数据仓库从0到1之数仓ODS层建模
数据仓库从0到1之数仓ODS层建模
ODS层用户日志数据和电商业务数据模拟生成导入
ODS层用户日志数据生成及导入
在前面的数仓业务逻辑流程分析一文中,我们分析了电商数仓的数据来源有两种,一种是用户日志数据json格式信息,一种是存储在mysql中的业务数据表,因此在这里我们要模拟生成这两种类型的数据。
用户日志数据生成
这里我们使用数仓业务逻辑流程分析一文中提到的脚本工具来生成数据。
先进入用户日志数据产生脚本所在的目录:
1 | [dw@hadoop117 applog]$ pwd |
再编写一个脚本用于启动节点上负责产生日志数据的机器的日志生成进程:
1 | [dw@hadoop116 applog]$ cat /home/dw/bin/log.sh |
我这里拿了两台节点用于日志数据的生成,这并不是硬性要求,可以根据自己物理机配置选择。
这里我们运行脚本,在两台节点上,生成业务时间为2020-06-15的日志数据:
1 | [dw@hadoop116 applog]$ log.sh |
可以看到我们的日志数据生成了,要注意日志数据名称中的日期是根据当前机器的时间生成的,而用户日志的数据日期则需要到application.properties脚本里去配置。
用户日志数据采集
这里我们使用在日志采集平台搭建一文中编写的日志数据采集脚本,来对生成的日志数据进行采集:
1 | [dw@hadoop116 log]$ log-cluster.sh start |
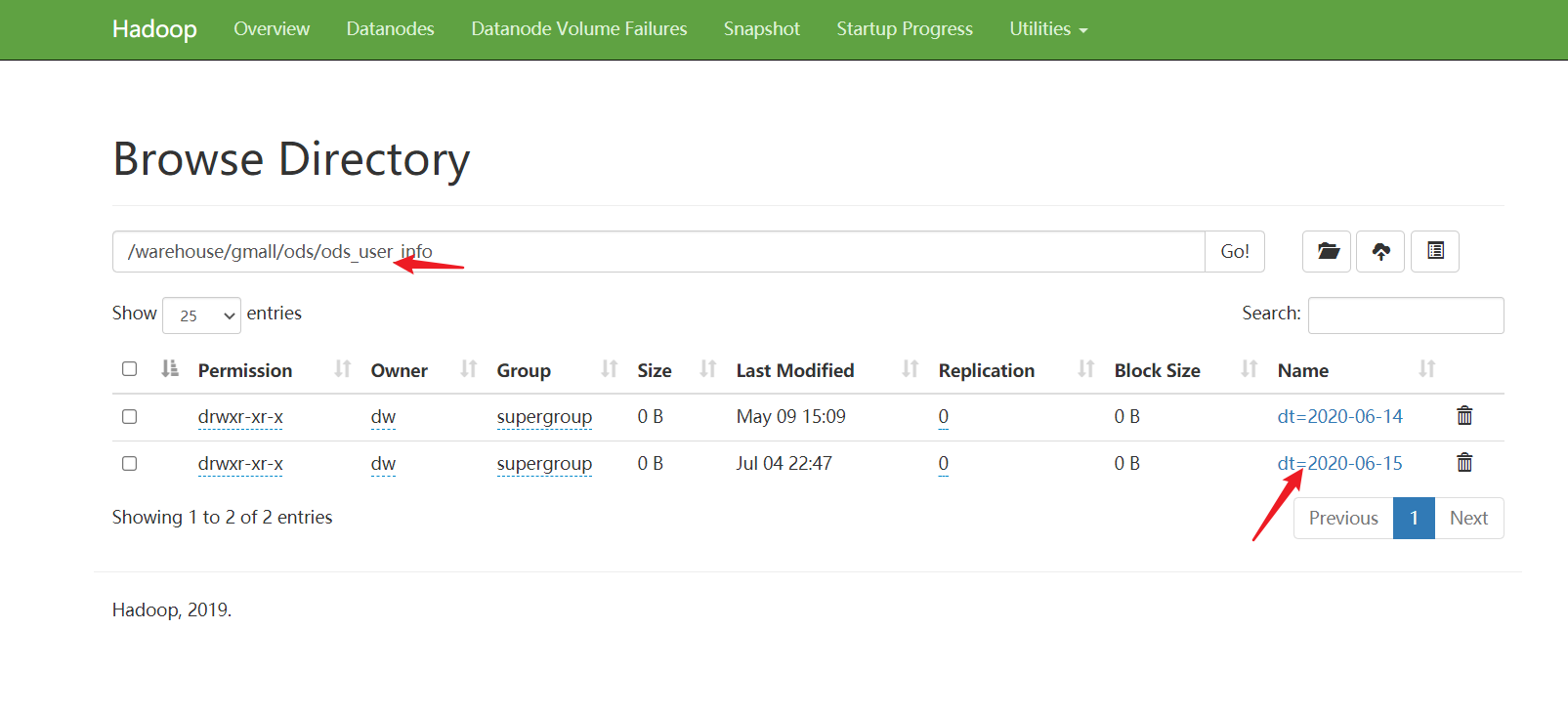
之后,我们登陆到HDFS的web界面,查看对应路径下是否有数据产生:
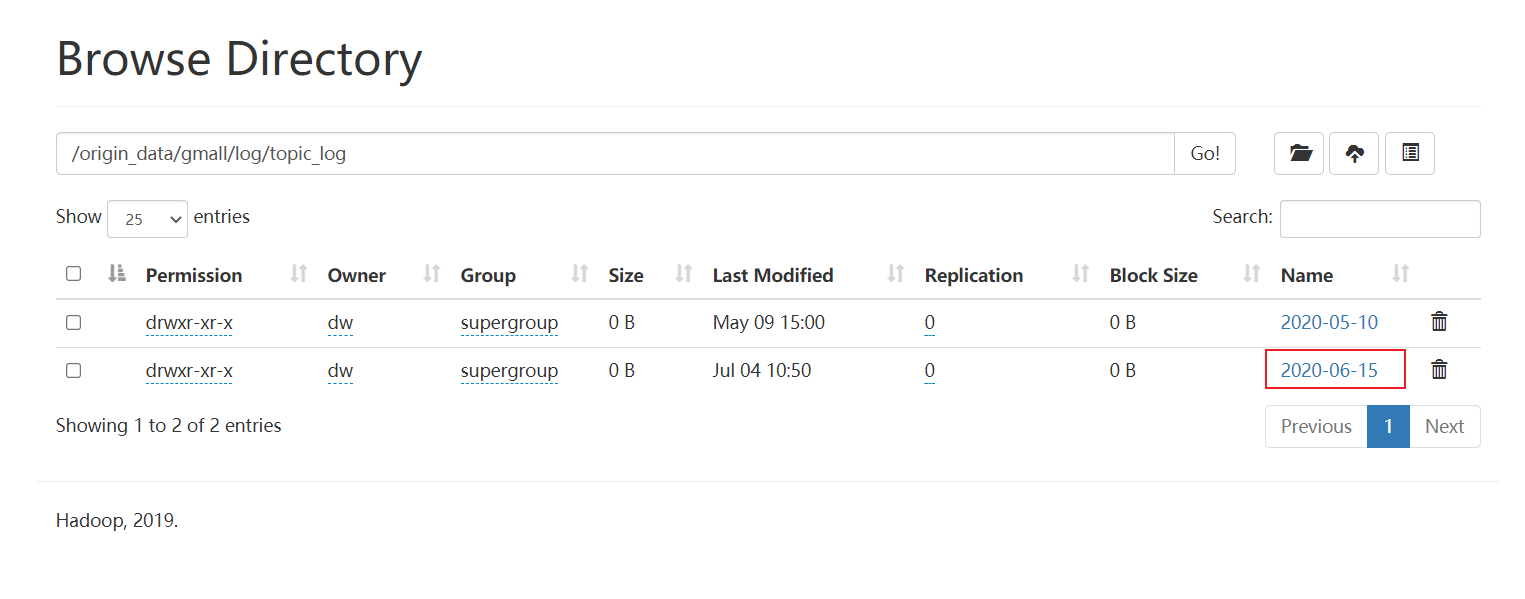
至此,用户日志数据采集完成。
ODS层mysql业务数据生成及导入
ODS层业务数据生成及导入
业务数据生成
这里我们使用数仓业务逻辑流程分析一文中提到的脚本工具来生成mysql业务数据。
