
数据仓库从0到1之业务逻辑流程分析
数据仓库从0到1之业务逻辑流程分析
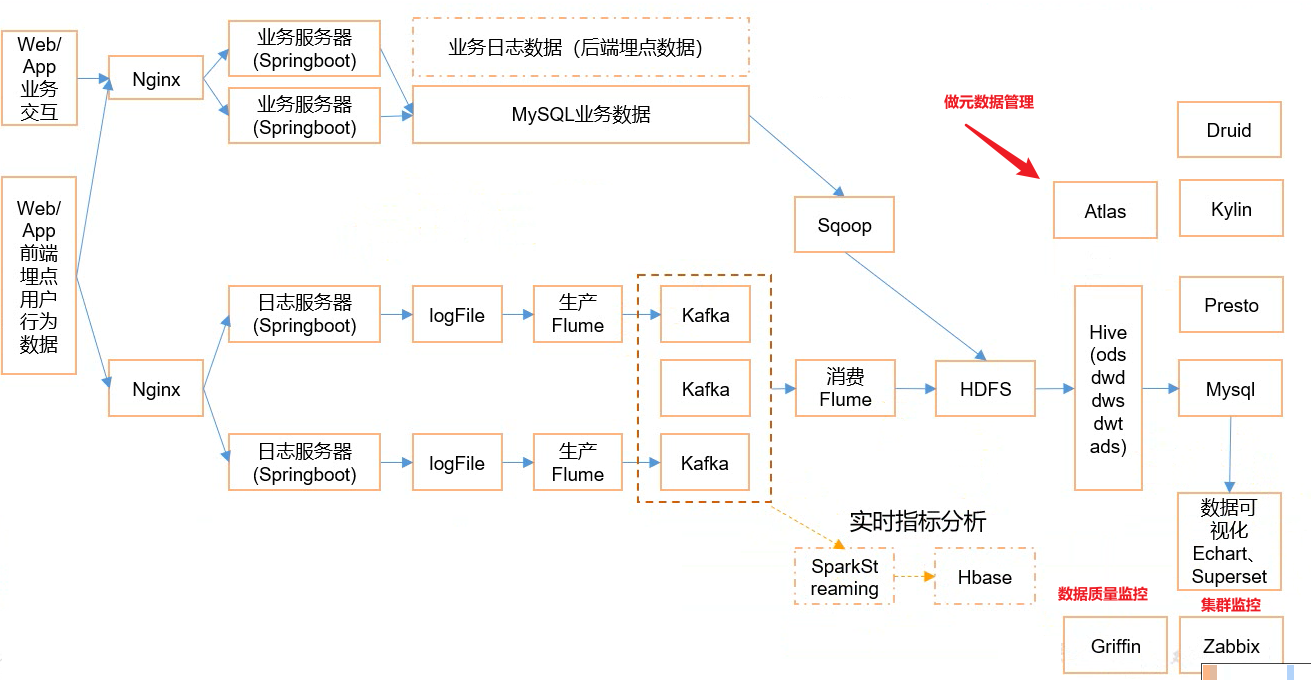
系统数据流程
从系统数据流程图可以看到,我们的数据主要分为mysql业务数据和业务日志数据。
业务日志数据产生模块分析
目标数据
我们要收集和分析的数据主要包括页面数据、事件数据、曝光数据、启动数据和错误数据。
页面数据
页面数据主要记录一个页面的用户访问情况,包括访问时间、停留时间、页面路径等信息。
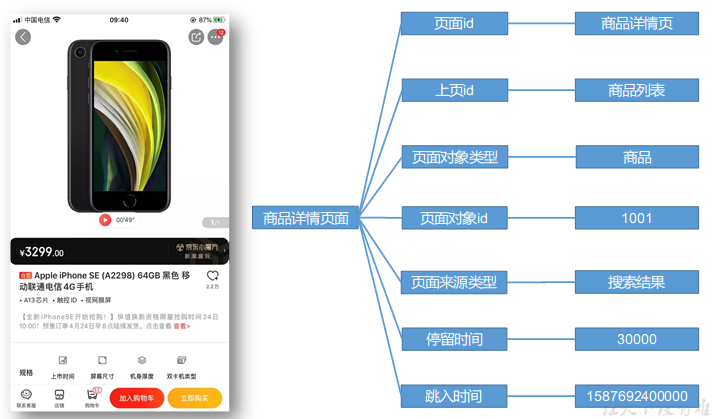
所有页面id
| home(“首页”), |
|---|
| category(“分类页”), |
| discovery(“发现页”), |
| top_n(“热门排行”), |
| favor(“收藏页”), |
| search(“搜索页”), |
| good_list(“商品列表页”), |
| good_detail(“商品详情”), |
| good_spec(“商品规格”), |
| comment(“评价”), |
| comment_done(“评价完成”), |
| comment_list(“评价列表”), |
| cart(“购物车”), |
| trade(“下单结算”), |
| payment(“支付页面”), |
| payment_done(“支付完成”), |
| orders_all(“全部订单”), |
| orders_unpaid(“订单待支付”), |
| orders_undelivered(“订单待发货”), |
| orders_unreceipted(“订单待收货”), |
| orders_wait_comment(“订单待评价”), |
| mine(“我的”), |
| activity(“活动”), |
| login(“登录”), |
| register(“注册”); |
所有页面对象类型
| sku_id(“商品skuId”), |
|---|
| keyword(“搜索关键词”), |
| sku_ids(“多个商品skuId”), |
| activity_id(“活动id”), |
| coupon_id(“购物券id”); |
所有来源类型
| promotion(“商品推广”), |
|---|
| recommend(“算法推荐商品”), |
| query(“查询结果商品”), |
| activity(“促销活动”); |
事件数据
事件数据主要记录应用内一个具体操作行为,包括操作类型、操作对象、操作对象描述等信息。
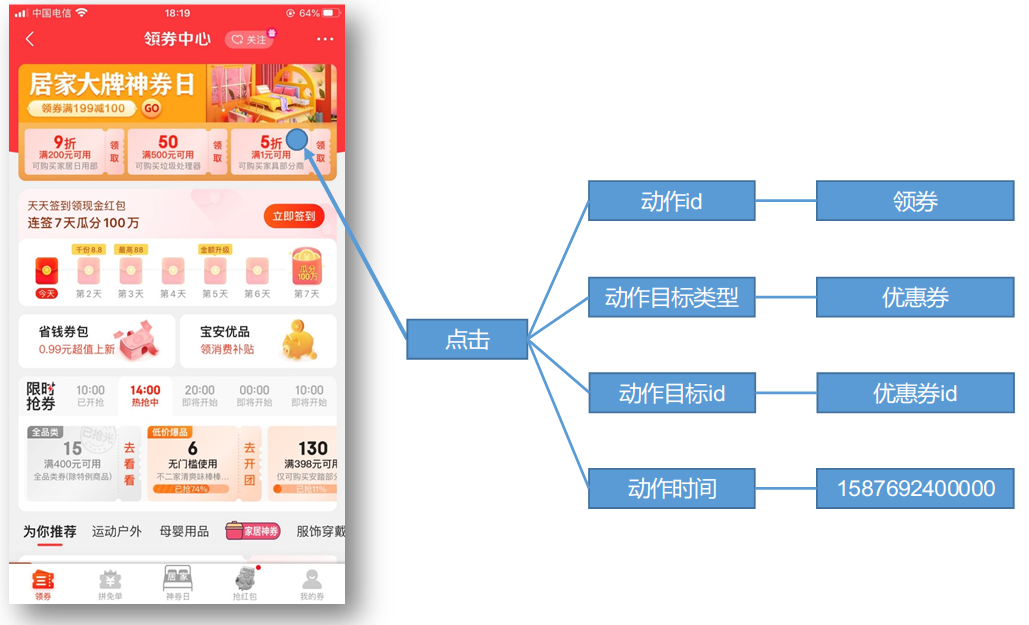
所动作类型
| favor_add(“添加收藏”), |
|---|
| favor_canel(“取消收藏”), |
| cart_add(“添加购物车”), |
| cart_remove(“删除购物车”), |
| cart_add_num(“增加购物车商品数量”), |
| cart_minus_num(“减少购物车商品数量”), |
| trade_add_address(“增加收货地址”), |
| get_coupon(“领取优惠券”); |
