
数据仓库从0到1之数仓DWD层
数据仓库从0到1之数仓DWD层
从ODS层的数据到DWD层要经过ETL处理,所以在DWD层,主要对数据进行ETL处理和事实表以及维度表的建表。
对用户行为数据解析。
对核心数据进行判空过滤。
对业务数据采用维度模型重新建模。
DWD层用户日志行为解析
日志格式回顾
页面埋点日志
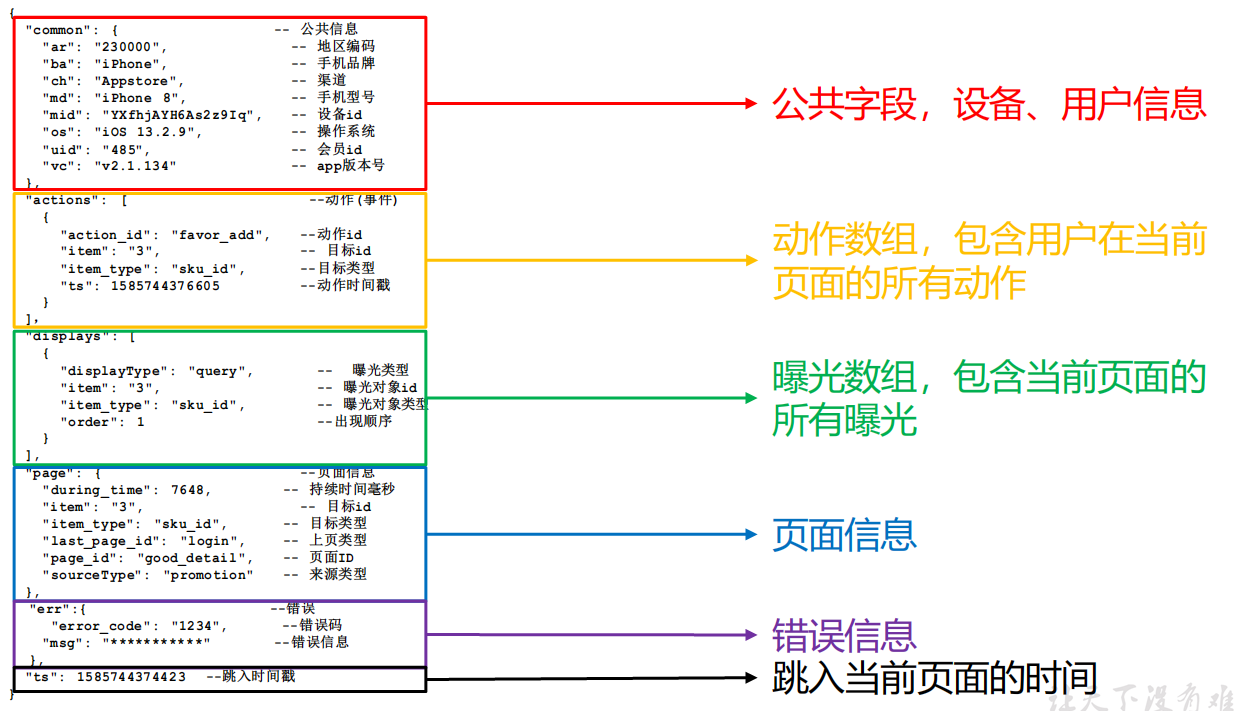
启动日志
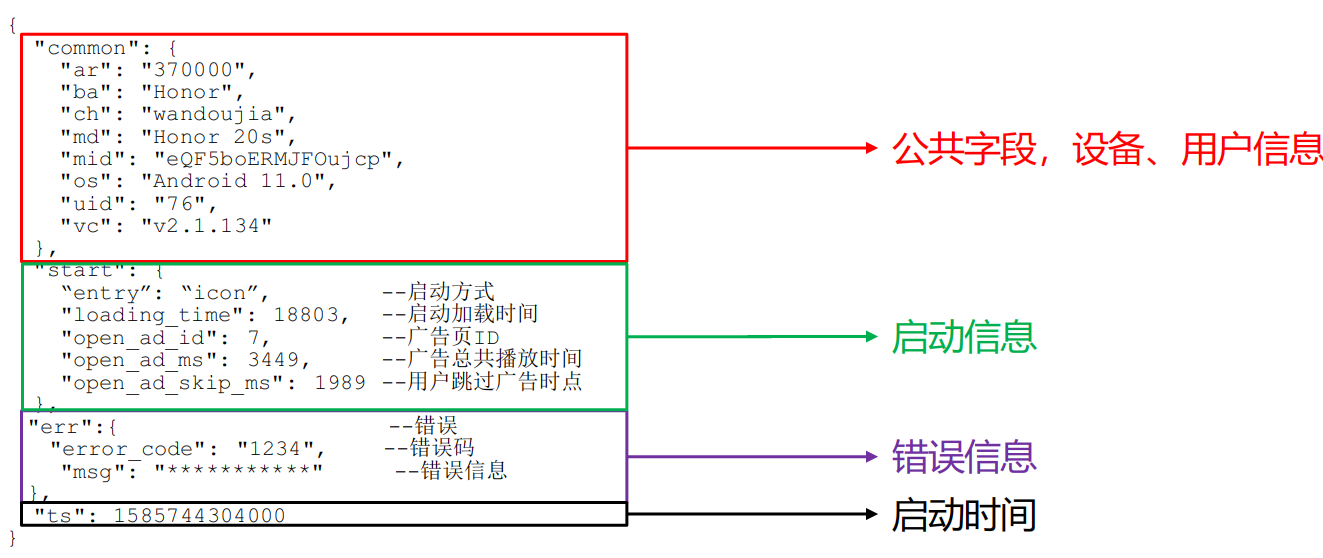
启动日志表
启动日志解析思路:启动日志表中每行数据对应一个启动记录,一个启动记录应该包含日志中的公共信息和启动信息。先将所有包含start字段的日志过滤出来,然后使用get_json_object函数解析每个字段。
get_json_object函数解析:
数据:
[{“name”:”大郎”,”sex”:”男”,”age”:”25”},{“name”:”西门庆”,”sex”:”男”,”age”:”47”}]
取出第一个json对象:
select get_json_object(‘[{“name”:”大郎”,”sex”:”男”,”age”:”25”},{“name”:”西门庆”,”sex”:”男”,”age”:”47”}]’,’$[0]’);
结果是:{“name”:”大郎”,”sex”:”男”,”age”:”25”}
取出第一个json的age字段的值:
SELECT get_json_object(‘[{“name”:”大郎”,”sex”:”男”,”age”:”25”},{“name”:”西门庆”,”sex”:”男”,”age”:”47”}]’,”$[0].age”);
结果是:25
这里查询ods_log的日志数据:
1 | select * from ods_log where dt='2020-06-15' limit 1; |
1 | <--! 这里注意,不同用户的json日志格式字段不一样,只有当用户浏览了page才有page字段,启动报错才会有error字段 --> |
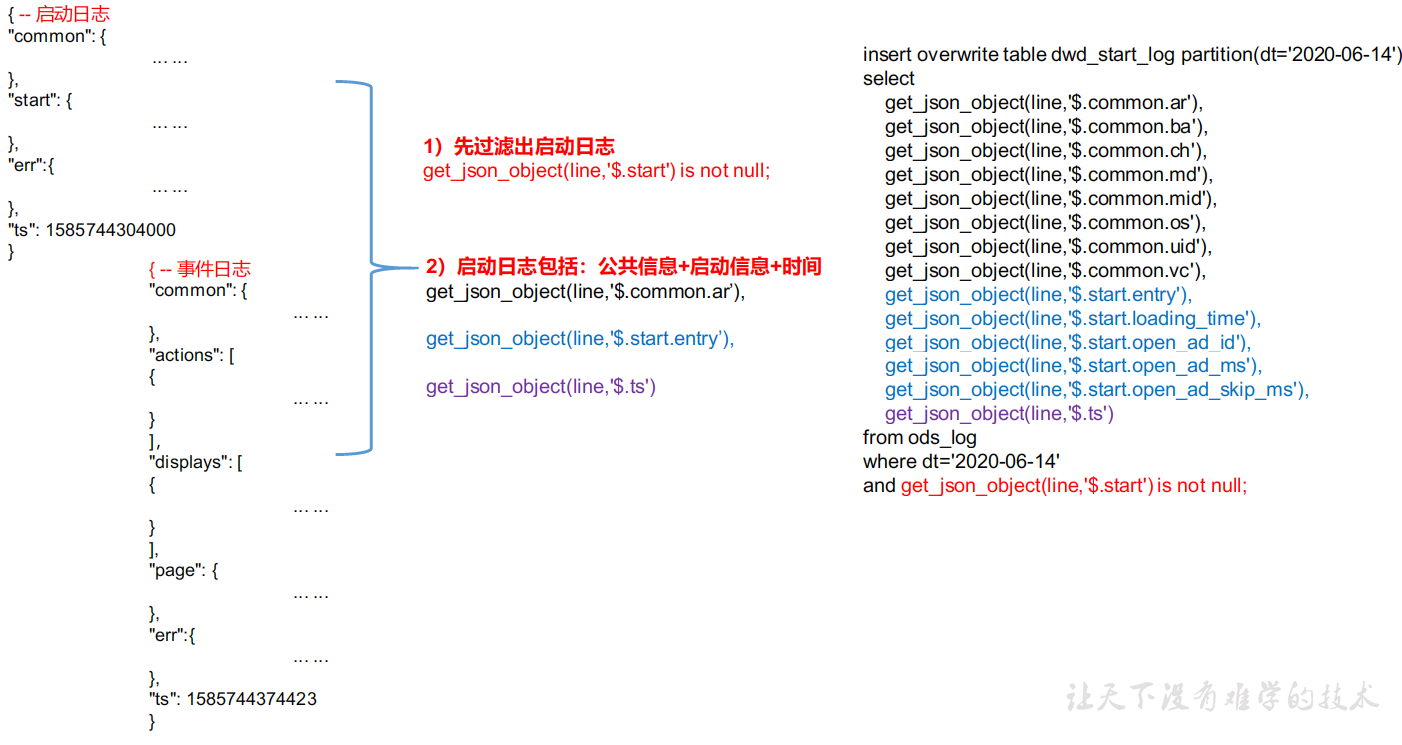
启动日志表建表语句:
1 | drop table if exists dwd_start_log; |