进入到脚本路径下,修改popertities文件里的业务数据生成时间:
1 | [dw@hadoop116 db_log]$ ls |
使得mock.date=2020-06-15。
这里写一个脚本用于生成业务数据到mysql,并执行:
1 | [dw@hadoop116 db_log]$ |
连接mysql所在的节点,查看数据是否生成:
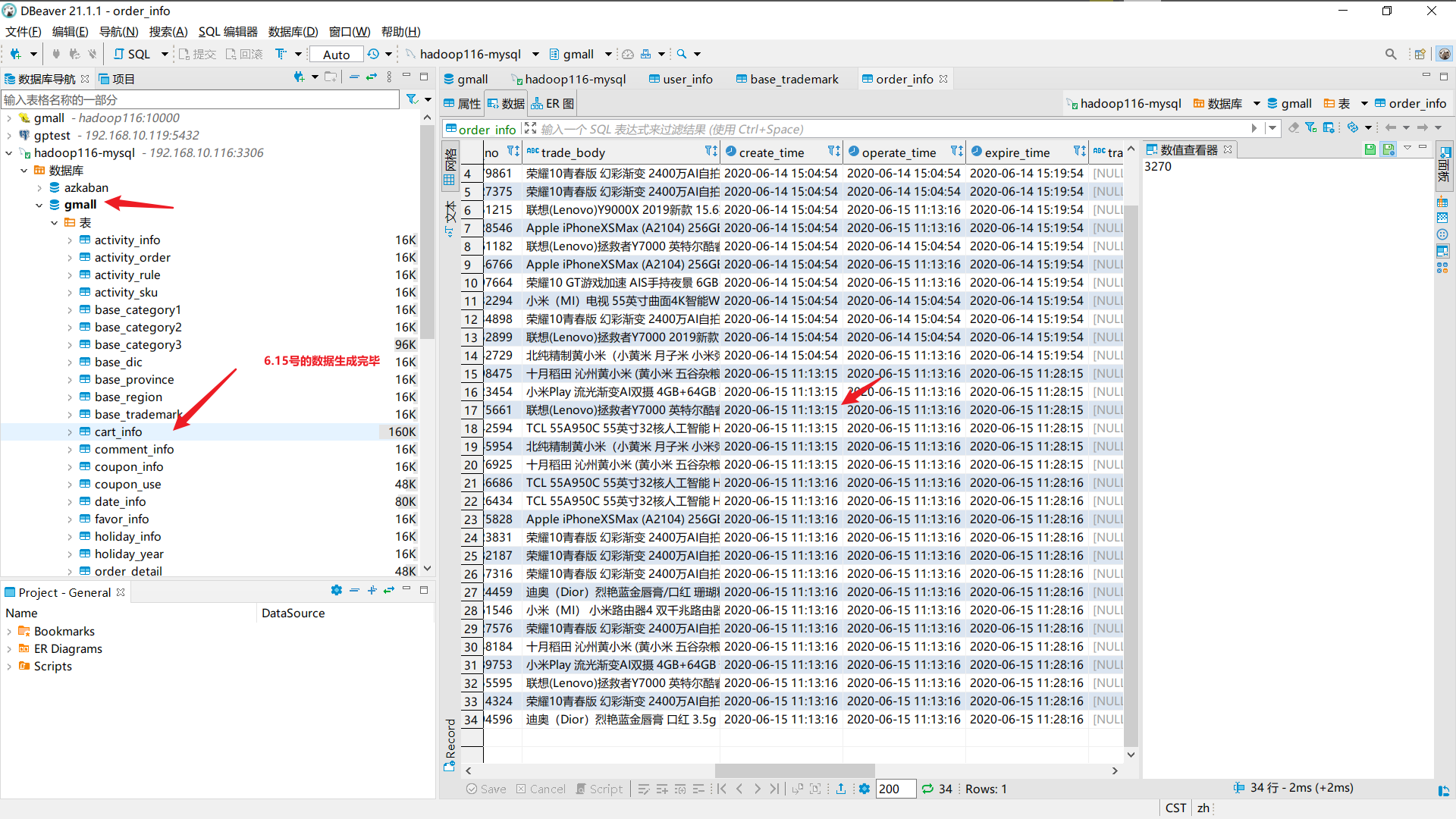
业务数据导入HDFS
将数据从mysql导入到hdfs上,需要用到数据迁移的工具,这里我们使用Sqoop。
Sqoop安装
不借助于工具实现从MySQL读数据(JDBC),HDFS的IO操作,我们也可以通过自己写java程序实现数据导入MySQL,但这样过于麻烦,开发成本较高,于是,sqoop、datax等工具被实现出来。
Sqoop能够实现关系型数据库和Hadoop生态之间数据的双向传输。即MySQLóHDFS数据双向传输。
将MySQL数据传输到HDFS时,Sqoop会提交一个任务,调用MapReduce,不过只执行Map,主要是因为Sqoop是为了传输数据,不是为了分析,只需要一读一写,不需要计算分析,也就不需要reduce。其次是因为shuffle消耗时间和性能。Sqoop自定义了inputformat(能从mysql、oracle读数据的)和outputformat。
Sqoop有两个版本,一个1.x,一个2.x,两者版本不兼容,相当于两个并行的分支版本。
Sqoop2.x目前的功能还不齐全,还不用于生产环境的部署。
下载并解压
1.下载地址:http://mirrors.hust.edu.cn/apache/sqoop/1.4.6/
2.上传安装包sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz到hadoop102的/opt/software路径中
3.解压sqoop安装包到指定目录,如:
1 | [atguigu@hadoop102 software]$ tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/ |