注:对于下单、支付等业务数据,可从业务数据库获取
所有动作目标类型
| sku_id(“商品”), |
|---|
| coupon_id(“购物券”); |
曝光数据
曝光数据主要记录页面所曝光的内容,包括曝光对象,曝光类型等信息。
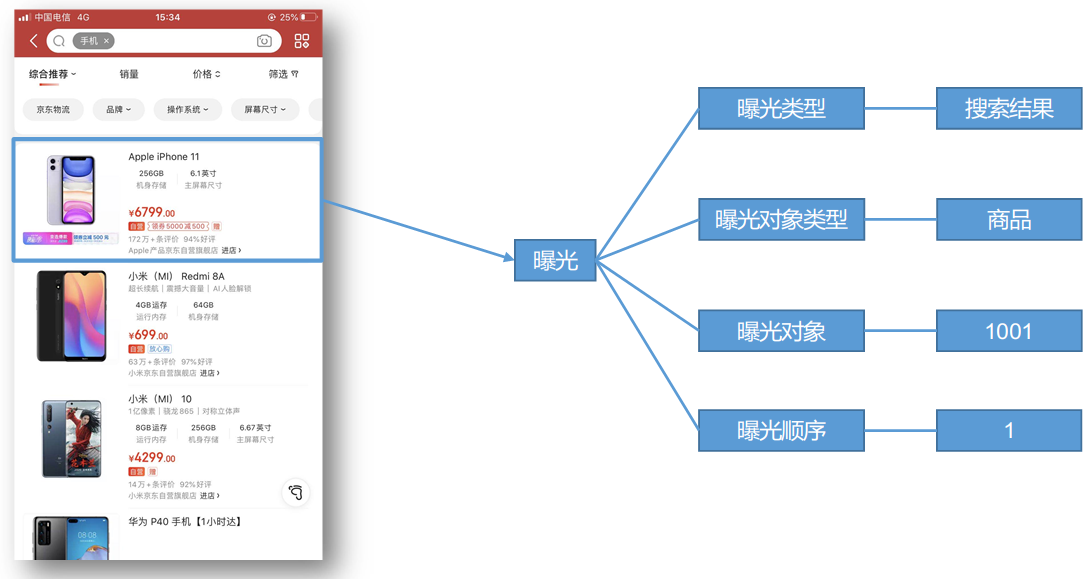
所有曝光类型
| promotion(“商品推广”) |
|---|
| recommend(“算法推荐商品”) |
| query(“查询结果商品”), |
| activity(“促销活动”); |
所有曝光对象类型
| sku_id(“商品skuId”), |
|---|
| activity_id(“活动id”); |
启动数据
启动数据记录应用的启动信息。
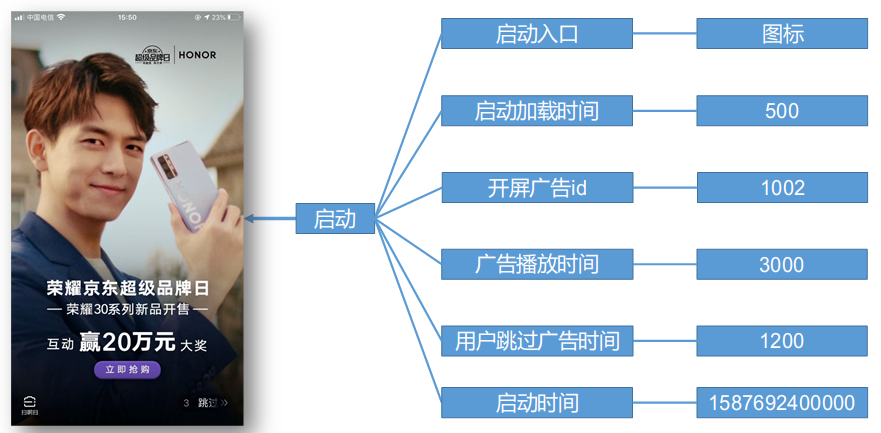
所有启动入口类型
| icon(“图标”), |
|---|
| notification(“通知”), |
| install(“安装后启动”); |
错误数据
错误数据记录应用使用过程中的错误信息,包括错误编号及错误信息。对错误信息的统计有利于我们对应用进行优化和改进。
总结
总的来说,我们电商数据仓库所需获取的数据有页面、事件、曝光、启动、错误五种类型,这些数据贯穿在用户启动应用浏览商品,收藏商品,购买商品等操作的整个流程中,对这些数据的分析有利于我们了解用户的偏好,商品的热门程度和顾客购买商品间的关联关系,有利于我们为客户提供更好的线上购物体验。
数据埋点(数据获取方式)
目前主流的埋点方式,有代码埋点(前端:在页面上利用JS记录信息发送请求/后端:在后台业务请求利用java代码嵌入埋点逻辑)、可视化埋点(图形化界面全选出要埋点的按钮或者输入框)、全埋点(采集全部数据,需要啥再过滤)三种。
代码埋点是通过调用埋点SDK(一些封装号的库,可以调用到前端函数调用库里的函数)函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick(点击事件) 函数里面调用SDK提供的数据发送接口,来发送数据。
可视化埋点只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
埋点数据日志结构
我们的日志结构大致可分为两类,一是普通页面埋点日志,二是启动日志。
普通页面日志结构如下,每条日志包含了,当前页面的页面信息,所有事件(动作)、所有曝光信息以及错误信息。除此之外,还包含了一系列公共信息,包括设备信息,地理位置,应用信息等,即下边的common字段。
普通页面埋点日志格式
1 | { |
启动日志格式
启动日志结构相对简单,主要包含公共信息,启动信息和错误信息。
1 | { |
埋点数据上报时间
埋点数据上报时机包括两种方式。
- 方式一,在离开该页面时,上传在这个页面产生的所有数据(页面、事件、曝光、错误等)。优点,批处理,减少了服务器接收数据压力。缺点,不是特别及时。
- 方式二,每个事件、动作、错误等,产生后,立即发送。优点,响应及时。缺点,对服务器接收数据压力比较大。
模拟数据
相应的脚本可以在下面的链接里获取。(包含本系列文章所有要用的软件脚本)
模拟数据脚本使用介绍