说明:数据采用parquet存储方式,是可以支持切片的,不需要再对数据创建索引。如果单纯的text方式存储数据,需要采用支持切片的,lzop压缩方式并创建索引。
关于Hive读取索引文件问题
两种方式,分别查询数据有多少行:
1 | hive (gmall)> select * from ods_log; |
两次查询结果不一致。
原因是select * from ods_log不执行MR操作,默认采用的是ods_log建表语句中指定的DeprecatedLzoTextInputFormat,能够识别lzo.index为索引文件。
select count(*) from ods_log执行MR操作,默认采用的是CombineHiveInputFormat,不能识别lzo.index为索引文件,将索引文件当做普通文件处理。更严重的是,这会导致LZO文件无法切片。
1 | hive (gmall)> set hive.input.format; |
解决办法:修改CombineHiveInputFormat为HiveInputFormat
再次测试
1 | hive (gmall)> |
页面日志表
页面日志解析思路:页面日志表中每行数据对应一个页面访问记录,一个页面访问记录应该包含日志中的公共信息和页面信息。先将所有包含page字段的日志过滤出来,然后使用get_json_object函数解析每个字段。

1 | drop table if exists dwd_page_log; |
动作日志表
动作日志解析思路:动作日志表中每行数据对应用户的一个动作记录,一个动作记录应当包含公共信息、页面信息以及动作信息。先将包含action字段的日志过滤出来,然后通过UDTF函数,将action数组“炸开”(类似于explode函数的效果),然后使用get_json_object函数解析每个字段。

建表语句
1 | drop table if exists dwd_action_log; |
UDTF函数定义思路:

补充:hive虚表
常与explode等udtf函数一起使用,将拆分出来的字段与原始表字段进行笛卡尔积得到一张虚表。
1 | create database test; |
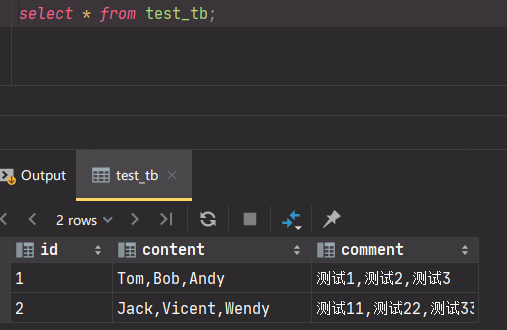