4.解压sqoop安装包到指定目录,如:
1 | [atguigu@hadoop102 module]$ mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop |
修改配置文件
1.进入到/opt/module/sqoop/conf目录,重命名配置文件
1 | [atguigu@hadoop102 conf]$ mv sqoop-env-template.sh sqoop-env.sh |
2.修改配置文件
1 | [atguigu@hadoop102 conf]$ vim sqoop-env.sh |
增加如下内容:
1 | # # 这两个变量在hadoop1.x是分开的,2.x之后放在了一个目录 |
拷贝JDBC驱动
1.将mysql-connector-java-5.1.48.jar 上传到/opt/software路径
2.进入到/opt/software/路径,拷贝jdbc驱动到sqoop的lib目录下。
1 | [atguigu@hadoop102 software]$ cp mysql-connector-java-5.1.48.jar /opt/module/sqoop/lib/ |
验证Sqoop
我们可以通过某一个command来验证sqoop配置是否正确:
1 | [atguigu@hadoop102 sqoop]$ bin/sqoop help |
出现一些Warning警告(警告信息已省略),并伴随着帮助命令的输出:
1 | Available commands: |
测试Sqoop是否能够成功连接数据库
1 | [atguigu@hadoop102 sqoop]$ bin/sqoop list-databases --connect jdbc:mysql://hadoop102:3306/ --username root --password 000000 |
出现如下输出:
1 | information_schema |
Sqoop数据导入脚本
1 | 说明1: |
1 | 说明2: |
补充:
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。
在导出数据时采用—input-null-string和—input-null-non-string两个参数。
导入数据时采用—null-string和—null-non-string。
1 | # sqoop导入mysql数据脚本(如果要执行得去掉注释) |
1 | # sqoop可直接写sql语句 称为free-query |
下面编写业务数据导入HDFS的sqoop脚本,脚本的一些内容涉及到数据同步策略,将会在下面展开描述,这里先放脚本。
1 |
|
说明:脚本没有很好的运用MR的并发能力,因为执行的每行import命令并没有依赖关系,所以我们可以将脚本分为多个,一个脚本里写三个或多个import命令,Azkaban可以识别多个脚本的依赖关系来运行脚本。
导入数据后如果发现有lzo文件,但是没有索引,说明lzo压缩文件是空的,空的就没必要建立索引,这时查看下是否是日期设置错了,过滤不到要求的日期。
对脚本进行优化,将相同对象的表放在一起脚本里,将原来一个脚本分为6个并发执行,提高了MR的效率。
1 | [dw@hadoop116 mysql_to_hdfs]$ ls |
最后在对应路径下查看数据结果:
1 | [dw@hadoop116 mysql_to_hdfs]$ hadoop fs -ls /origin_data/gmall/db/activity_info |
数据同步策略
Mysql的数据每天都会新增或修改发生变化,对应着数仓的数据也应该同步发生变化才能保证分析结果的准确性,因此需要考虑怎样的同步策略能够保证MySQL数据和数仓数据能够同步变化。
目前业务数据都存放在mysl中,既然数据都在mysql中,mysql也支持sql查询,那为啥不写sql进行数据查询?因为:
大数据量的分析会影响业务系统;
