback其中部分配置信息:  运行jar包程序: ```bash [dw@hadoop116 applog]$ java -jar gmall2020-mock-log-2020-05-10.jar [dw@hadoop116 module]$ ls applog/ application.properties gmall2020-mock-log-2020-05-10.jar log logback.xml path.json
将applog目录下数据发送到日志服务器hadoop117上:
1 2 3 4 5 6 [dw@hadoop116 module]$ scp -rp applog/ hadoop117:/opt/module/ application.properties 100% 618 992.4KB/s 00:00 gmall2020-mock-log-2020-05-10.jar 100% 11MB 63.6MB/s 00:00 logback.xml 100% 3178 3.3MB/s 00:00 path.json 100% 489 620.7KB/s 00:00 app.2021-05-03.log 100% 409KB 69.3MB/s 00:00
创建一个日志文件产生shell脚本,放到前面配置xsync的bin目录下,赋予其执行权限:
1 2 3 4 5 6 7 [dw@hadoop116 applog]$ cd ~/bin/ [dw@hadoop116 bin]$ vim log.sh [dw@hadoop116 bin]$ chmod +x log.sh [dw@hadoop116 bin]$ ls -ll total 8 -rwxrwxr-x 1 dw dw 144 May 4 00:35 log.sh -rwxr-xr-x 1 dw dw 910 May 3 23:48 xsync
1 2 3 4 for i in hadoop116 hadoop117;do echo "==========$i ==========" ssh $i "cd /opt/module/applog;java -jar gmall2020-mock-log-2020-05-10.jar" done
shell的输出分为标准错误和标准输出两种输出方式。一般”1”指代的是标准输出,”2”指代的是标准错误输出。对对标准输出进行重定向:(输入到/dev/null的数据都不会被保存,称之为黑洞 )
java -jar gmall2020-mock-log-2020-05-10.jar 1>/dev/null 2>/dev/null
可以简化为:(“&”类似C指针的概念,表示2去到1去的地方)
java -jar gmall2020-mock-log-2020-05-10.jar 1>/dev/null 2>&1
还可以进行简化,一般不显示定义1还是2,默认就是1:
java -jar gmall2020-mock-log-2020-05-10.jar >/dev/null 2>&1
修改后执行命令,可以看到,终端没有任何日志文件的输出,但是会等待程序股执行:
1 2 3 [dw@hadoop116 applog]$ log.sh ==========hadoop116========== ==========hadoop117==========
此外,要让程序到后台执行,不堵塞在当前终端可以这样:
java -jar gmall2020-mock-log-2020-05-10.jar >/dev/null 2>&1 &
修改后执行,虽然也会输出脚本里echo的信息,但是终端迅速跳过了等待该任务,让它在后台执行,我们可以继续在终端执行下一个命令。
1 2 3 4 [dw@hadoop116 applog]$ log.sh ==========hadoop116========== ==========hadoop117========== [dw@hadoop116 applog]$
查看log文件:
1 2 3 4 [dw@hadoop116 log ]$ ls app.2021-05-03.log app.2021-05-04.log [dw@hadoop116 log ]$ du -sh ./ 1.6M ./
ZooKeeper安装 1.解压安装 1 2 3 4 5 6 7 8 9 10 11 12 13 14 [dw@hadoop116 zookeeper]$ pwd /opt/software/zookeeper [dw@hadoop116 zookeeper]$ ls apache-zookeeper-3.5.7-bin.tar.gz [dw@hadoop116 zookeeper]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/ [dw@hadoop116 module]$ pwd /opt/module [dw@hadoop116 module]$ ls apache-zookeeper-3.5.7-bin applog hadoop-3.1.3 jdk1.8.0_212 [dw@hadoop116 module]$ mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7/ [dw@hadoop116 module]$ ls applog hadoop-3.1.3 jdk1.8.0_212 zookeeper-3.5.7-bin
### 2.修改配置文件 配置myid文件
1 2 3 4 5 6 [dw@hadoop116 module]$ cd zookeeper-3.5.7/ [dw@hadoop116 zookeeper-3.5.7]$ mkdir zkData [dw@hadoop116 zookeeper-3.5.7]$ cd zkData/ [dw@hadoop116 zkData]$ vim myid [dw@hadoop116 zkData]$ cat myid 2
修改zoo.cfg配置文件
1 2 3 4 5 6 7 8 9 [dw@hadoop116 zkData]$ cd ../conf/ [dw@hadoop116 conf]$ ll total 12 -rw-r--r-- 1 dw dw 535 May 4 2018 configuration.xsl -rw-r--r-- 1 dw dw 2712 Feb 7 2020 log4j.properties -rw-r--r-- 1 dw dw 922 Feb 7 2020 zoo_sample.cfg [dw@hadoop116 conf]$ pwd /opt/module/zookeeper-3.5.7/bin/conf [dw@hadoop116 conf]$ mv zoo_sample.cfg zoo.cfg
给文件修改添加以下内容
1 2 3 4 5 6 7 8 9 dataDir=/opt/module/zookeeper-3.5.7/zkData #######################cluster##########################在文件末尾添加 # server.id 指的是myid里配置的数字 # 2888端口号用于follower和leader进行交流的端口 # 3888是选举leader用的端口 server.2=hadoop116:2888:3888 server.3=hadoop117:2888:3888 server.4=hadoop118:2888:3888
分发zookeeper到各个节点:
1 [dw@hadoop116 module]$ xsync zookeeper-3.5.7/