1.将application.properties、gmall2020-mock-log-2020-05-10.jar、path.json、logback.xml上传到hadoop102的/opt/module/applog目录下
- 创建applog路径
1 | [atguigu@hadoop102 module]$ mkdir /opt/module/applog |
- 上传文件
2.配置文件:
- application.properteis文件
可以根据需求生成对应日期的用户行为日志。
1 | [atguigu@hadoop102 applog]$ vim application.properties |
3.修改如下内容:
1 | # 外部配置打开 |
- path.json,该文件用来配置访问路径
根据需求,可以灵活配置用户点击路径。
1 | [ |
- logback配置文件
可配置日志生成路径,修改内容如下(和lg4j同源,都是对日志框架的实现)
1 |
|
3.生成日志
- 进入到/opt/module/applog路径,执行以下命令
1 | [atguigu@hadoop102 applog]$ java -jar gmall2020-mock-log-2020-05-10.jar |
- 在/opt/module/applog/log目录下查看生成日志
1 | [atguigu@hadoop102 log]$ ll |
集群日志生成脚本
在hadoop102的/home/atguigu目录下创建bin目录,这样脚本可以在服务器的任何目录执行。
1 | [atguigu@hadoop102 ~]$ echo $PATH |
- 在/home/atguigu/bin目录下创建脚本lg.sh
1 | [atguigu@hadoop102 bin]$ vim lg.sh |
- 在脚本中编写如下内容
1 | \#!/bin/bash |
注:
/opt/module/applog/为jar包及配置文件所在路径
/dev/null代表linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”
MySql业务数据
电商业务流程
电商的业务流程可以以一个普通用户的浏览足迹为例进行说明,用户点开电商首页开始浏览,可能会通过分类查询也可能通过全文搜索寻找自己中意的商品,这些商品无疑都是存储在后台的管理系统中的。
当用户寻找到自己中意的商品,可能会想要购买,将商品添加到购物车后发现需要登录,登录后对商品进行结算,这时候购物车的管理和商品订单信息的生成都会对业务数据库产生影响,会生成相应的订单数据和支付数据。
订单正式生成之后,还会对订单进行跟踪处理,直到订单全部完成。
电商的主要业务流程包括用户前台浏览商品时的商品详情的管理,用户商品加入购物车进行支付时用户个人中心&支付服务的管理,用户支付完成后订单后台服务的管理,这些流程涉及到了十几个甚至几十个业务数据表,甚至更多。
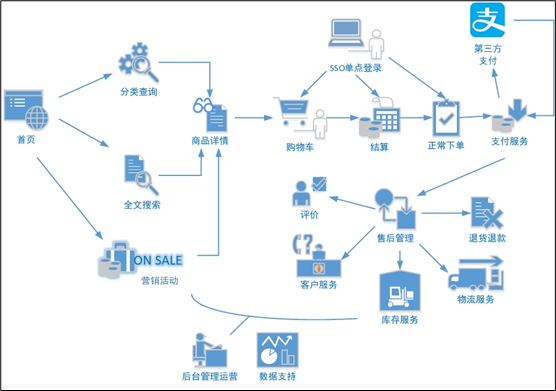
补充:SSO单点登陆
SSO单点登陆,当前网页一个页面登陆全局都能获取登陆状态。
在电商业务系统中,用户通过登陆首页进入电商页面,通过首先查询和搜索信息抵达商品详情页所在。
