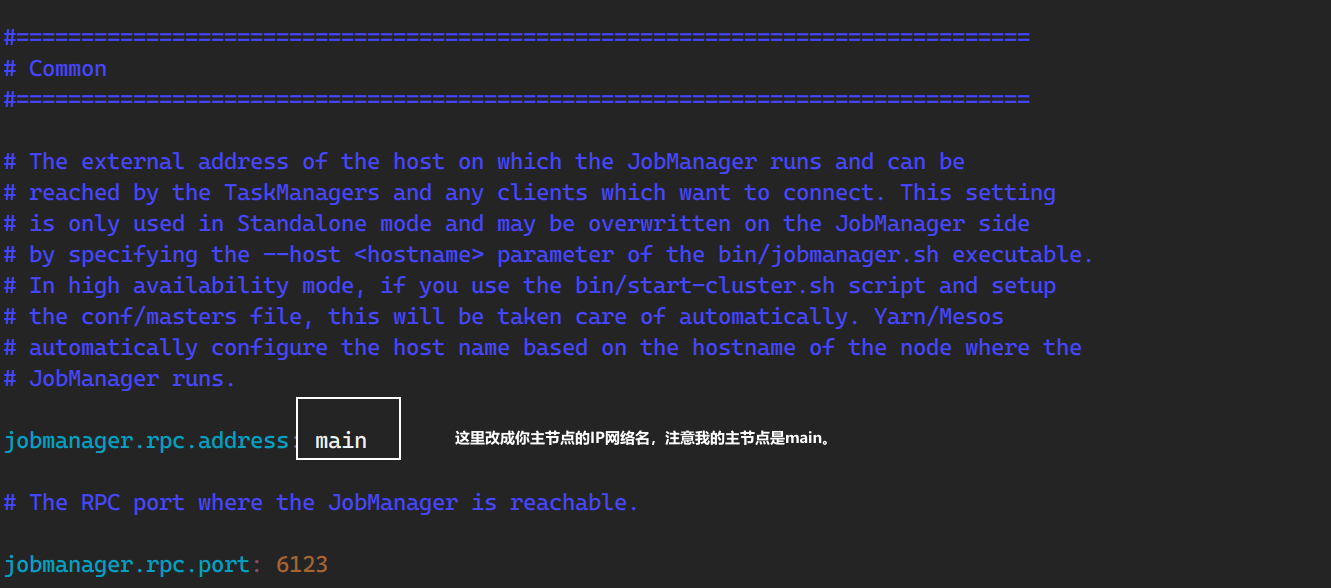
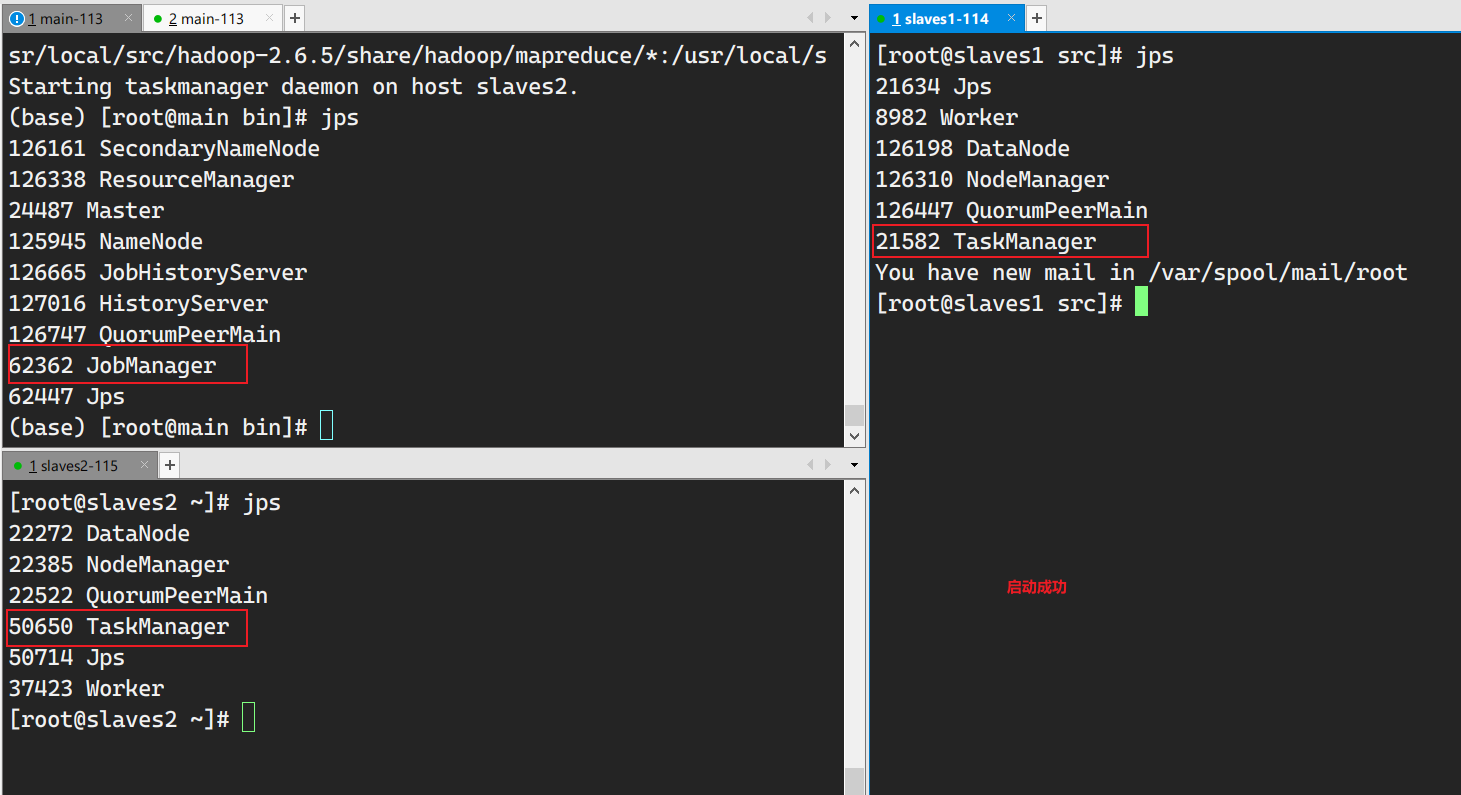
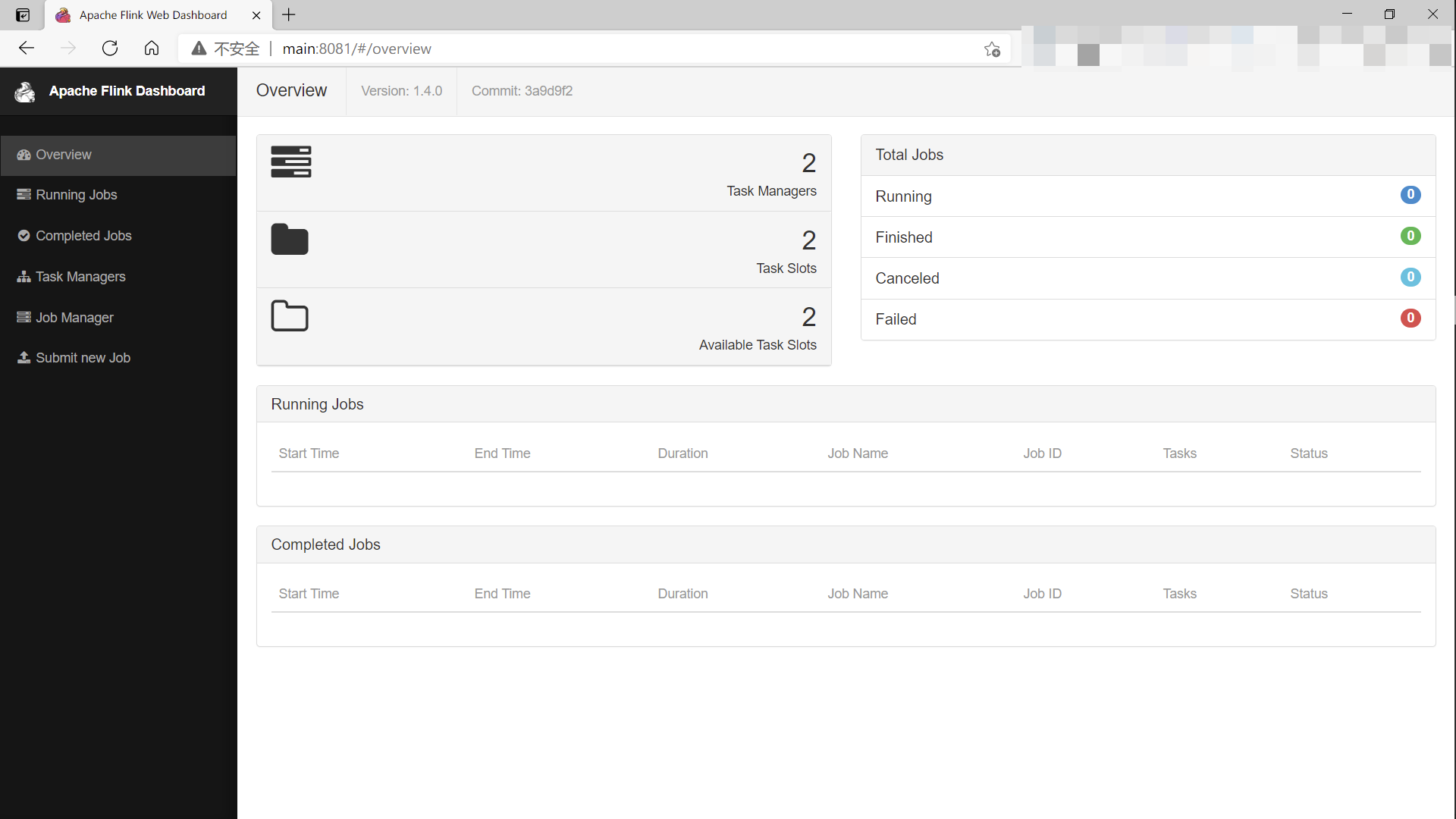
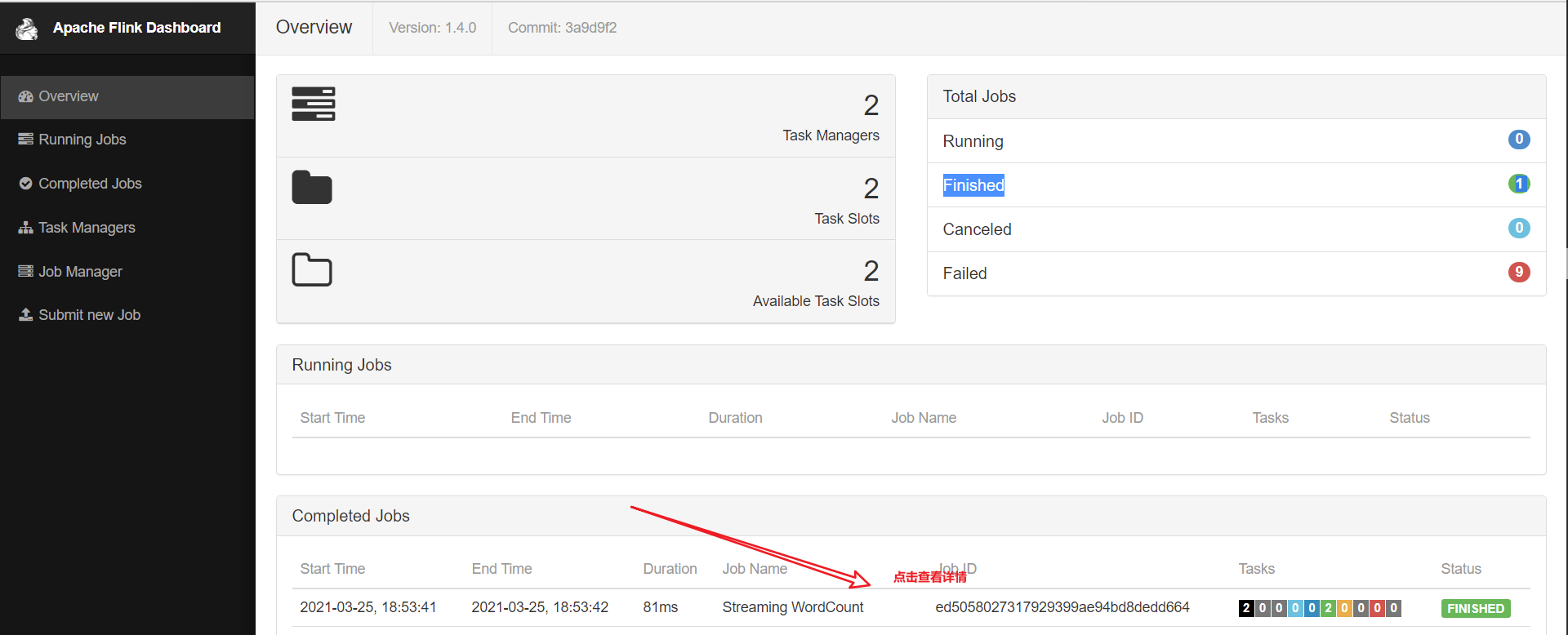
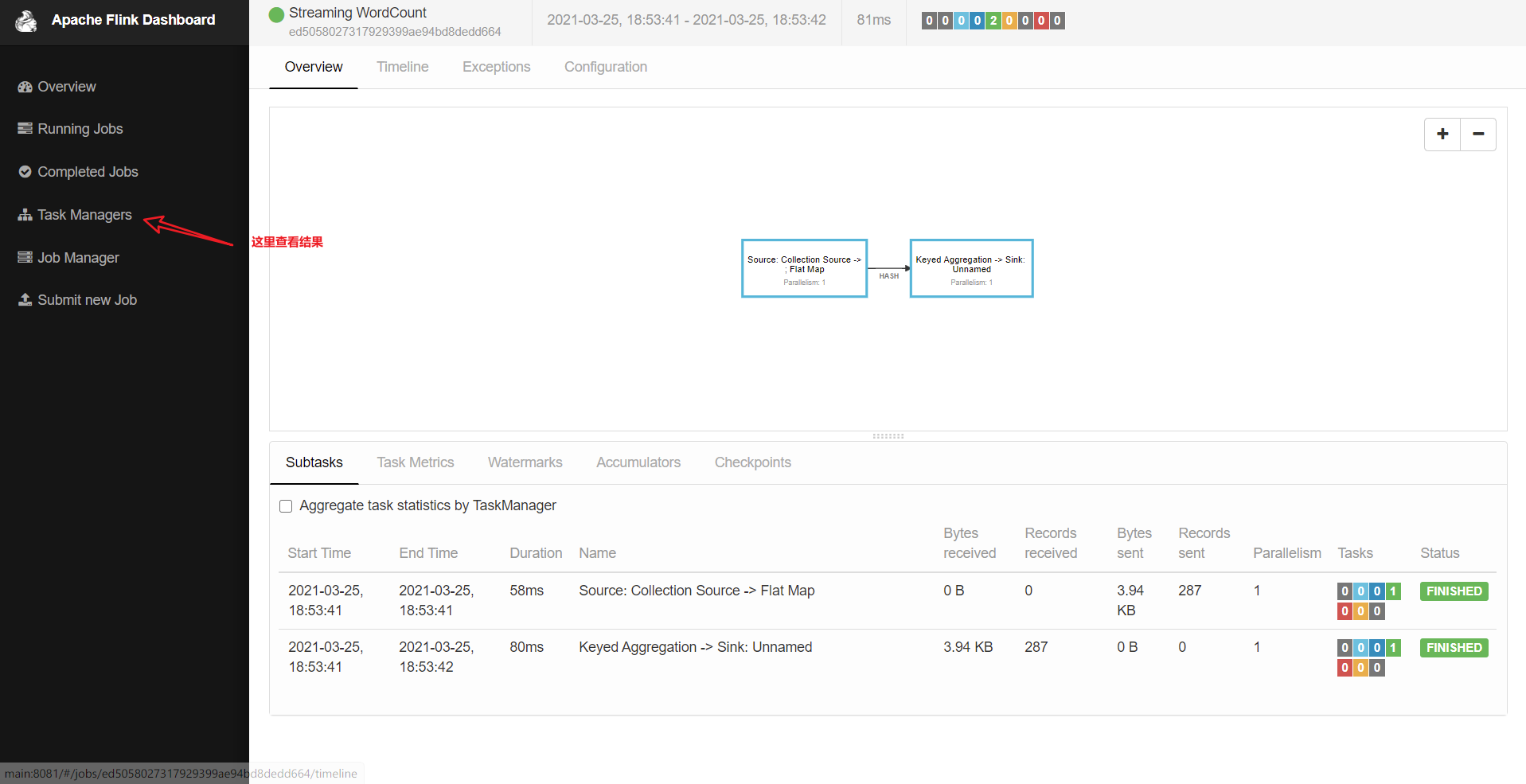
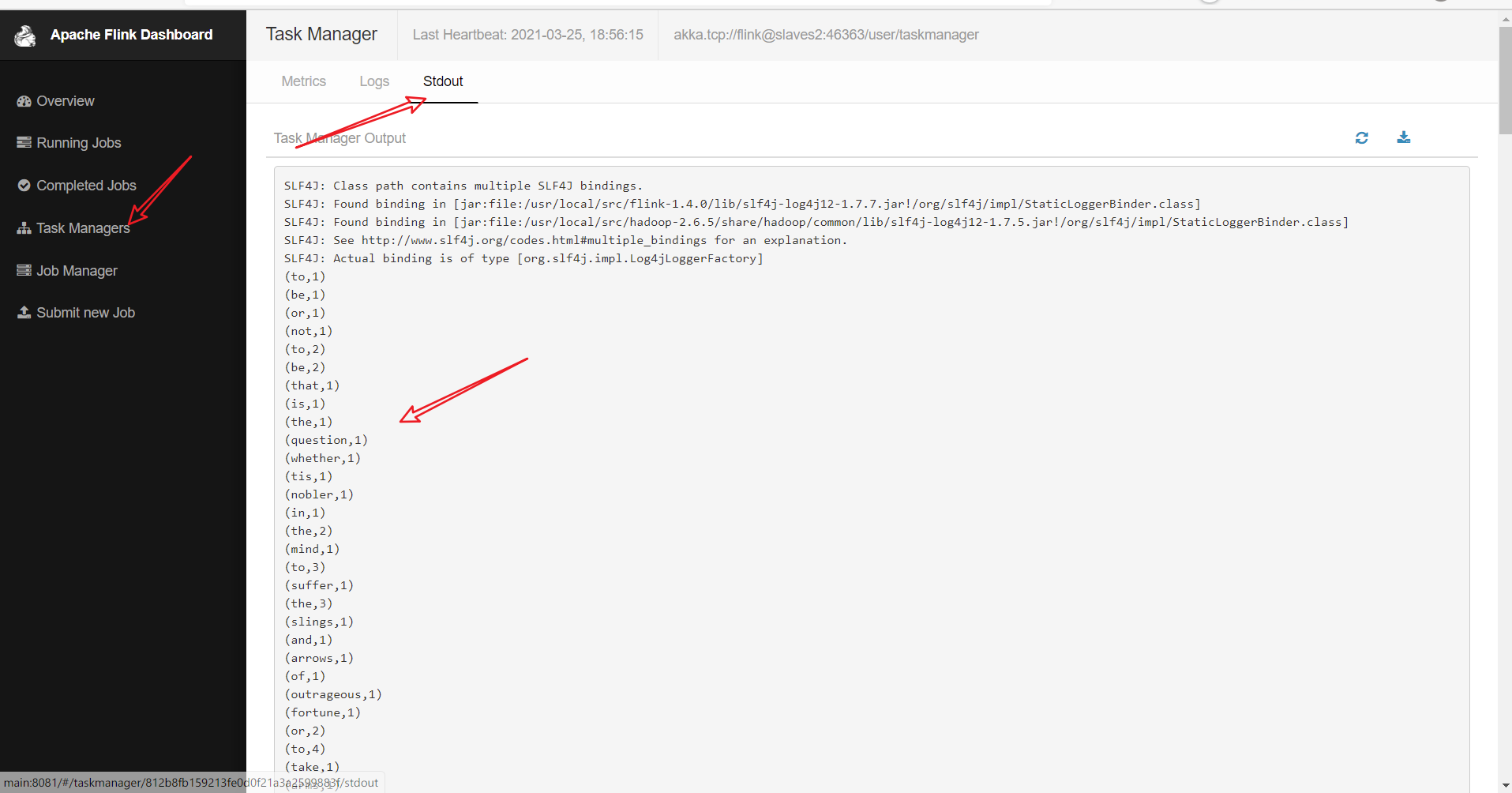
(base) [root@main bin]# flink run ../examples/streaming/WordCount.jar Using the result of 'hadoop classpath' to augment the Hadoop classpath: /usr/local/src/hadoop-2.6.5/etc/hadoop:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/*:/usr/local/src/hadoop-2.6.5/share/hadoop/common/*:/usr/local/src/hadoop-2.6.5/share/hadoop/hdfs:/usr/local/src/hadoop-2.6.5/share/hadoop/hdfs/lib/*:/usr/local/src/hadoop-2.6.5/share/hadoop/hdfs/*:/usr/local/src/hadoop-2.6.5/share/hadoop/yarn/lib/*:/usr/local/src/hadoop-2.6.5/share/hadoop/yarn/*:/usr/local/src/hadoop-2.6.5/share/hadoop/mapreduce/lib/*:/usr/local/src/hadoop-2.6.5/share/hadoop/mapreduce/*:/usr/local/src/hadoop-2.6.5/contrib/capacity-scheduler/*.jar SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/src/flink-1.4.0/lib/slf4j-log4j12-1.7.7.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/src/hadoop-2.6.5/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Cluster configuration: Standalone cluster with JobManager at main/192.168.10.113:6123 Using address main:6123 to connect to JobManager. JobManager web interface address http://main:8081 Starting execution of program Executing WordCount example with default input data set. Use --input to specify file input. Printing result to stdout. Use --output to specify output path. Submitting job with JobID: ed5058027317929399ae94bd8dedd664. Waiting for job completion. Connected to JobManager at Actor[akka.tcp://flink@main:6123/user/jobmanager#884749380] with leader session id 00000000-0000-0000-0000-000000000000. 03/25/2021 18:53:41 Job execution switched to status RUNNING. 03/25/2021 18:53:41 Source: Collection Source -> Flat Map(1/1) switched to SCHEDULED 03/25/2021 18:53:41 Keyed Aggregation -> Sink: Unnamed(1/1) switched to SCHEDULED 03/25/2021 18:53:41 Source: Collection Source -> Flat Map(1/1) switched to DEPLOYING 03/25/2021 18:53:41 Keyed Aggregation -> Sink: Unnamed(1/1) switched to DEPLOYING 03/25/2021 18:53:41 Keyed Aggregation -> Sink: Unnamed(1/1) switched to RUNNING 03/25/2021 18:53:41 Source: Collection Source -> Flat Map(1/1) switched to RUNNING 03/25/2021 18:53:41 Source: Collection Source -> Flat Map(1/1) switched to FINISHED 03/25/2021 18:53:42 Keyed Aggregation -> Sink: Unnamed(1/1) switched to FINISHED 03/25/2021 18:53:42 Job execution switched to status FINISHED. Program execution finished Job with JobID ed5058027317929399ae94bd8dedd664 has finished. Job Runtime: 84 ms