分别到其他两个节点修改zk的myid,注意myid不能重复,从hadoop116~hadoop118依次设置为2,3,4。
3.创建ZK启停脚本 在~/bin/目录下创建zkS.sh启停脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # !/bin/bash case $1 in "start"){ for i in hadoop116 hadoop117 hadoop118 do echo ---------- zookeeper $i 启动 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start" done };; "stop"){ for i in hadoop116 hadoop117 hadoop118 do echo ---------- zookeeper $i 停止 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop" done };; "status"){ for i in hadoop116 hadoop117 hadoop118 do echo ---------- zookeeper $i 状态 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status" done };; esac
Kafka搭建 1.解压安装 1 2 3 4 5 6 7 8 9 10 11 12 13 [dw@hadoop116 kafka]$ pwd /opt/software/kafka [dw@hadoop116 kafka]$ ls kafka_2.11-2.4.1.tgz [dw@hadoop116 kafka]$ tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module/ [dw@hadoop116 kafka]$ cd /opt/module/ [dw@hadoop116 module]$ pwd /opt/module [dw@hadoop116 module]$ ls applog hadoop-3.1.3 jdk1.8.0_212 kafka_2.11-2.4.1 zookeeper-3.5.7 zookeeper-3.5.7-bin [dw@hadoop116 module]$ mv kafka_2.11-2.4.1/ kafka/
2.修改配置文件 1 2 3 4 5 [dw@hadoop116 module]$ cd kafka/ [dw@hadoop116 kafka]$ pwd /opt/module/kafka [dw@hadoop116 kafka]$ mkdir logs [dw@hadoop116 kafka]$ vim config/server.properties
给server.properties文件添加以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 修改或者增加以下内容: broker.id =0 delete.topic.enable =true log.dirs =/opt/module/kafka/data zookeeper.connect =hadoop116:2181,hadoop117:2181,hadoop118:2181/kafka
3.kafka启停脚本 先看看kafka单点启动命令:
1 xxxxxxxxxx [dw@hadoop116 kafka]$ ./bin/kafka-server-start.sh USAGE: ./bin/kafka-server-start.sh [-daemon] server.properties [--override property=value]*
kafka.sh启停脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # ! /bin/bash case $1 in "start"){ for i in hadoop116 hadoop117 hadoop118 do echo " --------启动 $i Kafka-------" ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties" done };; "stop"){ for i in hadoop116 hadoop117 hadoop118 do echo " --------停止 $i Kafka-------" ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh stop" done };; esac
1 2 3 4 5 6 [dw@hadoop116 logs]$ cd ~/bin/ [dw@hadoop116 bin]$ vim kafka.sh [dw@hadoop116 bin]$ chmod +x kafka.sh [dw@hadoop116 bin]$ ls ae.sh kafka.sh log.sh xcall.sh xsync zkServer.sh [dw@hadoop116 bin]$ xsync kafka.sh
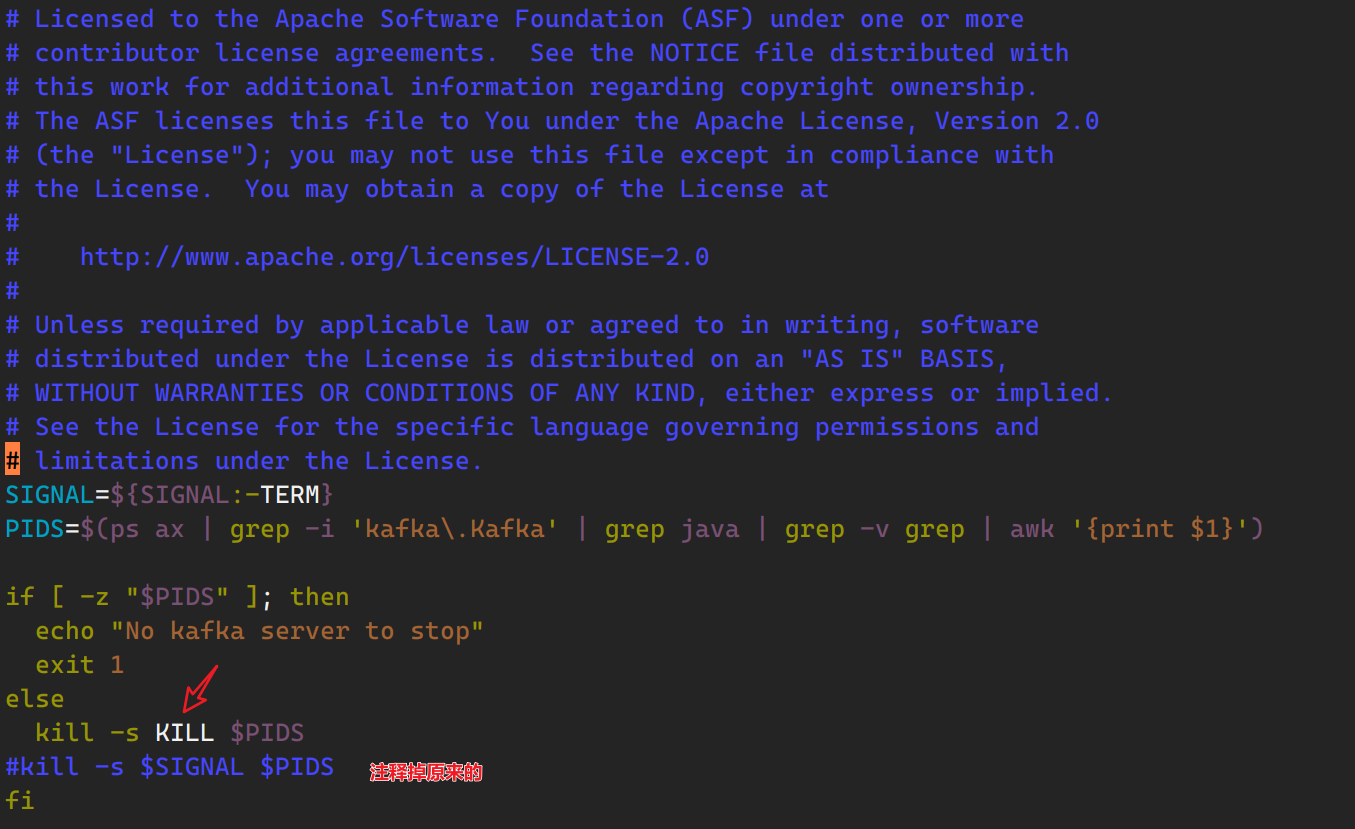
这里要注意,该版本的kafka停止脚本kafka-server-stop.sh有点问题,无法通过此脚本终止kafka进程,需要对脚本进行修改:
4.分发kafka启停测试 1 [dw@hadoop116 module]$ xsync kafka/
此处注意,要先等待kafka 进程终止了之后再关闭zk,否则先关闭zk,zk上的kafka节点在下次zk启动时仍然存在,不管kafka进程有无启动。
kafka简介及常用命令 简介 Kafka是一个消息队列:
点对点:一个生产者对应一个消费者
发布订阅模式:一个生产者发布消息,所有订阅了主题的消费者都能够受到消息
发布订阅式的消息队列都有“主题”这个概念。
只要是分布式的就一定有分区。kafka分区分的是topic。topic里有多个分区,写和消费都是分布式并行写和消费。
kafka的容错通过副本机制实现,一个topic里面的partition有多个副本,分布在集群各节点上。
在kafka种,消费者不再是单个消费者,而是一个组,一个组是一个整体。在kafka中,一个生产者对应多个消费者组。
常用脚本命令 1.查看Kafka Topic列表 1 2 [dw@hadoop116 kafka]$ ./bin/kafka-topics.sh --zookeeper hadoop116:2181/kafka --list [dw@hadoop116 kafka]$
kafka有一个内置的topic,叫做consumeroffset,但这里查找topic却没找到。这是因为,consumeroffset是记录消费者消费时的offset的,所以只有消费者消费了才会产生这个topic,因为我们刚安装kafka还未消费,所以没有。在kafka0.9版本前是没有这个topic,offset是存在zk上。但是那样子,对zk的依赖过于严重,所以现在kafka在逐步摆脱对zk的依赖。
2.创建Kafka Topic 进入到/opt/module/kafka/目录下创建日志主题
1 2 [dw@hadoop116 kafka]$ ./bin/kafka-topics.sh --zookeeper hadoop116:2181/kafka --create --topic first --partitions 3 --replication-factor 2 Created topic first.
