
常见hive 优化方式
常见hive 优化方式有哪些?
1.操作系统调优;
Hadoop主要的操作系统是Linux,Linux系统调优包括文件系统的选择、cpu的调度、内存构架和虚拟内存的管理、IO调度和网络子系统的选择等等。
2.原子化操作
避免一个SQL包含复杂逻辑,可以使用中间表来完成复杂的逻辑,从而提高整体执行效率。一般来说,单个SQL所起的JOB个数尽量控制在5个以下。如果Union All的部分个数大于2,或者每个Union部分数据量大,应该拆分成多个Insert Into语句
4.充分利用服务器资源
让服务器尽可能的多做事情,充分利用服务器的计算资源,以实现最高的系统吞吐量为目标。比如一个作业能做完的事情就不要拆开两个作业来完成。Reduce个数过少不能真正发挥Hadoop并行计算的优势,但Reduce个数过多,会造成大量小文件问题,所以需要根据数据量和资源情况找到一个折衷点。
Hive可以将没有依赖关系的多次MR过程(例如Union All语义中的多个子查询)并发提交。使用hive.exec.parallel参数控制在同一个SQL中的不同作业是否可以同时运行,从而提高作业的并发,充分利用服务器的资源:
SET hive.exec.parallel=true;
SET hive.exec.parallel.thread.number=最大并发job数;
5.选择最优的执行路径
让服务器尽量少做事情,选择最优的执行路径,以资源消耗最少为目标。比如:
注意Join的使用,两表关联时,若其中有一个表很小,则使用Map Join,否则使用普通的Reduce Join
SET hive.auto.convert.join=true ;
SET hive.smalltable.filesize=25000000L(默认是25M);
6.注意小文件的问题
在Hive里有两种比较常见的处理办法。第一是使用Combinefileinputformat,将多个小文件打包作为一个整体的Inputsplit,减少Map任务数;
SET mapred.max.split.size=128000000;
SET mapred.min.split.size=128000000;
SET mapred.min.split.size.per.node=128000000;
SET mapred.min.split.size.per.rack=128000000;
SET hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
第二是文件数目小,容易在文件存储端造成瓶颈,给 HDFS 带来压力,影响处理效率。对此,可以通过合并Map和Reduce的结果文件来消除这样的影响。设置Hive参数,将额外启动一个MR Job打包小文件。
用于设置合并属性的参数有:
是否合并Map输出文件:SET hive.merge.mapfiles=true;(默认值为真)
是否合并Reduce 端输出文件:SET hive.merge.mapredfiles= true;(默认值为假)
合并文件的大小:SET hive.merge.size.per.task=256*1000*1000;(默认值为 256000000)
7.注意执行过程中的数据倾斜问题
在Hive调优中比较常用的处理办法有两种:
第一,通过hive.groupby.skewindata = true控制生成两个MR Job,第一个MR Job Map的输出结果随机分配到Reduce做次预汇总,减少某些key值条数过多或过小造成的数据倾斜问题。
第二,通过hive.map.aggr = true(默认为true)在Map端做Combiner,假如map各条数据基本上不一样,聚合没什么意义,做Combiner反而画蛇添足,Hive会通过以下两个参数:
hive.groupby.mapaggr.checkinterval = 100000 (默认)
hive.map.aggr.hash.min.reduction = 0.5(默认)
预先取100000条数据聚合,如果聚合后的条数/100000>0.5,则不再做聚合。
8.合理设置Map与Reduce的个数
增加Map数
同时可执行的Map数是有限的,通常情况下,作业会通过Input的目录产生一个或者多个Map任务,而主要的决定因素是Input的文件总个数和Input的文件大小。
如果表A只有一个文件,且大小超过100M,包含上千万记录,任务较为耗时,可以考虑用多个Map任务完成,有效提升性能
合理设置Reduce数