用户可以选择加入购物车后下单结算,结算前登陆账户进行结算,正常下完单或未付款后,数据会进入订单表。
订单结束后,售后相关信息入库售后表。
当后台管理运营想要做一个营销活动,通过统计或者活动的曝光率和参与活动的订单数等等,计算出转化率、回报率等指标,来反馈活动的效果,指导后续运营工作的开展。
电商常识
SKU=Stock Keeping Unit(库存量基本单位)。现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号。(把具体配置确定下来后才能确定有没有货)
SPU(Standard Product Unit):是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息集合。(比如IPhone10和IPhone11不能共用同一个商品信息)
例如:iPhoneX手机就是SPU。一台银色、128G内存的、支持联通网络的iPhoneX,就是SKU。
无论是SKU还是SPU都无法作为一件商品的唯一标识,两个描述的都是一类商品,只不过SKU描述的更细致。
SPU表示一类商品。好处就是:可以共用商品图片,海报、销售属性等。
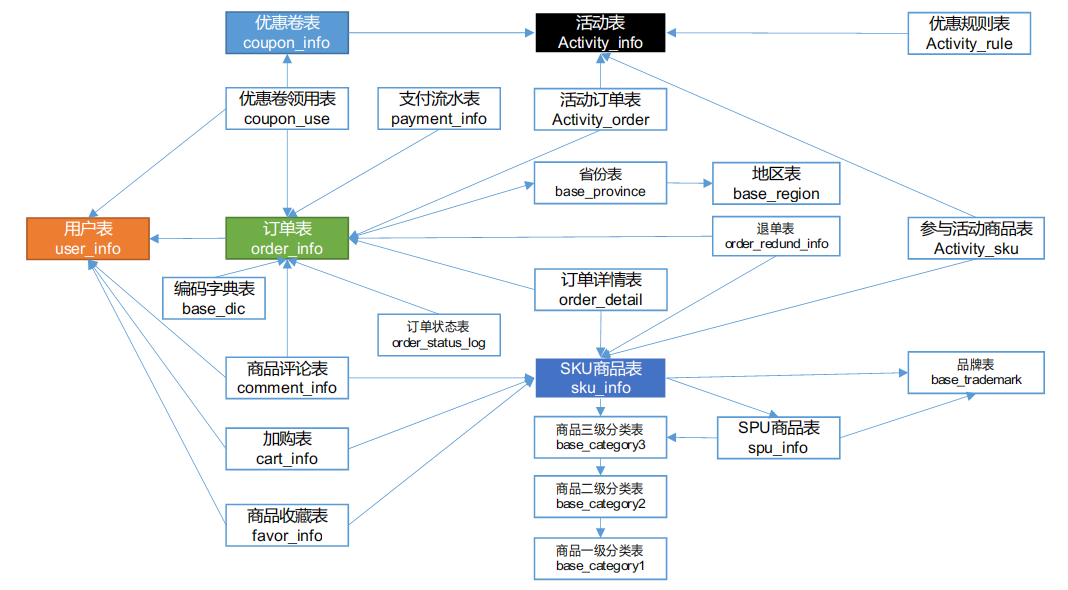
电商业务表结构
本电商数仓系统涉及到的业务数据表结构关系。这24个表以订单表、用户表、SKU商品表、活动表和优惠券表为中心,延伸出了优惠券领用表、支付流水表、活动订单表、订单详情表、订单状态表、商品评论表、编码字典表退单表、SPU商品表等,用户表提供用户的详细信息,支付流水表提供该订单的支付详情,订单详情表提供订单的商品数量等情况,商品表给订单详情表提供商品的详细信息。本次讲解只以此24个表为例,实际项目中,业务数据库中表格远远不止这些。
按照业务去捋顺表间关系。
订单表(order_info)
| 标签 | 含义 | |
|---|---|---|
| id | 订单编号 | |
| consignee | 收货人 | |
| consignee_tel | 收件人电话 | |
| final_total_amount | 总金额 | |
| order_status | 订单状态 | |
| user_id | 用户id | |
| delivery_address | 送货地址 | |
| order_comment | 订单备注 | |
| out_trade_no | 订单交易编号(第三方支付用) | |
| trade_body | 订单描述(第三方支付用) | |
| create_time | 创建时间 | |
| operate_time | 操作时间 | |
| expire_time | 失效时间 | |
| tracking_no | 物流单编号 | |
| parent_order_id | 父订单编号 | |
| img_url | 图片路径 | |
| province_id | 地区 | |
| benefit_reduce_amount | 优惠金额 | |
| original_total_amount | 原价金额 | |
| feight_fee | 运费 | |
订单详情表(order_detail)
| 标签 | 含义 | |