1 2 3 4 5 6 7 8 9 10 [dw@hadoop116 kafka]$ ./bin/kafka-topics.sh --zookeeper hadoop116:2181/kafka --describe --topic first Topic: first PartitionCount: 3 ReplicationFactor: 2 Configs: Topic: first Partition: 0 Leader: 1 Replicas: 1,0 Isr: 1,0 Topic: first Partition: 1 Leader: 2 Replicas: 2,1 Isr: 2,1 Topic: first Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2 [dw@hadoop116 kafka]$ # partition : 分区编号 # leader : kafka的broker.id # replicas : 副本个数和副本所在的节点的broker.id # Isr : 用于保证高可用的,一旦当前leader节点挂掉就有isr后面一个broker.id的节点充当leader
3.删除Kafka Topic 1 [atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --delete --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --topic topic_log
4.Kafka生产消息 1 2 3 4 5 6 [atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh \ --broker-list hadoop102:9092 --topic topic_log \>hello world \>atguigu atguigu
kafka的每一个broker节点都会维护一份topic元数据,节点间元数据是同步的,就是describe topic 的元数据信息。kafka生产者写数据要写到leader上,首先要知道partition的leader在哪个节点上,所以需要指定broker-list传参,去获取元数据信息去leader写数据。一般写broker-list要写两个,避免一个节点挂掉了。
1 2 3 4 5 6 7 [dw@hadoop116 kafka]$ kafka-console-producer.sh --broker-list hadoop116:9092 --topic first >atguigu >aaaaaa >bbbbbb >cccccc >dddddd >111111
5.Kafka消费消息 1 2 3 4 5 6 [atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \ --bootstrap-server hadoop116:9092 --from-beginning --topic topic_log --from-beginning:会把主题中以往所有的数据都读取出来。根据业务场景选择是否增加该配置。
运行命令,发现消费者堵塞不动,但是前面生产者已经写了数据了。这是因为没有配置—from-beginning参数,这个参数在java api叫做offset autoresize,当kafka一个消费者去消费,这个消费者挂掉后重启,有两种情况:
从开始去消费
从最新的开始去消费(即上次消费到的记录下来的offset)
kafka默认策略是从最新的消息去消费,所以这种情况下,想要消费先前的数据,需要加上参数 — from-begining。
1 2 [dw@hadoop117 module]$ kafka-console-consumer.sh --bootstrap-server hadoop116:9092 --topic first
此时我们生产者再次生:
1 2 3 4 5 6 7 8 [dw@hadoop116 kafka]$ kafka-console-producer.sh --broker-list hadoop116:9092 --topic first >atguigu >aaaaaa >bbbbbb >cccccc >dddddd >111111 >333333 <--new
1 2 [dw@hadoop117 module]$ kafka-console-consumer.sh --bootstrap-server hadoop116:9092 --topic first 333333 <--消费者消费
6.查看Kafka Topic详情 1 2 [atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka \ --describe --topic topic_log
7.消费者组信息查看脚本 kafka-consumer-group.sh能看到有哪几个消费者组信息,正在消费的topic和分区信息以及offset。
1 2 3 4 5 6 [dw@hadoop118 ~]$ kafka-consumer-groups.sh --bootstrap-server hadoop116:9092 --list console-consumer-75164 console-consumer-31713 console-consumer-49957 console-consumer-42719
查看消费组的信息:
1 2 3 4 5 6 7 8 9 10 11 12 [dw@hadoop118 ~]$ kafka-consumer-groups.sh --bootstrap-server hadoop116:9092 --describe --group console-consumer-75164 GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID console-consumer-75164 first 0 - 5 - consumer-console-consumer-75164-1-fd2b2e87-393c-430f-98ce-5a2ba2f09df1 /192.168.10.117 consumer-console-consumer-75164-1 console-consumer-75164 first 1 - 2 - consumer-console-consumer-75164-1-fd2b2e87-393c-430f-98ce-5a2ba2f09df1 /192.168.10.117 consumer-console-consumer-75164-1 console-consumer-75164 first 2 - 4 - consumer-console-consumer-75164-1-fd2b2e87-393c-430f-98ce-5a2ba2f09df1 /192.168.10.117 consumer-console-consumer-75164-1
8.消费者、生产者性能测试脚本 kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
Flume搭建 1.Flume解压及安装
将apache-flume-1.9.0-bin.tar.gz上传到linux的/opt/software目录下
解压apache-flume-1.9.0-bin.tar.gz到/opt/module/目录下
1 [atguigu@hadoop102 software]$ tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