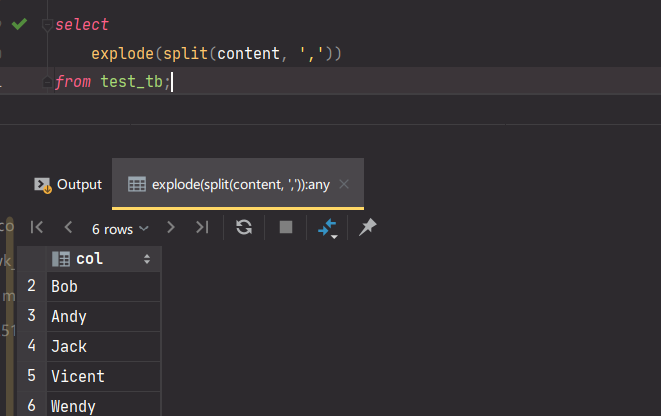
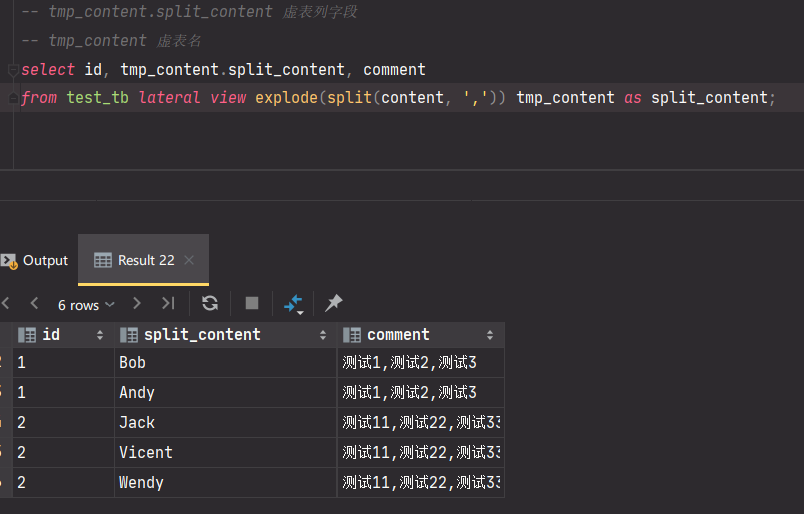
所以,我们需要把actions里面的元素也给拆分出来,使用虚表的形式拆分出用户多行action记录,
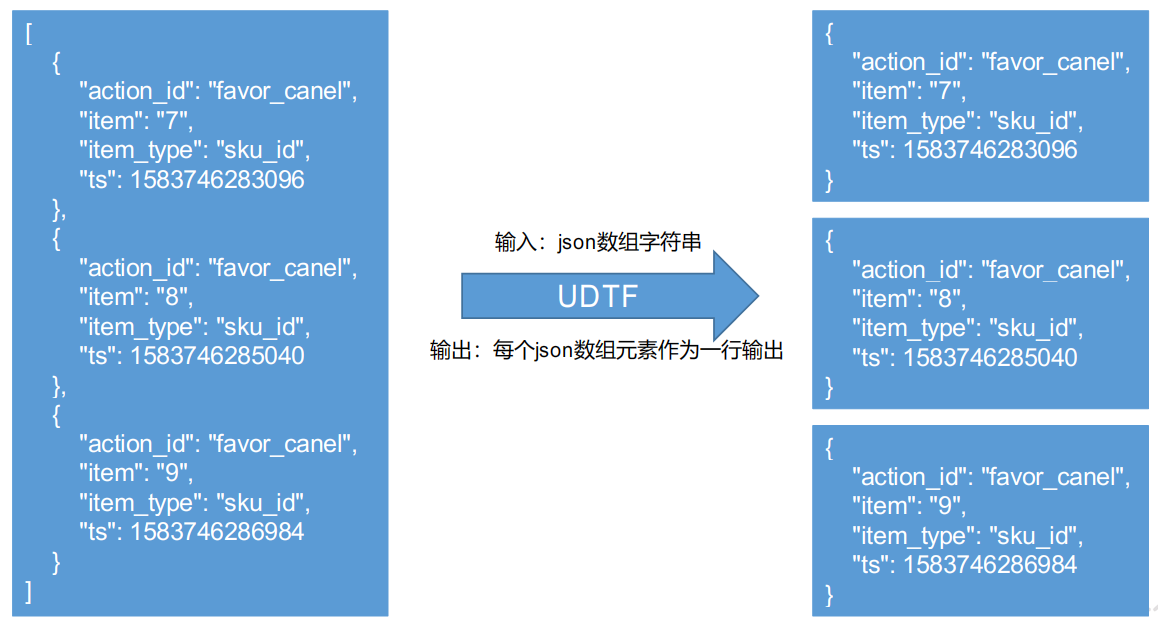
使用java开发一个udtf函数,创建maven工程,添加依赖导包。
1 | <dependencies> |
1 | package com.everweekup.hive.udtf; |
创建函数
1.打包
2.将hivefunction-1.0-SNAPSHOT.jar上传到hadoop102的/opt/module,然后再将该jar包上传到HDFS的/user/hive/jars路径下
1 | [dw@hadoop102 module]$ hadoop fs -mkdir -p /user/hive/jars |
3.创建永久函数与开发好的java class关联
1 | hive (gmall)> |
4.注意:如果修改了自定义函数重新生成jar包怎么处理?只需要替换HDFS路径上的旧jar包,然后重启Hive客户端即可。
曝光日志表
曝光日志解析思路:曝光日志表中每行数据对应一个曝光记录,一个曝光记录应当包含公共信息、页面信息以及曝光信息。先将包含display字段的日志过滤出来,然后通过UDTF函数,将display数组“炸开”(类似于explode函数的效果),然后使用get_json_object函数解析每个字段。

1 | drop table if exists dwd_display_log; |
错误日志表
错误日志解析思路:错误日志表中每行数据对应一个错误记录,为方便定位错误,一个错误记录应当包含与之对应的公共信息、页面信息、曝光信息、动作信息、启动信息以及错误信息。先将包含err字段的日志过滤出来,然后使用get_json_object函数解析所有字段。

1 | drop table if exists dwd_error_log; |
说明:此处为对动作数组和曝光数组做处理,如需分析错误与单个动作或曝光的关联,可先使用explode_json_array**函数将数组“炸开”,再使用get_json_object**函数获取具体字段。