|---|---|---|
| id | 编号 | |
| order_id | 订单号 | |
| sku_id | 商品id | |
| sku_name | sku名称(冗余) | |
| img_url | 图片名称(冗余) | |
| order_price | 商品价格(下单时sku价格) | |
| sku_num | 商品数量 | |
| create_time | 创建时间 | |
| source_type | 来源类型 | |
| source_id | 来源编号 | |
SKU商品表(sku_info)
| 标签 | 含义 | |
|---|---|---|
| id | skuId | |
| spu_id | spuId | |
| price | 价格 | |
| sku_name | 商品名称 | |
| sku_desc | 商品描述 | |
| weight | 重量 | |
| tm_id | 品牌id | |
| category3_id | 品类id | |
| sku_default_img | 默认显示图片(冗余) | |
| create_time | 创建时间 | |
用户表(user_info)
| 标签 | 含义 | |
|---|---|---|
| id | 用户id | |
| login_name | 用户名称 | |
| nick_name | 用户昵称 | |
| passwd | 用户密码 | |
| name | 真实姓名 | |
| phone_num | 手机号 | |
| 邮箱 | ||
| head_img | 头像 | |
| user_level | 用户级别 | |
| birthday | 生日 | |
| gender | 性别:男=M,女=F | |
| create_time | 创建时间 | |
| operate_time | 操作时间 | |
商品一级分类表(base_category1)
| 标签 | 含义 | |
|---|---|---|
| id | id | |
| name | 名称 | |
商品二级分类表(base_category2)
| 标签 | 含义 | |
|---|---|---|
| id | id | |
| name | 名称 | |
| category1_id | 一级品类id | |
商品三级分类表(base_category3)
| 标签 | 含义 | |
|---|---|---|
| id | id | |
| name | 名称 | |
| Category2_id | 二级品类id | |
支付流水表(payment_info)
| 标签 | 含义 | |
|---|---|---|
| id | 编号 | |
| out_trade_no | 对外业务编号 | |
| order_id | 订单编号 | |
| user_id | 用户编号 | |
| alipay_trade_no | 支付宝交易流水编号 | |
| total_amount | 支付金额 | |
| subject | 交易内容 | |
| payment_type | 支付类型 | |
| payment_time | 支付时间 | |