修改apache-flume-1.9.0-bin的名称为flume
1 [atguigu@hadoop102 module]$ mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume
2.Flume配置 将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
1 [atguigu@hadoop102 module]$ rm /opt/module/flume/lib/guava-11.0.2.jar
注意:删除guava-11.0.2.jar(google的一个java基础类库)的服务器节点,一定要配置hadoop环境变量。否则会报如下异常。
1 2 3 4 5 6 Caused by: java.lang.ClassNotFoundException: com.google.common.collect.Lists at java.net.URLClassLoader.findClass(URLClassLoader.java:382) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) ... 1 more
将flume/conf下的flume-env.sh.template文件修改为flume-env.sh,并配置flume-env.sh文件
1 2 3 [atguigu@hadoop102 conf]$ mv flume-env.sh.template flume-env.sh [atguigu@hadoop102 conf]$ vi flume-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_212
3.Flume测试 将Flume进行分发。创建一个Flume的测试配置脚本进行测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # Name the components on this agent #a1:表示agent的名称 #r1:表示a1的输入源 #k1:表示a1的 输出目的地 #c1:表示a1的缓冲区 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat #表示a1的输入源类型为netcat端口类型 a1.sources.r1.bind = hadoop116 #表示a1的监听的主机 a1.sources.r1.port = 44444 #表示监听a1的监听的端口号 # Describe the sink a1.sinks.k1.type = logger #表示a1的输出目的地是控制台logger类型 # Use a channel which buffers events in memory a1.channels.c1.type = memory #表示a1的channel类型是memory内存型 a1.channels.c1.capacity = 1000 #表示a1的channel总容量1000个event a1.channels.c1.transactionCapacity = 100 #表示a1的channel传输时收集到了100条event以后再去提交事务 # Bind the source and sink to the channel a1.sources.r1.channels = c1 #表示将r1和c1连接起来 a1.sinks.k1.channel = c1 #表示将k1和c1连接起来
安装工具:
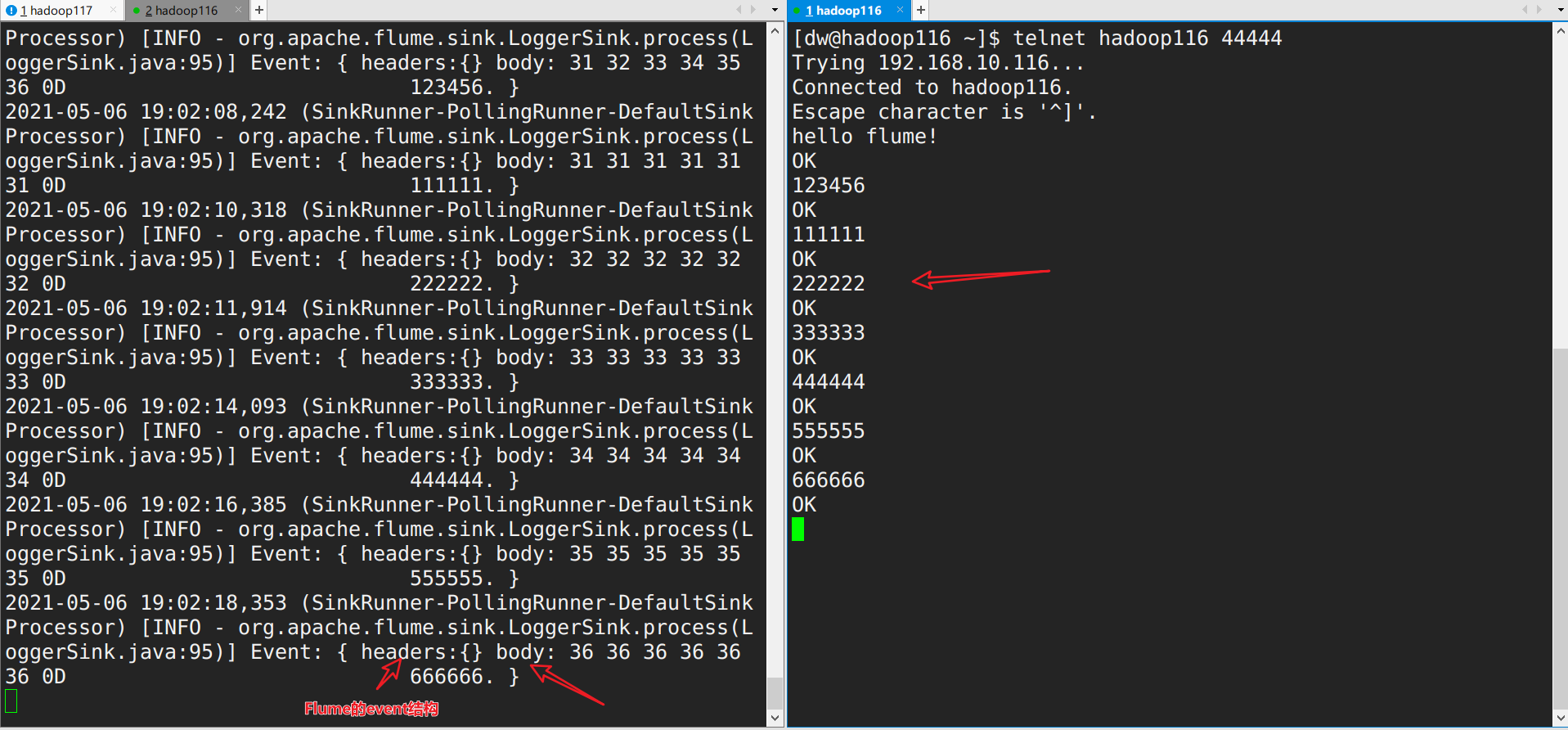
开始测试:
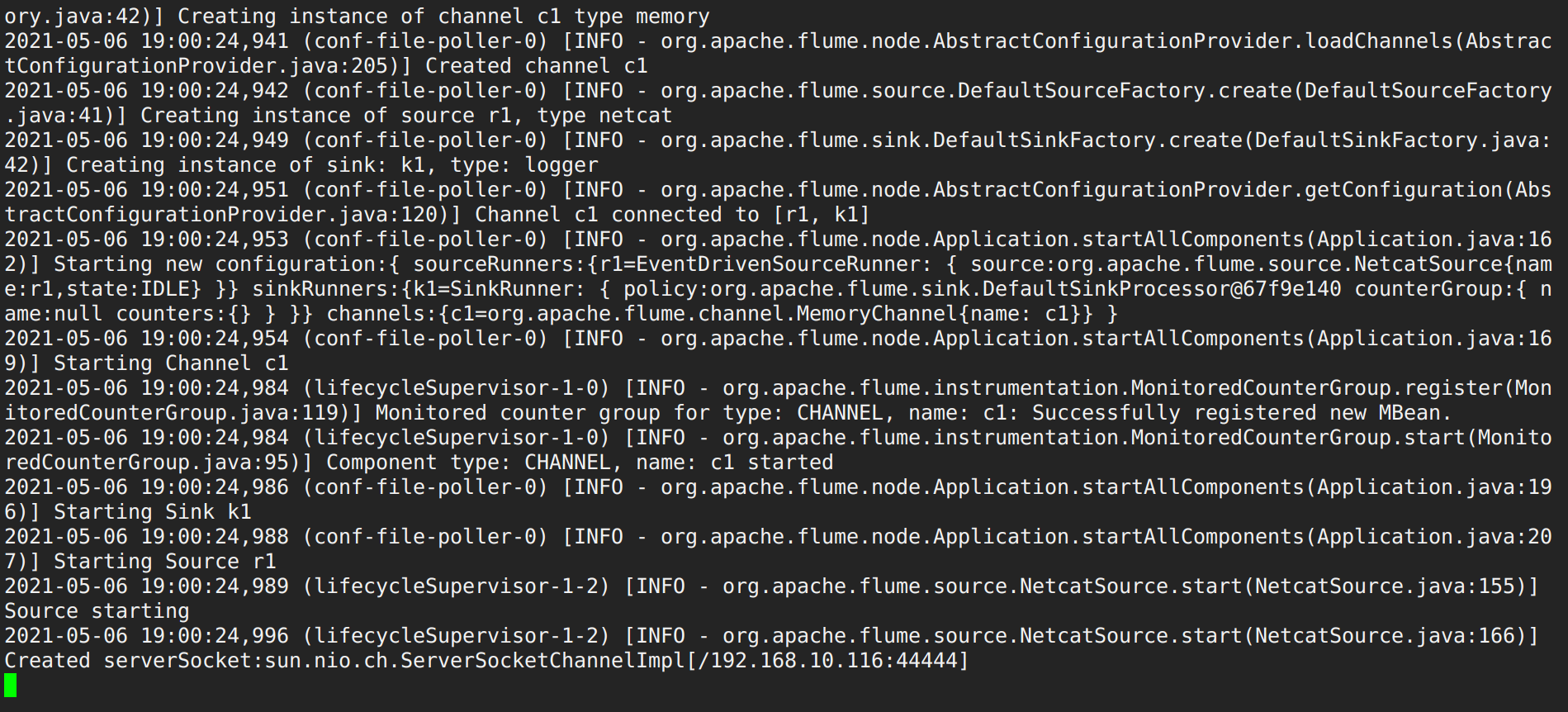
1.开启flume监听端口 1 [dw@hadoop116 flume]$ ./bin/flume-ng agent -n a1 -c conf/ -f conf/flume-netcat.conf -Dflume.root.logger=info,console
2.另开一个终端输入信息进行测试
日志采集平台搭建方案 Flume选型 Source Taildir Source相比Exec Source、Spooling Directory Source的优势:
TailDir Source:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
Exec Source可以执行一个shell脚本,实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
比如使用tail -f命令监控文件,如果shell命令出错,这段时间的数据仍会追加到文件里,但是tail -f只能读取末尾新加的几行,于是就丢失数据了。
Spooling Directory Source监控目录,支持断点续传。
文件一旦放入监控的目录,就不能再添加数据或者对文件进行改名等操作,所以一定要等文件写完后才能完监控目录里放,所以延迟性较高。
如果要用它实现实时监控,可以设置文件每10s一个,实现一个近乎实时的效果,但是由于有了taildir,所以不再需要了。
batchSize大小如何设置?
批处理,往channel里放数据,一次放多少批合适?Event 1K左右时,500-1000合适(默认为100)
Channel 采用Kafka Channel,省去了Sink,提高了效率。KafkaChannel数据存储在Kafka里面,所以数据是存储在磁盘中。
注意在Flume1.7以前,Kafka Channel很少有人使用,因为发现parseAsFlumeEvent这个配置起不了作用。也就是无论parseAsFlumeEvent配置为true还是false,都会转为Flume Event。这样的话,造成的结果是,会始终都把Flume的headers中的信息混合着内容一起写入Kafka的消息中,这显然不是我所需要的,我只是需要把内容写入即可。
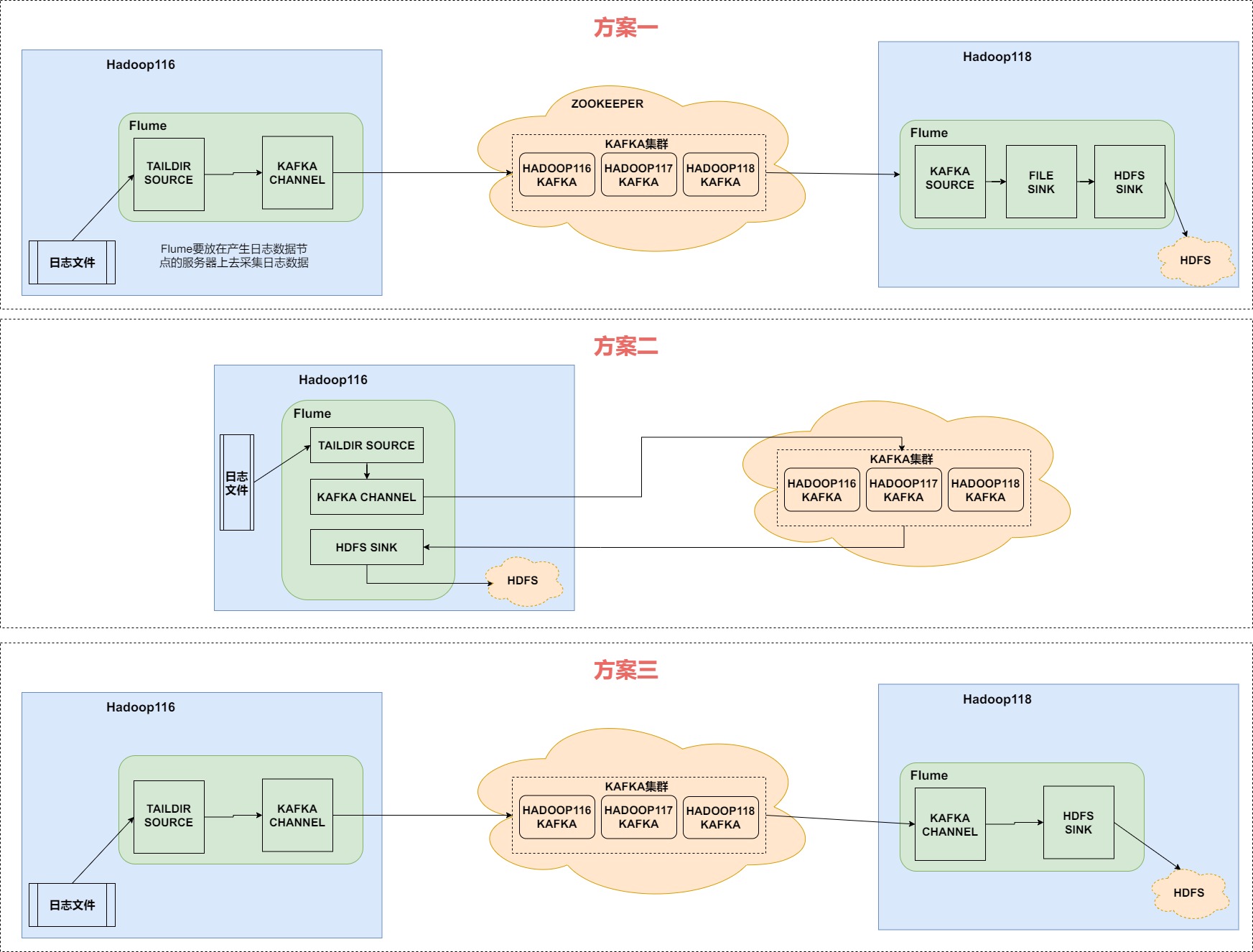
日志数据采集平台的三种搭建方案
首先,方案一和方案三,方案二显得更加简介,但是方案二并不好,因为日志埋点数据经过Flume输入到Kafka,接着又从Kafka经过Flume输入到HDFS,两进两出,对Flume压力较大,所以不好。
这里我们采取方案一来进行日志数据采集平台的搭建。
日志数据采集平台搭建 Flume->Kafka配置 首先,我们要配置Flume,Flume在整个日志数据采集平台中起着承上启下的重要作用。