1 | -- 测试将display和actions爆开 |
DWD层用户行为数据加载脚本
编写DWD数据导入脚本ods_to_dwd_log:
1 |
|
脚本采用的是insert overwrite插入数据,可以保证程序的幂等性。一般企业在每日凌晨30mins~1点执行。
执行脚本:
1 | [dw@hadoop116 ~]$ ods_to_dwd_log.sh 2020-06-15 |
DWD层业务数据
业务数据方面DWD层的搭建主要注意点在于维度建模,减少后续大量Join操作。
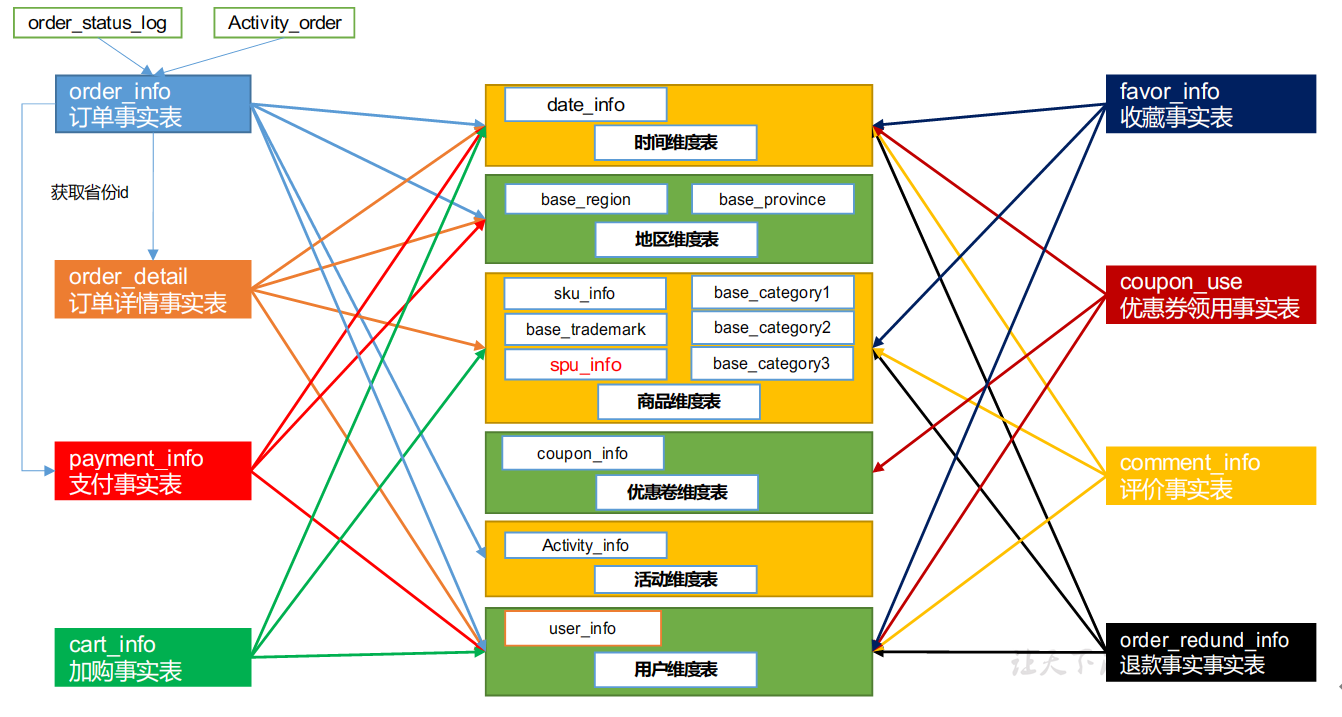
商品维度表(全量)
商品维度表主要是将商品表SKU表、商品一级分类、商品二级分类、商品三级分类、商品品牌表和商品SPU表联接为商品表。
建表语句:
1 | DROP TABLE IF EXISTS `dwd_dim_sku_info`; |
数据导入语句
1 | --= with优化查询 |
优惠券维度表(全量)
把ODS层ods_coupon_info表数据导入到DWD层优惠卷维度表,在导入过程中可以做适当的清洗。
建表语句:
1 | drop table if exists dwd_dim_coupon_info; |
数据装载:
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
活动维度表(全量)
这里要注意,活动维度表由于是自己造的,没有列出参与活动对应的活动级别,活动级别有1,2,3级别,而活动订单表只有活动类型没有参与活动的级别,所以这里直接拿活动订单表,不考虑join其他表。
1 | drop table if exists dwd_dim_activity_info; |
数据装载:
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
地区维度表(特殊)
1 | DROP TABLE IF EXISTS `dwd_dim_base_province`; |
数据装载:
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
时间维度表(特殊)