增加map数可以通过控制一个作业的Reduce数来加以控制。Reduce个数的设定会极大影响执行效率,一般基于以下参数设定:
hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,如1G)
hive.exec.reducers.max(每个任务最大的reduce数)
如果Reduce的输入(Map的输出)总大小不超过1G,那么只会有一个Reduce任务。可以根据实际情况,通过缩小每个Reduce任务处理的数据量来提高执行性能。
9.JVM重用
hadoop生态系统底层是java开发的,也就是说它基于JVM运行,因此我们可以设置JVM重用来优化hadoop和hive。
hadoop默认配置是派生JVM来执行map和reduce任务的,这时JVM的启动可能会造成很大的开销,尤其是执行的job包含上千个task的时候,JVM重用可以使得JVM实例在同一个job中重新使用N次。这个参数可以在hadoop的安装目录下的mapred-site.xml文件中配置:
1 | <property> |
这个参数有一个缺点,开启JVM重用将会一直占用使用到的task插槽,以便进行重用,直到执行结束才会释放,如果某个job中有几个task执行的时间比其他task时间多很多,那么它们会一直保留插槽让其空闲无法被其他job使用,因此浪费了资源。
10.对Hive输入或输出的数据进行合理的压缩存储
创建表时,尽量使用 orc、parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量。
压缩的原因
Hive 最终是转为 MapReduce 程序来执行的,而MapReduce 的性能瓶颈在于网络 IO 和 磁盘 IO,要解决性能瓶颈,最主要的是减少数据量,对数据进行压缩是个好的方式。压缩 虽然是减少了数据量,但是压缩过程要消耗CPU的,但是在Hadoop中, 往往性能瓶颈不在于CPU,CPU压力并不大,所以压缩充分利用了比较空闲的 CPU
常用压缩方法对比
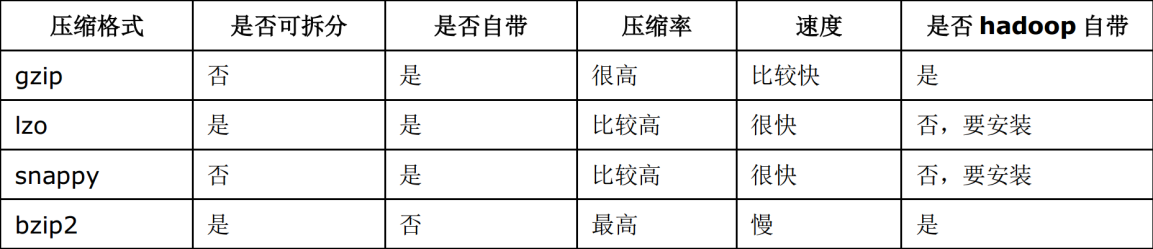
各个压缩方式所对应的 Class 类:

压缩使用
Job 输出文件按照 block 以 GZip 的方式进行压缩:
set mapreduce.output.fileoutputformat.compress=true // 默认值是 false
set mapreduce.output.fileoutputformat.compress.type=BLOCK // 默认值是 Record
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec // 默认值是 org.apache.hadoop.io.compress.DefaultCodec
Map 输出结果也以 Gzip 进行压缩:
set mapred.map.output.compress=true
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.GzipCodec // 默认值是 org.apache.hadoop.io.compress.DefaultCodec
对 Hive 输出结果和中间都进行压缩:
set hive.exec.compress.output=true // 默认值是 false,不压缩
set hive.exec.compress.intermediate=true // 默认值是 false,为 true 时 MR 设置的压缩才启用
11.Hive Sql调优
Hive查询生成多个Map Reduce作业,一个Map Reduce作业又有map,reduce,spill,shuffle,sort等多个阶段,所以针对Hive SQL的优化可以大致分为针对MR中单个步骤的优化,针对MR全局的优化以及针对整个查询的优化。Hive SQL的调优贯穿所有阶段,主要是解决运行过程中数据倾斜问题,减少作业数,对小文件进行合并处理,合理设置Map Reduce的任务数等,根据数据量和模型情况,通过迭代调测来有效提升性能。以下是常见的Hive SQL调优方法:
Hive join优化
减少不必要的关联
Hive SQL和其他SQL一样,是一种功能强大的说明性语言,对于同一个业务功能,可以通过不同的写法来实现,而不同的写法会产生不同的性能特点。
例如一个点击率表,包括了访问时间、SessionID、网址和来源IP地址共四个字段:
1 | CREATE TABLE clicks ( |
假设我们需要查找每个SessionID最后一次的访问网址:
方法一:
1 | SELECT clicks.* FROM clicks inner join |
该方法使用了子查询方法去收集每个SessionID的最后访问时间,然后通过Inner Join自关联去排除掉之前的点击访问记录,效率较低。
方法二:
1 | SELECT * FROM (SELECT *, RANK() over (partition by sessionID,order by timestamp desc) as rank FROM clicks) ranked_clicks |
这里使用了OLAP的排位函数去实现相同的业务查询,关键不需要表关联,仅为单表操作,删除不必要的关联在大数据开发上意义重大,能大幅提高性能。
带表分区的Join
Hive是先关联再进行Where条件判断,如果在右表b中找不到左表a表的记录,b表中的所以列都会显示为NULL,这种情况下left outer的
查询结果与where子句无关,解决办法是将Where条件放在JOIN ON的关联判断条件中。
SQL编写需要尽早过滤数据,以减少各个阶段的数据量,只选择需要用到的字段。
Skew Join优化
优化Skewed Join Key为Map Join。开启hive.optimize.skewjoin=true可优化处理过程中倾斜的数据。但需要注意Skew Join优化需要额外的Map Join操作,且不能节省Shuffle的代价。
利用随机数减少数据倾斜
大表之间Join容易因为空值而产生数据倾斜,除了通过过滤方法排除空值,还可以利用随机数分散到不同的Reduce上,例如:
1 | select a.uid |
把空值的Key变成一个字符串加上随机数,就能把倾斜的数据分到不同的Reduce上,解决数据倾斜问题。因为空值不参与关联,即使分到不同的Reduce上,也不影响最终的结果,而且IO减少,作业数也减少了,执行效率更优。
Group by
Group By是在Reduce阶段的操作,防止数据倾斜:
Map端聚合,提前一部分计算:Hive.map.aggr = true
hive.groupby.skewindata为ture的时候,生成的查询计划会有两个MRJob:
第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的。
第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
Count Distinct
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换:
1 | SELECT day, |
可以转换成:
1 | SELECT day, |
虽然会多用一个Job来完成,但在数据量大的情况下,这个绝对是值得的。
Order by VS Sort by
Order by是在全局的排序,只用一个Reduce去运行,所以在SET Hive.mapred.mode=strict 模式下,不允许执行以下查询:
1.没有limit限制的order by语句
2.分区表上没有指定分区
3.笛卡尔积(JOIN时没有ON语句)。
而Sort by是在每个Reduce内排序,只保证同一个Reduce下排序正确。
通用Hive SQL优化方法
1、尽量利用分区,比如按时间进行分区。
2、关联条件不能忽略,避免Select *。
3、关联字段的类型保持一致,避免字段的强制转换。
4、避免使用LIKE 进行模糊匹配的查询。
5、对查询进行优化,要尽量避免全表扫描
常用参数
(常用的一些可设置参数,具体数值按照需要进行调整!)
1 | SET hive.optimize.skewjoin = true; |
// Hive中间结果压缩和压缩输出
1 | SET hive.exec.compress.output = true; -- 默认false |
// 输出合并小文件
1 | SET hive.merge.mapfiles = true; -- 默认true,在map-only任务结束时合并小文件 |
// 设置map和reduce数量
1 | SET mapred.max.split.size = 256000000; |
// 设置数据倾斜和并行化
1 | SET hive.exec.parallel = true; -- 并行执行 |
//关闭以下两个参数来完成关闭Hive任务的推测执行
1 | SET mapred.map.tasks.speculative.execution=false; |