省份表(base_province)
| 标签 | 含义 | |
|---|---|---|
| id | id | |
| name | 省份名称 | |
| region_id | 地区ID | |
| area_code | 地区编码 | |
| iso_code | 国际编码 | |
地区表(base_region)
| 标签 | 含义 | |
|---|---|---|
| id | 大区id | |
| region_name | 大区名称 | |
品牌表(base_trademark)
| 标签 | 含义 | |
|---|---|---|
| tm_id | 品牌id | |
| tm_name | 品牌名称 | |
订单状态表(order_status_log)
| 标签 | 含义 | |
|---|---|---|
| id | 编号 | |
| order_id | 订单编号 | |
| order_status | 订单状态 | |
| operate_time | 操作时间(update time) | |
SPU商品表(spu_info)
| 标签 | 含义 | |
|---|---|---|
| id | 商品id | |
| spu_name | spu商品名称 | |
| description | 商品描述(后台简述) | |
| category3_id | 三级分类id | |
| tm_id | 品牌id | |
商品评论表(comment_info)
| 标签 | 含义 | |
|---|---|---|
| id | 编号 | |
| user_id | 用户id | |
| sku_id | 商品id | |
| spu_id | spu_id | |
| order_id | 订单编号 | |
| appraise | 评价 1 好评 2 中评 3 差评 | |
| comment_txt | 评价内容 | |
| create_time | 创建时间 | |
退单表(order_refund_info)
| 标签 | 含义 | |
|---|---|---|
| id | 编号 | |
| user_id | 用户id | |
| order_id | 订单编号 | |
| sku_id | sku_id | |
| refund_type | 退款类型 | |
| refund_amount | 退款金额 | |
| refund_reason_type | 原因类型 | |
| refund_reason_txt | 原因内容 | |
| create_time | 创建时间 | |
加购表(cart_info)
| 标签 | 含义 | |
|---|---|---|
| id | 编号 | |
| user_id | 用户id | |
| sku_id | SKU商品 | |
| cart_price | 放入购物车时价格 | |
| sku_num | 数量 | |
| img_url | 图片文件 | |
| sku_name | sku名称 (冗余) | |
| create_time | 创建时间 | |
| operate_time | 修改时间 | |
| is_ordered | 是否已经下单 | |