1 | DROP TABLE IF EXISTS `dwd_dim_date_info`; |
数据装载:
注意:由于dwd_dim_date_info是列式存储+LZO压缩。直接将date_info.txt文件导入到目标表,并不会直接转换为列式存储+LZO压缩。我们需要创建一张普通的临时表dwd_dim_date_info_tmp,将date_info.txt加载到该临时表中。最后通过查询临时表数据,把查询到的数据插入到最终的目标表中。
创建临时表,非列式存储:
1 | DROP TABLE IF EXISTS `dwd_dim_date_info_tmp`; |
支付事实表(事务型事实表)
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 支付 | √ | √ | √ | 金额 |
建表语句:
1 | drop table if exists dwd_fact_payment_info; |
这里的时间维度就是分区字段,这里补充下维度退化概念:由于维度表字段过少,可以将维度表并入到事实表以减少join,提高性能,这一操作就维度退化。
数据装载:
1 | --= 一行记录就是一条事务,增量更新 |
退款事实表(事务型事实表)
把ODS层ods_order_refund_info表数据导入到DWD层退款事实表,在导入过程中可以做适当的清洗。
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 退款 | √ | √ | √ | 件数/金额 |
建表语句
1 | drop table if exists dwd_fact_order_refund_info; |
数据装载:
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
评价事实表(事务型事实表)
把ODS层ods_comment_info表数据导入到DWD层评价事实表,在导入过程中可以做适当的清洗。
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 评价 | √ | √ | √ | 个数 |
建表语句
1 | drop table if exists dwd_fact_comment_info; |
数据装载