MySQL中没有历史数据(所以会把每天MySQL的数据导入到Hive当中,导入到HDFS里,后面分析直接走大数据集群,不会影响业务系统);
Sqoop的import和export
Import支持将mysql表导入到hive表里或hbase表里或者hdfs的一个路径。
Export只支持将HDFS下的一个路径文件导入到mysql的一张表里。
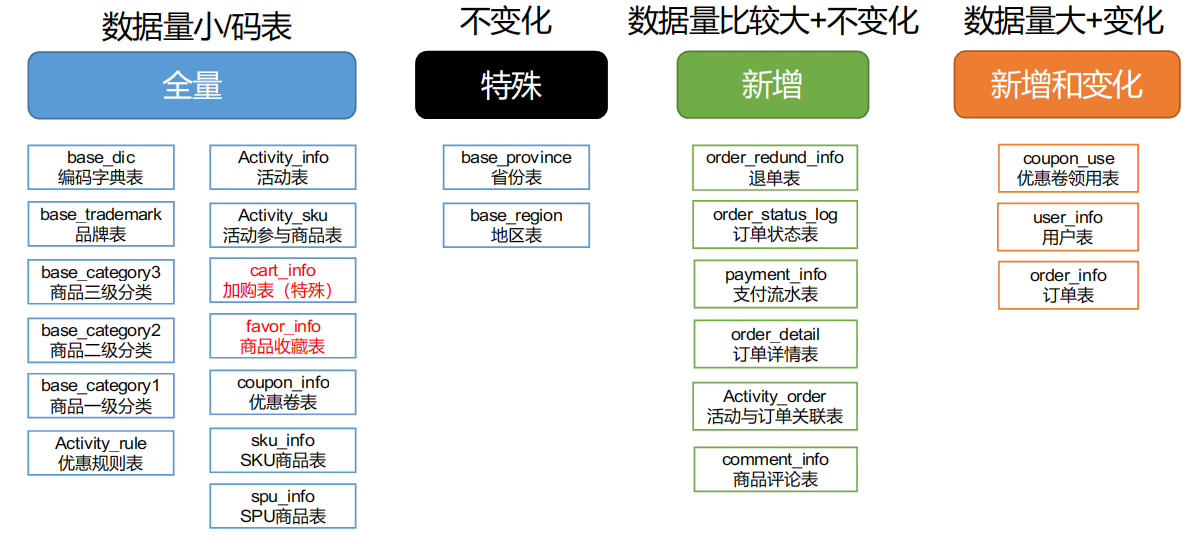
数据同步策略的类型包括:全量同步、增量同步、新增及变化同步、特殊情况
- 全量表:存储完整的数据。(全量同步适用于即会发生新增又会发生变化的表,比如说用户表,将mysql的全表数据导一份,放到数仓当中。全量表也是分区表,一天一分区,存放的是当天从mysql导入进来的全量数据,由于数仓有一个特点需要保留历史数据,但并不是一直保留,一般保留个半年。)
- 增量表:存储新增加的数据。(mysql新增的数据用hive的增量表进行存储,增量表是分区表,按天分区,mysql当天新增数据就导入放在hive中当天的分区中,后面类似。这样的表在Mysql中要求每天只有新增,没有变化的数据,一般流水表就是这种表,比如支付流水表,只会新增不会修改,再比如订单状态表。)
- 新增及变化表:存储新增加的数据和变化的数据。(Mysql数据表很大,每天有新增有变化,如果还是采用每日全量的策略不太好,冗余太大,效率低。这时采用新增及变化同步,每天只把修改的数据和新增的数据拿过来导入数仓,不变的数据不导入。对于这种表,要不就是获取全量最新的数据,要不就是获取历史上某一天的全量数据。对于新增及变化表,就不好获取了,后面数仓部分再进行解释)
- 特殊表:只需要存储一次。
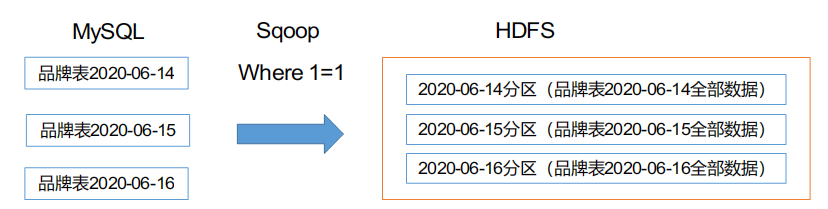
全量同步策略
每日全量,就是每日存储一份完整数据作为一个分区。适用于表数据量不大,且每天既会有新数据插入,也会有旧数据的修改的场景。
例如:编码字典表、品牌表、商品三级分类、商品二级分类、商品一级分类、优惠规则表、活动表、SKU商品表、SPU商品表等。