| order_time | 下单时间 | |
| source_type | 来源类型 | |
| source_id | 来源编号 | |
商品收藏表(favor_info)
| 标签 | 含义 | |
|---|---|---|
| id | 编号 | |
| user_id | 用户id | |
| sku_id | 商品id | |
| spu_id | spu_id | |
| is_cancel | 是否已取消 0 正常 1 已取消 | |
| create_time | 收藏时间 | |
| cancel_time | 修改时间 | |
优惠券领用表(coupon_use)
| 标签 | 含义 | |
|---|---|---|
| id | 编号 | |
| coupon_id | 购物券ID | |
| user_id | 用户ID | |
| order_id | 订单ID | |
| coupon_status | 优惠券状态 | |
| get_time | 领券时间 | |
| using_time | 使用时间(下单时间) | |
| used_time | 支付时间(支付了) | |
| expire_time | 过期时间 | |
优惠券表(coupon_info)
| 标签 | 含义 | |
|---|---|---|
| id | 优惠券编号 | |
| coupon_name | 优惠券名称 | |
| coupon_type | 优惠券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券 | |
| condition_amount | 满减金额 | |
| condition_num | 满减件数 | |
| activity_id | 活动编号 | |
| benefit_amount | 优惠金额 | |
| benefit_discount | 优惠折扣 | |
| create_time | 创建时间 | |
| range_type | 范围类型 1、商品 2、品类 3、品牌 | |
| spu_id | 商品id | |
| tm_id | 品牌id | |
| category3_id | 品类id | |
| limit_num | 最多领用次数 | |
| operate_time | 修改时间 | |
| expire_time | 过期时间 | |
活动表(activity_info)
| 标签 | 含义 | |
|---|---|---|
| id | 活动id | |
| activity_name | 活动名称 | |
| activity_type | 活动类型 | |
| activity_desc | 活动描述 | |
| start_time | 开始时间 | |
| end_time | 结束时间 | |
| create_time | 创建时间 | |
活动订单关联表(activity_order)
| 标签 | 含义 | |
|---|---|---|
| id | 编号 | |
| activity_id | 活动id | |
| order_id | 订单编号 | |
| create_time | 发生日期 | |