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
订单明细事实表(事务型事实表)
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 订单详情 | √ | √ | √ | √ | 件数/金额 |
建表语句:
1 | drop table if exists dwd_fact_order_detail; |
数据装载:
1 | --= 一个order_info里面有多个order_detail订单,即将读个订单合并成一个大订单放在order_info中,order_detail展现大订单里的详情订单 |
对上面的sql语句进行补充说明:
1 | 补充:订单明细事实表中的分摊优惠处理,由于除了之后会存在精度损失,所以我们考虑用总的费用减去除后各商品分摊的优惠。计算除损失的精度后找一个商品加上这个损失,使得整体结果只和等于原来的总费用。 |
加购事实表(周期型快照事实表,每日快照)
由于购物车的数量是会发生变化,所以导增量不合适。
每天做一次快照,导入的数据是全量,区别于事务型事实表是每天导入新增。
周期型快照事实表劣势:存储的数据量会比较大。
解决方案:周期型快照事实表存储的数据比较讲究时效性,时间太久了的意义不大,可以删除以前的数据。
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 加购 | √ | √ | √ | 件数/金额 |
建表语句
1 | drop table if exists dwd_fact_cart_info; |
数据装载
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
收藏事实表(周期型快照事实表,每日快照)
收藏的标记,是否取消,会发生变化,做增量不合适。
每天做一次快照,导入的数据是全量,区别于事务型事实表是每天导入新增。
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 收藏 | √ | √ | √ | 个数 |
建表语句:
1 | drop table if exists dwd_fact_favor_info; |
数据装载:
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
优惠券领用事实表(累积型快照事实表)
适用周期性的事务。领用=》使用=》过期,一行数据指代用户对优惠劵的领取使用记录
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 优惠券领用 | √ | √ | √ | 个数 |
优惠卷的生命周期:领取优惠卷-》用优惠卷下单-》优惠卷参与支付
累积型快照事实表使用:统计优惠卷领取次数、优惠卷下单次数、优惠卷参与支付次数。
累计型快照事实表需要将表进行分区,因为会有新增和修改的数据需要和原始数据对比更新,分区后只需要去到需要修改的数据所在的分区进行修改,能有效避免全量数据增删改查带来的性能损耗问题。
根据我们在数仓ODS层建模一文中的coupon_use表字段,get_time、using_time和used_time分别代表获得日期、使用日期和使用截至日期。根据这几个字段去join原表的不同分区更新数据。
要更新的字段主要是优惠卷的使用状态和使用时间。
建表语句:
1 | drop table if exists dwd_fact_coupon_use; |
注意:dt是按照优惠卷领用时间get_time做为分区。
导入数据
1 | -- 优惠券领用事实表(累积型快照事实表) |
订单事实表(累积型快照事实表)
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 订单 | √ | √ | √ | √ | 件数/金额 |
订单生命周期:创建时间=》支付时间=》取消时间=》完成时间=》退款时间=》退款完成时间。
由于ODS层订单表只有创建时间和操作时间两个状态,不能表达所有时间含义,所以需要关联订单状态表。订单事实表里面增加了活动id,所以需要关联活动订单表。
建表语句:
1 | drop table if exists dwd_fact_order_info; |
数据装载:
1 | with old as ( |
用户维度表(拉链表)
用户表中的数据每日既有可能新增,也有可能修改,但修改频率并不高,属于缓慢变化维度,此处采用拉链表存储用户维度数据。拉链表可以解决数据重复存储。
关于拉链表的介绍可以在数仓建模理论一文中查看。
拉链表制作过程