首先是编写Flume到Kafka Channel的配置文件taildir_kafka.conf:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 # 先给每个组件命名 # a代表agent,是flume的一个application # 两个source: a1.sources= r1 r2 a1.sources= r1 a1.channels= c1 # 配置source a1.sources.r1.type= TAILDIR # 一个文件组就匹配一个正则表达式 a1.sources.r1.filegroups= f1 # regular: "."是任意字符,"*"是前面一个字符任意个,"+"至少是一个,不能为0 a1.sources.r1.filegroups.f1= /opt/module/applog/log/app.* # positionFile实现断点续传,flume将文件采集点记录到该文件中以实现断点续传,因为是个文件,所以flume挂掉后还能继续读 a1.sources.r1.positionFile= /opt/module/flume/taildir_position.json ## 拦截器 ### 拦截器个数 a1.sources.r1.interceptors = i1 ### 拦截器所需要的类包 a1.sources.r1.interceptors.i1.type = com.everweekup.gmall.flume.interceptor.LogInterceptor$Builder # 配置channel a1.channels.c1.type= org.apache.flume.channel.kafka.KafkaChannel ## 参数显示以","分隔 a1.channels.c1.kafka.bootstrap.servers = hadoop116:9092, hadoop117:9092 a1.channels.c1.kafka.topic= topic_log ## 该参数默认是true,就是是否按照flume event的header和body进行解析有两个角度 ### kafka channel有时候通过flume的source往kafka写数据| flume往kafka写数据时是否保留event结构(header+body(真正数据)),true表示有header,flase则只有body ### 有时候是通过flume sink往hdfs读数据 | kafka将record读入hdfs时需不需要保留flume的header a1.channels.c1.parseAsFlumeEvent= false # 绑定sink与channel和source与channel的关系 a1.sources.r1.channels= c1 ## 一个source可以对应多个channel,一个channel可以对应多个sink,但是多个sink不能对应一个channel,这里前面我们不用sink # a1.sink.k1.channel= c1
flume官方文档找配置参数
Flume直接读log日志的数据,log日志的格式是app.yyyy-mm-dd.log。
拦截器用于文件过滤,日志的分类等。这里用来做日志的清洗,校验日志的格式。(比如说校验符合json格式的日志文件)
kafka channel有三种情况,channel是一边put一遍take。对于kafka来讲就是生产者和消费者。第一种既有生产者也有消费者,第二种只有生产者,第三种只有消费者。我们这部分是只有生产者。
以下是官方文档里kafka channel的参数:
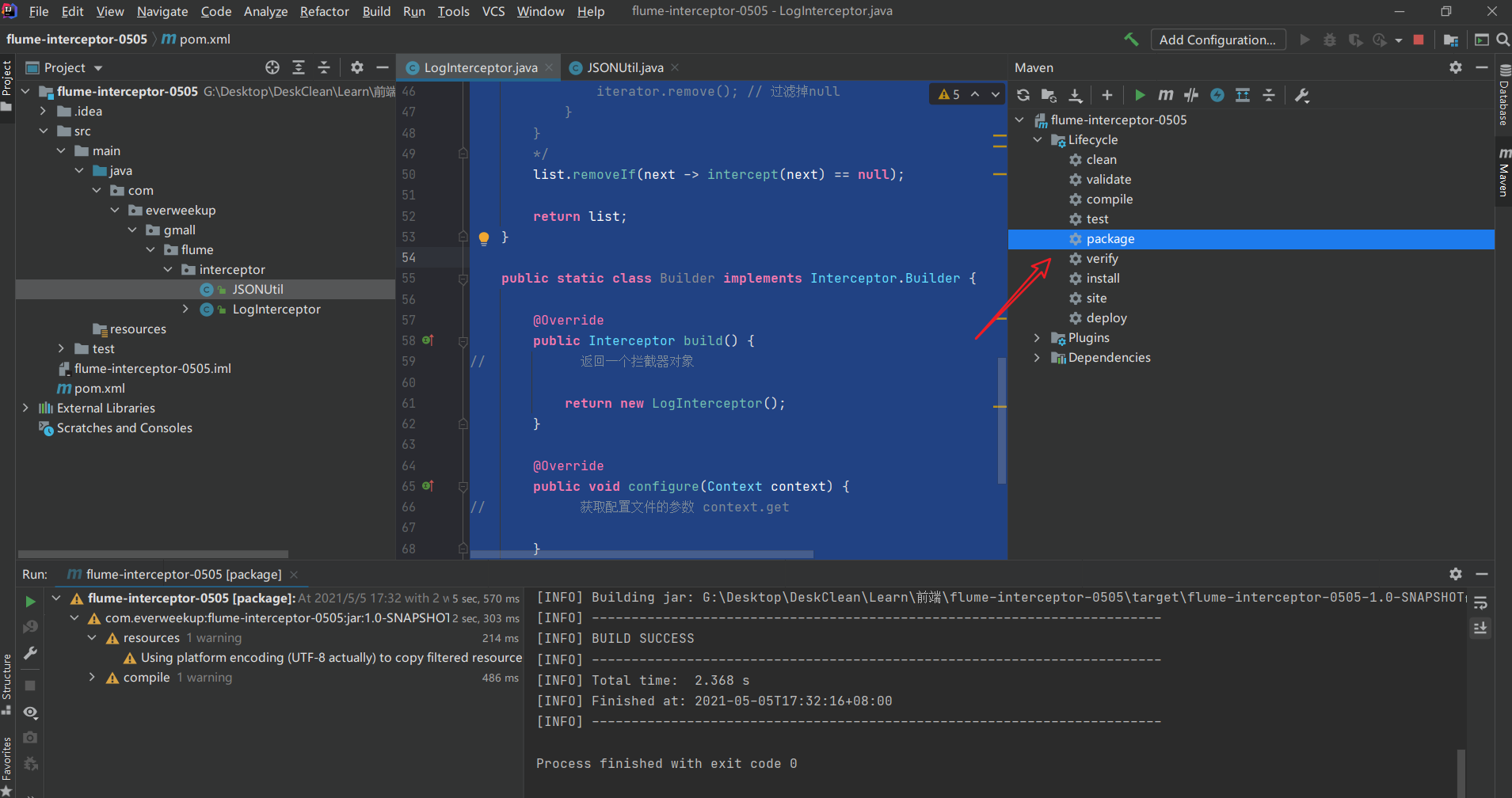
Interceptor校验json格式数据脚本编写 首先创建一个Maven工程,配置依赖和插件文件:
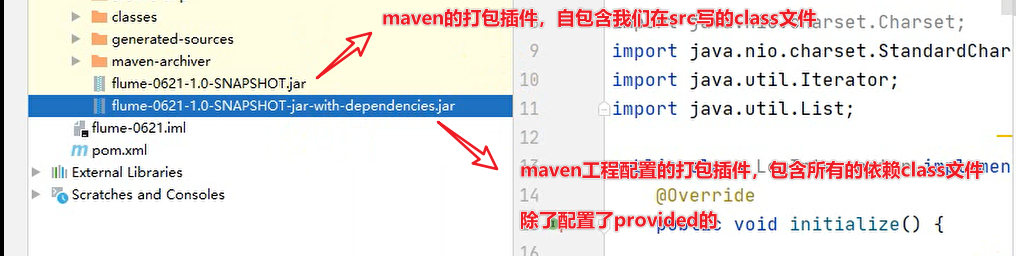
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 <dependencies > <dependency > <groupId > org.apache.flume</groupId > <artifactId > flume-ng-core</artifactId > <version > 1.9.0</version > <scope > provided</scope > </dependency > <dependency > <groupId > com.alibaba</groupId > <artifactId > fastjson</artifactId > <version > 1.2.62</version > </dependency > </dependencies > <build > <plugins > <plugin > <artifactId > maven-compiler-plugin</artifactId > <version > 2.3.2</version > <configuration > <source > 1.8</source > <target > 1.8</target > </configuration > </plugin > <plugin > <artifactId > maven-assembly-plugin</artifactId > <configuration > <descriptorRefs > <descriptorRef > jar-with-dependencies</descriptorRef > </descriptorRefs > </configuration > <executions > <execution > <id > make-assembly</id > <phase > package</phase > <goals > <goal > single</goal > </goals > </execution > </executions > </plugin > </plugins > </build >
首先,写一个JSON验证工具类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package com.everweekup.gmall.flume.interceptor;import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.JSONException;public class JSONUtil { public static boolean validateJSON (String log) { try { JSON.parse(log); return true ; }catch (JSONException e){ return false ; } } }
编写代码,实现Interceptor接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 package com.everweekup.gmall.flume.interceptor;import org.apache.flume.Context;import org.apache.flume.Event;import org.apache.flume.interceptor.Interceptor;import org.mortbay.util.ajax.JSON;import java.nio.charset.Charset;import java.nio.charset.StandardCharsets;import java.util.Iterator;import java.util.List;public class LogInterceptor implements Interceptor { @Override public void initialize () { } @Override public Event intercept (Event event) { byte [] body = event.getBody(); String log = new String (body, StandardCharsets.UTF_8); if (JSONUtil.validateJSON(log)){ return event; }else { return null ; } } @Override public List<Event> intercept (List<Event> list) { Iterator<Event> iterator = list.iterator(); list.removeIf(next -> intercept(next) == null ); return list; } public static class Builder implements Interceptor .Builder { @Override public Interceptor build () { return new LogInterceptor (); } @Override public void configure (Context context) { } } @Override public void close () { } }
