
Hive数据倾斜常见场景及处理
什么是数据倾斜?
由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点。发生在shuffle阶段,解决其发生的
根本办法是如何将数据均匀的分配到各个reduce中。
如何判断数据倾斜
任务进度长时间维持在 99%或者 100%的附近,查看任务监控页面,发现只有少量 reduce 子任务未完
成,因为其处理的数据量和其他的 reduce 差异过大。 单一 reduce 处理的记录数和平均记录数相差太
大,通常达到好几倍之多,最长时间远大 于平均时长。
数据倾斜的几种情况
| 关键词 | 情况 | 结果 |
|---|---|---|
| join | 大表与小表join,小表对应于大表 join 的字段较为集中,比如说按照客户购物发生的时间(以一周中的周几为维度)进行join,假设小表中80%的客户购物发生时间字段为周五; | 那么大表(假设大表有1亿条记录)与小表join的时候,在reduce阶段取模,就会有8千万的数据被分到处理周五这个字段的reduce上,其余六个reduce均匀分配2千万条数据,这样会造成处理周五这个字段的reduce压力过大,运行缓慢,当其他reduce完成时,该reduce还在缓慢执行。 |
| join | 大表与大表join,但是partition的判断字段0值或者空值或者Null值过多; | 同上面的情形差不多,都会导致一个reduce处理大部分的数据,reduce处理的压力过大,作业缓慢。 |
| GroupBy | 对大表按照某个字段进行group by,但是该字段的维度过小; | 同以上情况基本一致。 |
| Count Distinct | 计算的列特殊值较多,数据量较大 | 同以上情况基本一致 |
数据倾斜产生的原因
1.key 分布不均匀
2.业务数据本身的特性
3.建表考虑不周全
4.某些 HQL 语句本身就存在数据倾斜
场景与解决思路
join/group by/count distinct
字段较为集中的场景
1.将较为集中的字段值进行打散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率;
1 | create table small_table as |
2.使用map join让小的维度表先进内存;
1 | select * from small_table s join big_table b on s.key = b.key; |
空值产生的数据倾斜
在日志中,常会有信息丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和用户表中的 user_id 相关联,就会碰到数据倾斜的问题。
1.筛选出不为空值的参与关联;
1 | select * from log a join user b on a.user_id is not null and a.user_id = b.user_id |
2.赋予空值新的key值
1 | select |
总结
方法 2 比方法 1 效率更好,不但 IO 少了,而且作业数也少了,方案 1 中,log 表 读了两次,jobs 肯定是 2,而方案 2 是 1。这个优化适合无效 id(比如-99,’’,null)产 生的数据倾斜,把空值的 key 变成一个字符串加上一个随机数,就能把造成数据倾斜的 数据分到不同的 reduce 上解决数据倾斜的问题。
改变之处:使本身为 null 的所有记录不会拥挤在同一个 reduceTask 了,会由于有替代的 随机字符串值,而分散到了多个 reduceTask 中了,由于 null 值关联不上,处理后并不影响最终结果。
不同数据类型关联产生的数据倾斜
用户表中 user_id 字段为 int,log 表中 user_id 为既有 string 也有 int 的类型, 当按照两个表的 user_id 进行 join 操作的时候,默认的 hash 操作会按照 int 类型的 id 进 行分配,这样就会导致所有的 string 类型的 id 就被分到同一个 reducer 当中。
1.把数字类型 id 转换成 string 类型的 id;
1 | select * from user a left outer join log b on b.user_id = cast(a.user_id as string) |