初始化拉链表(首次独立执行)
建立拉链表:
1 | drop table if exists dwd_dim_user_info_his; |
初始化拉链表:
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
制作当日变动数据(包括新增,修改)每日执行
如何获得每日变动表:
最好表内有创建时间和变动时间(Lucky!)
如果没有,可以利用第三方工具监控比如canal,监控MySQL的实时变化进行记录(麻烦)。主从复制,缓解数据库压力。读数据更多,所以读写分离,使用主从分离去做,slave节点会从master节点拉取数据,读从slave读,多个slave能够缓解读的压力。
写数据直接写master,保证数据的一致性。
canal底层原理就是伪装成mysql的一个slave,这样canal就能获取到mysql的变动数据然后传给kafka再传入数据库进行对比。
逐行对比前后两天的数据,检查md5(concat(全部有可能变化的字段))是否相同(low)
要求业务数据库提供变动流水(人品,颜值)
靠谱的方法:a,b
因为ods_user_info本身导入过来就是新增变动明细的表,所以不用处理:
- 数据库中新增2020-06-15一天的数据
* 通过Sqoop把2020-06-15日所有数据导入
1 | mysql_to_hdfs.sh all 2020-06-15 |
- ods层数据导入
1 | hdfs_to_ods_db.sh all 2020-06-15 |
先合并变动信息,再追加新增信息,插入到临时表中
建立临时表:
1 | drop table if exists dwd_dim_user_info_his_tmp; |
导入脚本:
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
临时表覆盖给拉链表:
1 | insert overwrite table dwd_dim_user_info_his |
DWD层业务数据导入脚本
1 | #!/bin/bash |
数据导入
分别运行业务数据和日志数据导入脚本,导入数据到DWD层。
1 | [dw@hadoop116 bin]$ ods_dwd_db2.sh all 2020-06-15 |