最后进行打包:
接着把打好的包放在flume的lib目录下。
再配置interceptor.type的全类名com.everweekup.gmall.flume.interceptor.LogInterceptor$Builder,注意,不是LogInterceptor 。
Flume->Kafka测试 在flume根目录创建一个jobs文件夹,用于存放配置文件。
1 2 3 4 5 [dw@hadoop116 flume]$ ls bin CHANGELOG conf DEVNOTES doap_Flume.rdf docs lib LICENSE NOTICE README.md RELEASE-NOTES tools [dw@hadoop116 flume]$ mkdir jobs [dw@hadoop116 flume]$ cd jobs / [dw@hadoop116 jobs ]$ vim taildir_kafka.conf
将之前写好的interceptor包上传到lib目录。
启动消费者,用于查看flume是否往topic_log里写了数据。
这里由于原先kafka里并没有topic_log这个topic,kafka会帮我们自动创建该topic,自动创建的topic是单分区,单副本。
1 2 [dw@hadoop117 ~]$ kafka-console-consumer.sh --bootstrap-server hadoop116:9092 --topic topic_log [2021-05-05 19:24:17,615] WARN [Consumer clientId=consumer-console-consumer-95017-1, groupId=console-consumer-95017] Error while fetching metadata with correlation id 2 : {topic_log=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
执行flume命令采集日志数据:
1 [dw@hadoop116 flume]$ ./bin/flume-ng agent -n a1 -c conf/ -f jobs /taildir_kafka.conf -Dflume.root.logger=info,console
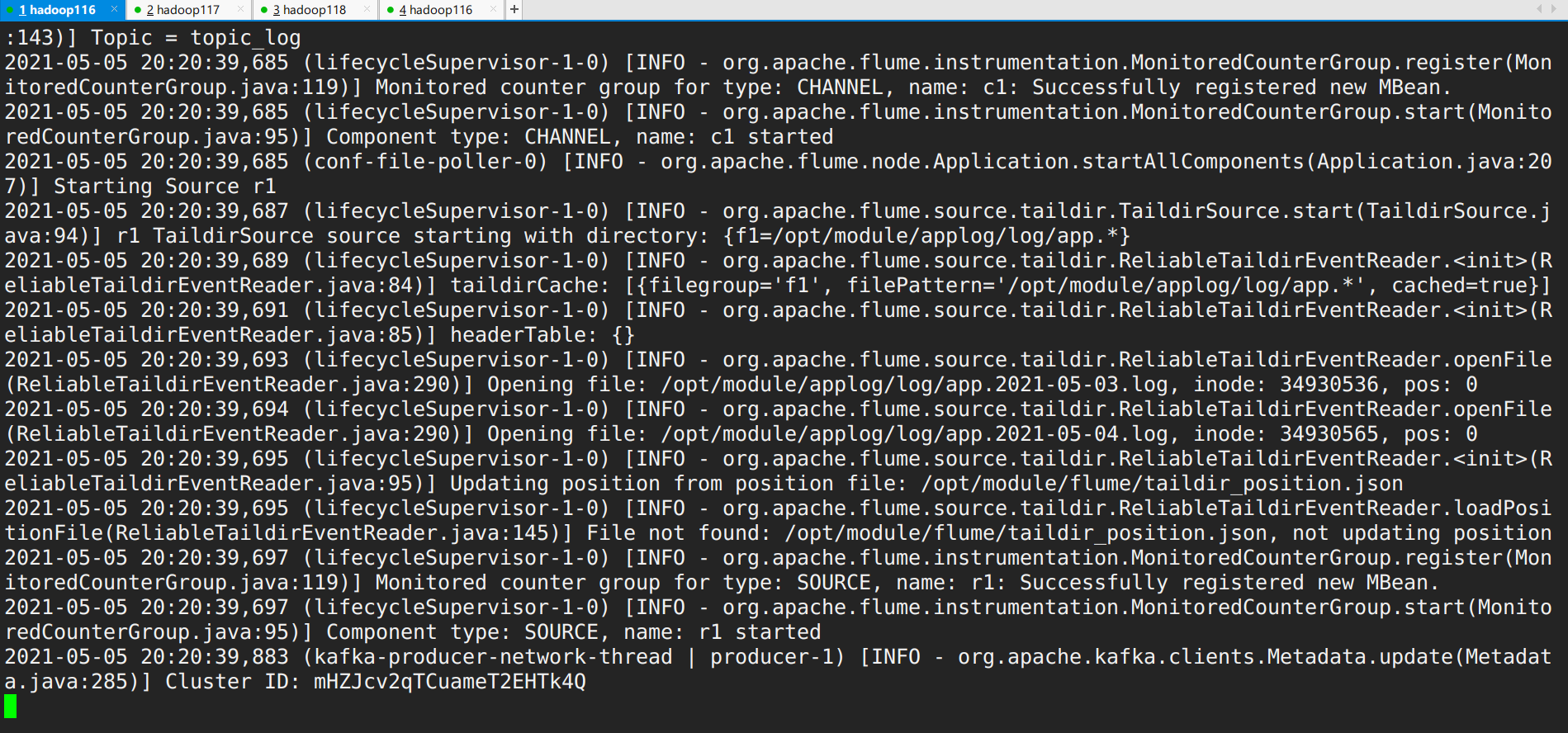
flume启动后会自动检测日志文件的log目录进行采集,consumer结果如图:
测试完成。
Flume启停脚本 在用户目录的bin目录下创建f1.sh脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 case $1 in start ) for i in hadoop116 hadoop117; do echo "==========$i==========" ssh $i "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/jobs/taildir_kafka.conf -Dflume.root.logger=info,console > /dev/null 2>&1 &" done ;; stop ) for i in hadoop116 hadoop117; do echo "==========$i==========" ssh $i "ps -ef | awk '/taildir_kafka.conf/ && !/awk/ {print /$2}' | xargs kill -9" done ;; esac
测试脚本:
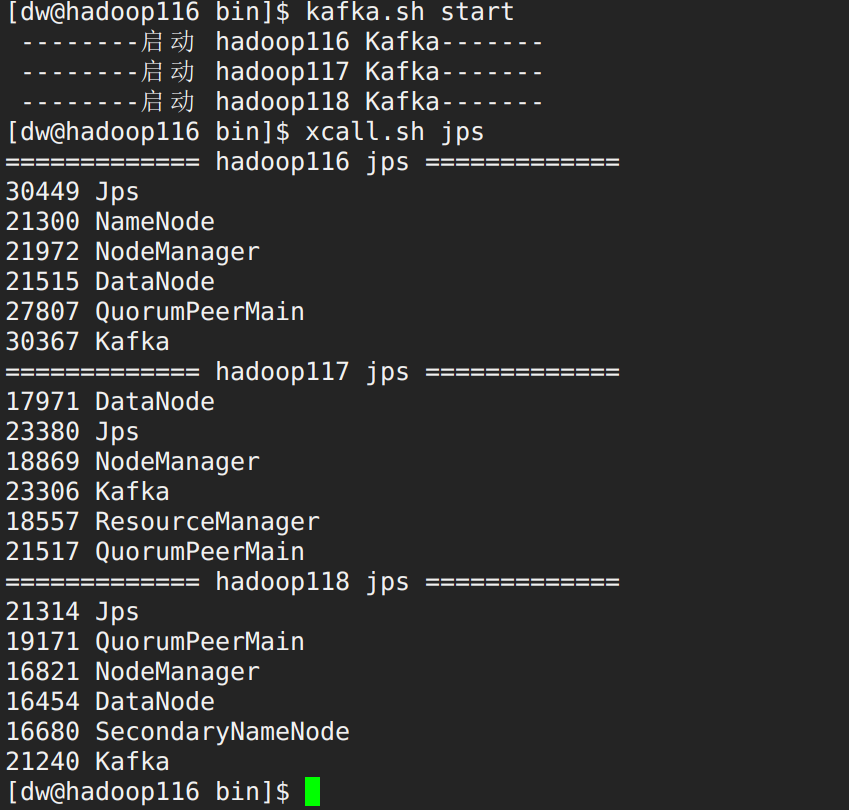
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 [dw@hadoop116 lib]$ f1.sh start ==========hadoop116========== ==========hadoop117========== [dw@hadoop116 lib]$ xcall.sh jps ============= hadoop116 jps ============= 21300 NameNode 21972 NodeManager 40455 Jps 37706 Kafka 21515 DataNode 27807 QuorumPeerMain 40335 Application ============= hadoop117 jps ============= 17971 DataNode 30595 Application 18869 NodeManager 30711 Jps 18557 ResourceManager 21517 QuorumPeerMain 29789 Kafka [dw@hadoop116 lib]$ f1.sh stop ==========hadoop116========== ==========hadoop117========== [dw@hadoop116 lib]$ xcall.sh jps ============= hadoop116 jps ============= 21300 NameNode 21972 NodeManager 37706 Kafka 21515 DataNode 40509 Jps 27807 QuorumPeerMain ============= hadoop117 jps ============= 17971 DataNode 30756 Jps 18869 NodeManager 18557 ResourceManager 21517 QuorumPeerMain 29789 Kafka ============= hadoop118 jps ============= 28561 Kafka 29874 Jps 19171 QuorumPeerMain 16821 NodeManager 16454 DataNode 16680 SecondaryNameNode
为了能够自由针对某个配置进行kill flume,对脚本进行改进:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 case $1 in start ) for i in hadoop116 hadoop117; do echo "==========$i==========" ssh $i "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/jobs/taildir_kafka.conf -Dflume.root.logger=info,console > /dev/null 2>&1 &" done ;; stop ) for i in hadoop116 hadoop117; do echo "==========$i==========" # ""里存在需要转义的字符,使用转义字符\,避免""将$2解析成传入的参数 ssh $i "ps -ef | awk '/$2/ && !/awk/ {print \$2}' | xargs kill -9 > /dev/null 2>&1 &" done ;; esac