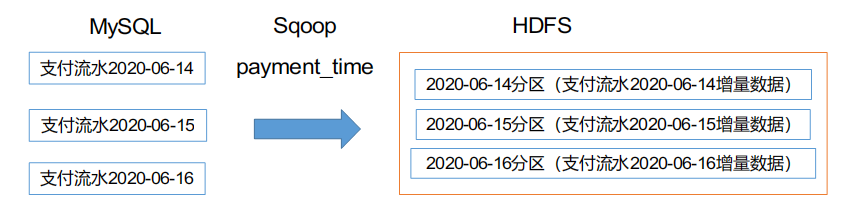
增量同步策略
每日增量,就是每天存储一份增量数据,作为一个分区。适用于表数据量大,且每日按只会有新数据插入的场景。例如:退单表、订单状态表、支付流水表、订单详情表、活动与订单关联表、商品评论表。
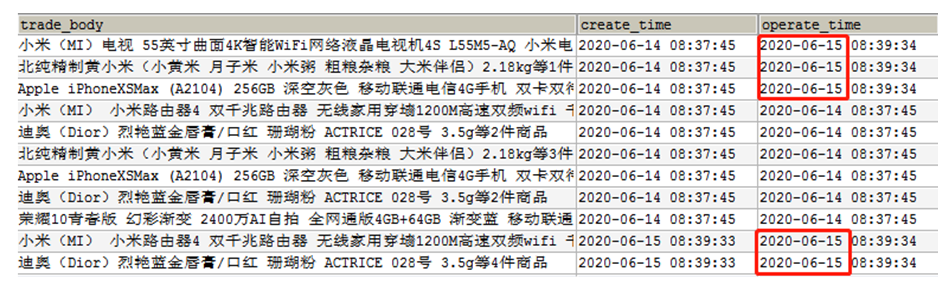
新增及变化策略
每日新增变化,就是存储创建时间和操作时间都是今天的数据,适用于表的数据量大,既会有新增,有会有变化。例如:用户表、订单表、优惠卷领用表。
特殊策略
不管是新增还是全量还是新增及变化策略,都需要每天到mysql导入数据,但有些数据不需要每天都去同步,比如省份、地区数据,只需在数仓保留一份即可。
某些特殊的维度表,可不必遵循上述同步策略。
- 客观世界维度
没变化的客观世界的维度(比如性别,地区,民族,政治成分,鞋子尺码)可以只存一份固定值。
- 日期维度
日期维度可以一次性导入一年或若干年的数据。保留历史数据能够分析数据和时间维度的关系。后期会建立一个时间维度表。日期维度表主键是日期(20200916),字段比如说,是这一年里的第几天,位于一年里第几个季度,今天周几,是否法定节假日等。
数仓搭建-ODS层
- 保持数据原貌不做任何修改,起到备份数据的作用。
- 数据采用LZO压缩,减少磁盘存储空间。100G数据可以压缩到10G以内。
- 创建分区表,防止后续的全表扫描,在企业开发中大量使用分区表。
- 创建外部表。在企业开发中,除了自己用的临时表,创建内部表外,绝大多数场景都是创建外部表。
创建日志表ods_log
ODS层以原始数据为基准,数据怎么样,表就怎么建,由于用户日志是json格式,所以我们只需要建立一张外部表(保护原始数据),一个字段,做好分区。

1 | -- 建表 |
注意:时间格式都配置成YYYY-MM-DD格式,这是Hive默认支持的时间格式
编写日志数据导入脚本:
1 |
|