优惠规则表(activity_rule)
| 标签 | 含义 | |
|---|---|---|
| id | 编号 | |
| activity_id | 活动id | |
| condition_amount | 满减金额 | |
| condition_num | 满减件数 | |
| benefit_amount | 优惠金额 | |
| benefit_discount | 优惠折扣 | |
| benefit_level | 优惠级别 | |
编码字典表(base_dic)
| 标签 | 含义 | |
|---|---|---|
| dic_code | 编号 | |
| dic_name | 编码名称 | |
| parent_code | 父编号 | |
| create_time | 创建日期 | |
| operate_time | 修改日期 | |
参与活动商品表(activity_sku)(暂不导入)
| 标签 | 含义 |
|---|---|
| id | 编号 |
| activity_id | 活动id |
| sku_id | sku_id |
| create_time | 创建时间 |
如何捋顺表逻辑
1.先按照对象区分表
比如,将商品相关对象的表放在一块,订单相关的表放在一块,用户相关的表放在一块。
2.按照业务开始捋对象表之间的关系(此时需要主外键连接)
按照业务流程来分析表间逻辑关系,比如用户购买商品这一业务逻辑,数据在表与表之间是如何流转的,分析它的流程来捋清表间关系
补:主表和从表区分
两张表通过主外键关联,主键所在的表叫做主表,外键所在表叫从表。
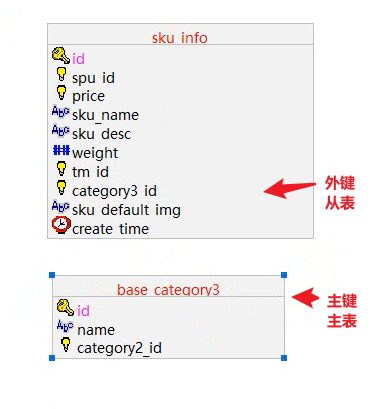
建立业务表
通过数据库软件连接集群节点上的mysql,建立电商业务表,建表sql在上面分享的资料里的数据生成脚本,业务数据里有,直接运行建表即可。
生成业务数据
1.在hadoop102的/opt/module/目录下创建db_log文件夹
1 | [atguigu@hadoop102 module]$ mkdir db_log/ |
2.把gmall2020-mock-db-2020-04-01.jar和application.properties上传到hadoop102的/opt/module/db_log路径上。
3.根据需求修改application.properties相关配置
1 | logging.level.root=info |
4.并在该目录下执行,如下命令,生成2020-06-14日期数据:
1 | [atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2020-04-01.jar |
5.在配置文件application.properties中修改
1 | mock.date=2020-06-15 |
6.再次执行命令,生成2020-06-15日期数据:
1 | [atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2020-04-01.jar |
业务建模
通过EZDML这款数据库设计工具来捋清楚表与表间的复杂业务关系。
关于使用,可自行百度。