大小表关联查询产生数据倾斜
可以使用map join解决大小表关联造成的数据倾斜问题。
map join 概念:将其中做连接的小表(全量数据)分发到所有 MapTask 端进行 Join,从 而避免了 reduceTask,前提要求是内存足以装下该全量数据
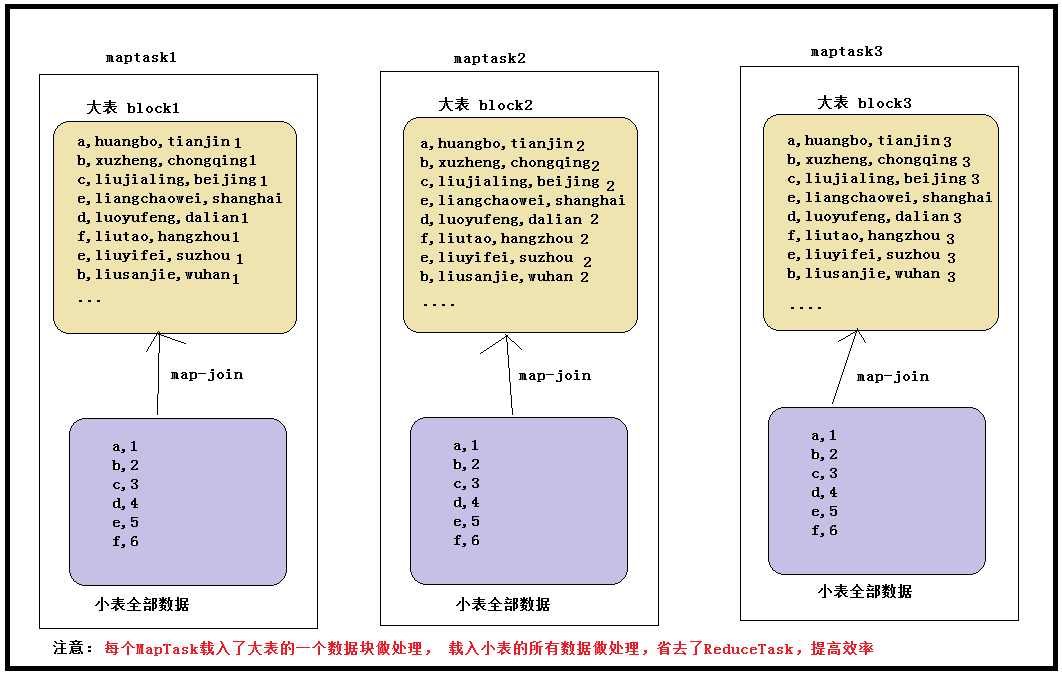
1 | select /* +mapjoin(a) */ a.id aid, name, age from a join b on a.id = b.id; |
在 hive0.11 版本以后会自动开启 map join 优化,由两个参数控制:
set hive.auto.convert.join=true; //设置 MapJoin 优化自动开启
set hive.mapjoin.smalltable.filesize=25000000 //设置小表不超过多大时开启 mapjoin 优化
大大表关联查询产生数据倾斜
1.把大表切分成小表,然后分别 map join;
例子:日志表和用户表两个大表做关联
bad case:
1 | select * from log a left outer join users b on a.user_id = b.user_id; |
optimize case:
1 | select /*+mapjoin(x)*/* |
聚合时存在大量特殊值
做count distinct时,目标字段存在大量值为NULL或空的记录。
1.count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。
2.如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union;
这里+1,是对null 进行 cnt,因为null值被过滤掉了,因此算的时候 要+1,加回来;
case:
1 | select |
多个distinct集中在一个reduce上进行
bad case:
1 | Select day,count(distinct session_id),count(distinct user_id) from log a group by day |
1.空间换时间;
optimize case:
1 | select day |
思路:将同一个表互相union all,通过设置type字段用于代替distinct xxx_id,虽然消耗了更大的空间,但是提高了执行的效率。
实操案例—空间换时间:
1 | Select reordered,count(distinct order_id),count(distinct product_id) from priors group by reordered limit 10; |
Result
1 | Total MapReduce CPU Time Spent: 7 minutes 55 seconds 240 msec |
1 | select reordered |
Result
1 | Total MapReduce CPU Time Spent: 4 minutes 22 seconds 500 msec |
补充
group by 引起的倾斜
对于 group by 引起的倾斜,优化措施非常简单,只需设置下面参数即可:
set hive.map.aggr = true配置代表开启map端聚合;
万用参数:
set hive.groupby.skewindata=true本质:将一个mapreduce拆分为两个MR
此时Hive 在数据倾斜的时候会进行负载均衡,生成的查询计划会有两个 MapReduce Job。
第一个 MapReduce Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个Reduce 做部分聚合操作并输出结果。这样处理的结果
是相同的 GroupBy Key 有可能被分布到不同的 Reduce 中,从而达到负载均衡的目的;
第二个 MapReduce Job 再根据预处理的数据结果,按照 GroupBy Key 分布到 Reduce 中(这过程可以保证相同的GroupBy Key被分布到
同一个Reduce中),最后完成最终的聚合操作;
参考链接
链接一.