注意:[ -n 变量值 ]不会解析数据,使用[ -n 变量值 ]时,需要对变量加上双引号(“ “)
给予脚本可执行权限,执行脚本:
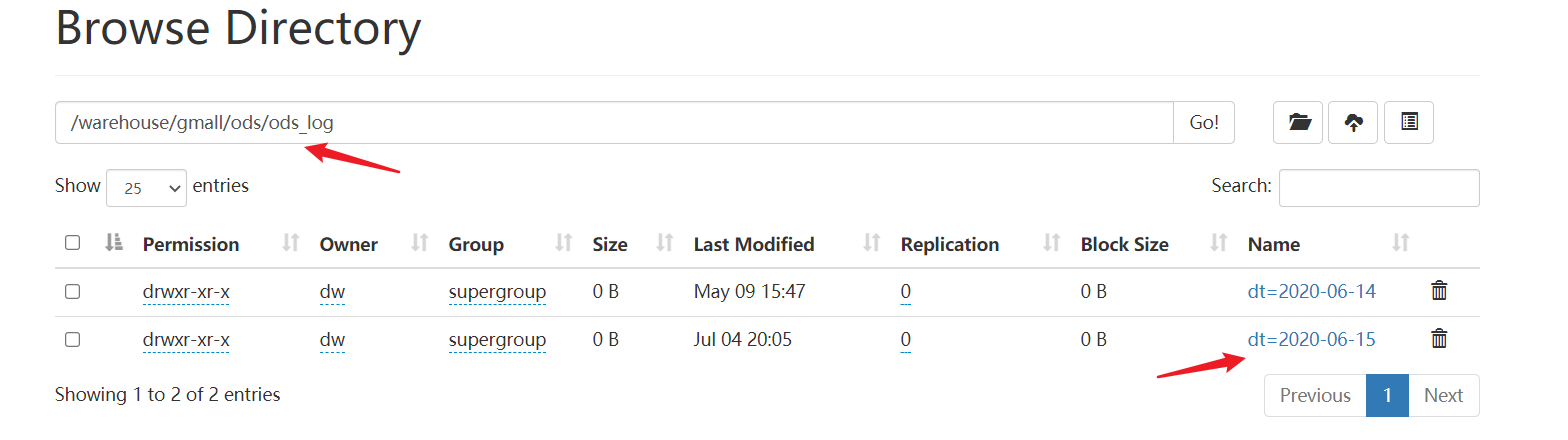
1 | [dw@hadoop116 mysql_to_hdfs]$ hdfs_to_ods_log.sh 2020-06-15 |
这里要注意,执行了数据导入命令后,原来存日志数据的路径下的日志数据会转移到数据仓库下的ODS路径。
补充:Shell中单引号和双引号区别
编写一个sh脚本测试:
1 |
|
执行结果:
1 | [atguigu@hadoop102 bin]$ test.sh 2020-06-14 |
总结:
- 单引号不取变量值
- 双引号取变量值
- 反引号`,执行引号中命令
- 双引号内部嵌套单引号,取出变量值
- 单引号内部嵌套双引号,不取出变量值
ODS层业务数据
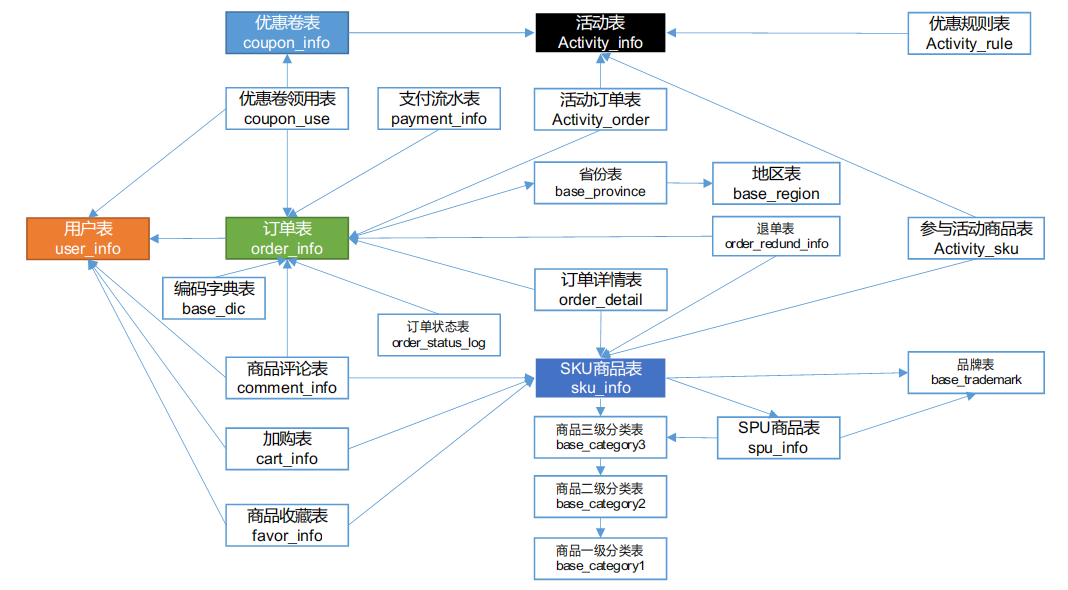
订单表(增量及更新)
建表语句:
1 | drop table if exists ods_order_info; |
订单详情表(增量表)
1 | drop table if exists ods_order_detail; |
SKU商品表(全量表)
1 | drop table if exists ods_sku_info; |
用户表(增量及更新)
1 | drop table if exists ods_user_info; |
商品一级分类表(全量)
1 | drop table if exists ods_base_category1; |
商品二级分类表(全量)
1 | drop table if exists ods_base_category2; |
支付流水表(增量)
1 | drop table if exists ods_payment_info; |
省份表(特殊)
1 | drop table if exists ods_base_province; |
地区表(特殊)