Kafka Channel -> Flume -> HDFS配置 配置flume配置文件kafka_file_hdfs.conf:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 ## 组件 a1.sources=r1 a1.channels=c1 a1.sinks=k1 ## source1 ### kafka source底层本质是kafka 消费者 a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource ### 批大小 a1.sources.r1.batchSize = 5000 ### 一批数据达到指定大小,无论批次达到没,都会写入channel | 批次和时间配合使用 a1.sources.r1.batchDurationMillis = 2000 a1.sources.r1.kafka.bootstrap.servers = hadoop116:9092,hadoop117:9092,hadoop118:9092 a1.sources.r1.kafka.topics=topic_log a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimeStampInterceptor$Builder ## channel1 ### channel使用file,写磁盘 a1.channels.c1.type = file ### event索引内存队列快照 a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1 ### 存储event文件 a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/ ### 指单个文件的最大值(即一个文件大小是有限的,达到了重新创建一个文件继续写) a1.channels.c1.maxFileSize = 2146435071 ### 内存队列最大可以存储的event索引量 a1.channels.c1.capacity = 1000000 ### 以s为单位,等待put事务操作的时间 a1.channels.c1.keep-alive = 6 ## sink1 a1.sinks.k1.type = hdfs ### 正常来说路径:hdfs://hadoop116:8020/origin_data/gmall/log/topic_log/%Y-%m-%d ### 因为flume启动时会加载HADOOP_HOME的配置文件,所以这里不需要写前缀。如果flume只是单独的一个节点,没有配置hadoop,这时就需要补全了。 a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d a1.sinks.k1.hdfs.filePrefix = log- ### 如果不是单个小时去计算设置路径,比如说5个小时计算一次,就需要把它设置为true a1.sinks.k1.hdfs.round = false ## 上面参数设置为true,配置下面的实现5h计算一次 # a1.sinks.k1.hdfs.roundValue= 5 # a1.sinks.k1.hdfs.roundUnit= hour ### 防止生成大量小文件:生成新文件策略 ### interval 按照时间滚动文件,10s生成一个新文件 | 根据数据生成速度设置 ### 这里时间要设置大一点,免得文件不够128m。倒是map切分也好切分 a1.sinks.k1.hdfs.rollInterval = 10 ### rollsize:按照文件大小 | 128mb a1.sinks.k1.hdfs.rollSize = 134217728 ### rollcount:按照event数量生成文件 | 设置为0关闭 a1.sinks.k1.hdfs.rollCount = 0 ## 控制输出文件是原生文件。 ### 数据压缩 a1.sinks.k1.hdfs.fileType = CompressedStream ### lzo压缩 ### 这里用Lzo是为了将文件切片,但是前面我们已经设置了文件的切分方式128m,所以这里也可以不配置lzo,使用snappy会快一点,具体看情景 a1.sinks.k1.hdfs.codeC = lzop ## 拼装 a1.sources.r1.channels = c1 a1.sinks.k1.channel= c1
hdfs sink到hdfs上,最好一天一个路径。我们可以根据flume的event当中的一个header的key时间戳来决定放到什么路径。但是,由于我们的数据是没有flume event的header结构的(前面将参数配置了不按照flume event结构来解析),所以我们可以配置一些参数来解决:
本地时间是指flume节点机器的时间节点,但这显然不合理,我们应该以日志文件数据本身的timestamp,所以可以通过拦截器来设置,所以后面消费kafka的flume也需要写一套拦截器。
TimeStampInterceptor拦截器配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 package com.everweekup.gmall.flume.interceptor;import com.alibaba.fastjson.JSONObject;import org.apache.flume.Context;import org.apache.flume.Event;import org.apache.flume.interceptor.Interceptor;import java.nio.charset.Charset;import java.nio.charset.StandardCharsets;import java.util.List;public class TimeStampInterceptor implements Interceptor { @Override public void initialize () { } @Override public Event intercept (Event event) { byte [] body= event.getBody(); String log = new String (body, StandardCharsets.UTF_8); JSONObject jsonObj = JSONObject.parseObject(log); if (jsonObj.containsKey("ts" )){ String ts = jsonObj.getString("ts" ); event.getHeaders().put("timestamp" , ts); } return event; } @Override public List<Event> intercept (List<Event> list) { for (Event event : list) { intercept(event); } return list; } public static class Builder implements Interceptor .Builder { @Override public Interceptor build () { return new TimeStampInterceptor (); } @Override public void configure (Context context) { } } @Override public void close () { } }