1 | drop table if exists ods_base_region; |
品牌表(全量)
1 | drop table if exists ods_base_trademark; |
订单状态表(增量)
1 | drop table if exists ods_order_status_log; |
SPU商品表(全量)
1 | drop table if exists ods_spu_info; |
商品评论表(增量)
1 | drop table if exists ods_comment_info; |
退单表(增量)
1 | drop table if exists ods_order_refund_info; |
加购表(全量)
1 | drop table if exists ods_cart_info; |
商品收藏表(全量)
1 | drop table if exists ods_favor_info; |
优惠券领用表(新增及变化)
1 | drop table if exists ods_coupon_use; |
优惠券表(全量)
1 | drop table if exists ods_coupon_info; |
活动表(全量)
1 | drop table if exists ods_activity_info; |
活动订单关联表(增量)
1 | drop table if exists ods_activity_order; |
优惠规则表(全量)
1 | drop table if exists ods_activity_rule; |
编码字典表(全量)
1 | drop table if exists ods_base_dic; |
ODS层加载数据脚本
1 |
|
初次导入数据时采用all,将sql2中特殊表的数据导入,往后每次导入传参all即可。
运行脚本导入数据:
1 | [dw@hadoop116 bin]$ hdfs_to_ods_db.sh all 2020-06-15 |
可以看到,数据成功导入。