测试Flume -> Kafka -> Flume -> HDFS 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 [dw@hadoop116 /]$ zkS.sh start ---------- zookeeper hadoop116 启动 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ---------- zookeeper hadoop117 启动 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ---------- zookeeper hadoop118 启动 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [dw@hadoop116 /]$ zkS.sh status ---------- zookeeper hadoop116 状态 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: follower ---------- zookeeper hadoop117 状态 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: leader ---------- zookeeper hadoop118 状态 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: follower ++++++++++++++++++++++++++++++++++++++++ [dw@hadoop116 ~]$ kafka.sh start --------启动 hadoop116 Kafka------- --------启动 hadoop117 Kafka------- --------启动 hadoop118 Kafka------- [dw@hadoop116 ~]$ xcall.sh jps ============= hadoop116 jps ============= 46193 Jps 44546 DataNode 44389 NameNode 44841 NodeManager 46158 Kafka ============= hadoop117 jps ============= 36128 Kafka 33881 ResourceManager 33707 DataNode 34139 NodeManager 36159 Jps ============= hadoop118 jps ============= 34581 Jps 34550 Kafka 33324 NodeManager 33117 DataNode 33231 SecondaryNameNode ++++++++++++++++++++++++++++++++++++++++ [dw@hadoop116 ~]$ f1.sh start taildir_kafka.conf [dw@hadoop118 flume]$ ./bin/flume-ng agent -n a1 -c conf/ -f jobs /kafka_file_hdfs.conf -Dflume.root.logger=info,console [dw@hadoop116 ~]$ xcall.sh jps ============= hadoop116 jps ============= 45601 Jps 44546 DataNode 44389 NameNode 44841 NodeManager 45439 Application ============= hadoop117 jps ============= 34966 Jps 34808 Application 33881 ResourceManager 33707 DataNode 34139 NodeManager ============= hadoop118 jps ============= 34040 Jps 33324 NodeManager 33117 DataNode 33918 Application 33231 SecondaryNameNode ++++++++++++++++++++++++++++++++++++++++ [dw@hadoop116 ~]$ log.sh ==========hadoop116========== ==========hadoop117==========
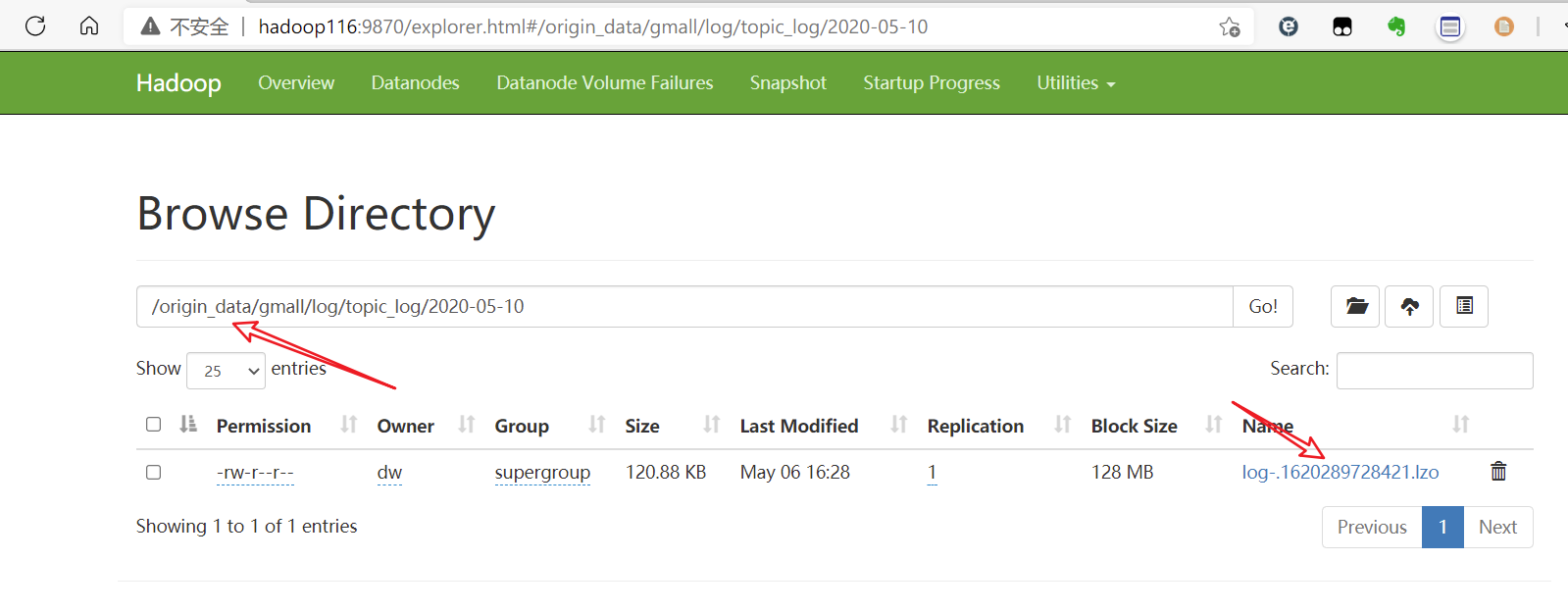
查看HDFS是否有数据:
测试完成。
日志采集流程启停脚本 1.Hadoop集群启停脚本——hdp.sh 1 2 3 4 5 6 7 8 9 10 11 12 13 14 # !/bin/bash case $1 in start ) echo "==========$i==========" ssh hadoop116 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh" ssh hadoop117 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh" ;; stop ) echo "==========$i==========" ssh hadoop116 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" ssh hadoop117 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh" ;; esac
2.整体启停脚本——cluster.sh 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 # !/bin/bash case $1 in "start"){ echo ================== 启动 集群 ================== #启动 Zookeeper集群 /home/dw/bin/zkS.sh start #启动 Hadoop集群 /home/dw/bin/hdp.sh start #启动 Kafka采集集群 /home/dw/bin/kafka.sh start #启动 Flume采集集群 /home/dw/bin/f1.sh start taildir_kafka.conf #启动 Flume消费集群 /home/dw/bin/f2.sh start };; "stop"){ echo ================== 停止 集群 ================== #停止 Flume消费集群 /home/dw/bin/f2.sh stop #停止 Flume采集集群 /home/dw/bin/f1.sh stop taildir_kafka.conf #停止 Kafka采集集群 /home/dw/bin/kafka.sh stop #停止 Hadoop集群 /home/dw/bin/hdp.sh stop #停止 Zookeeper集群 /home/dw/bin/zkS.sh stop };; esac