大数据分布式采集架构--Flume入门
Flume理论+实践
Flume基础
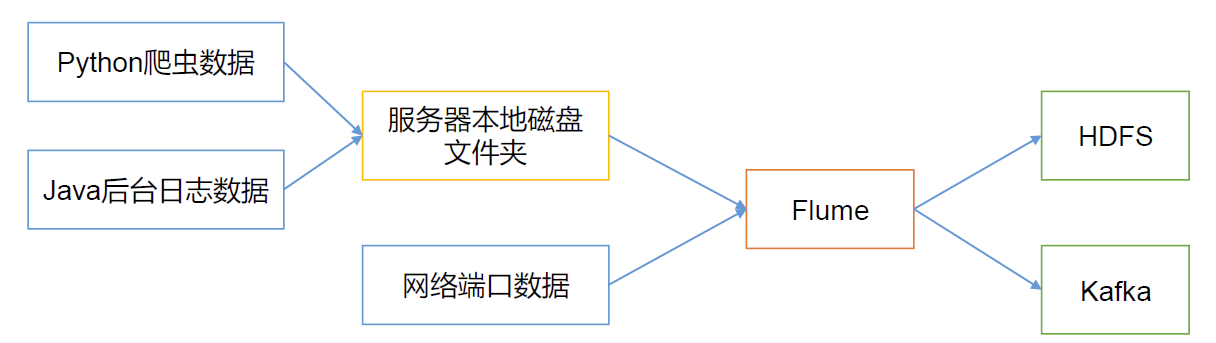
Flume 是Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。 目前业界,大公司日常的业务数据量一般都能够达到PB级别,小公司也有TB级别。Flume是一个分布式的日志采集、数据收集框架,可以高效的从各个网站服务器中收集日志数据,并且存储到Hbase、HDFS中。
Flume可以对接的数据源有
console、PRC、Text、Tail、Syslog、Exec等;
Flume接收的数据源的输出目标
磁盘、hdfs、hbase,经过网络输出给Kafka
data->flume->kafka->spark streaming/storm/flink -> Hbase,mysql
Flume组成架构
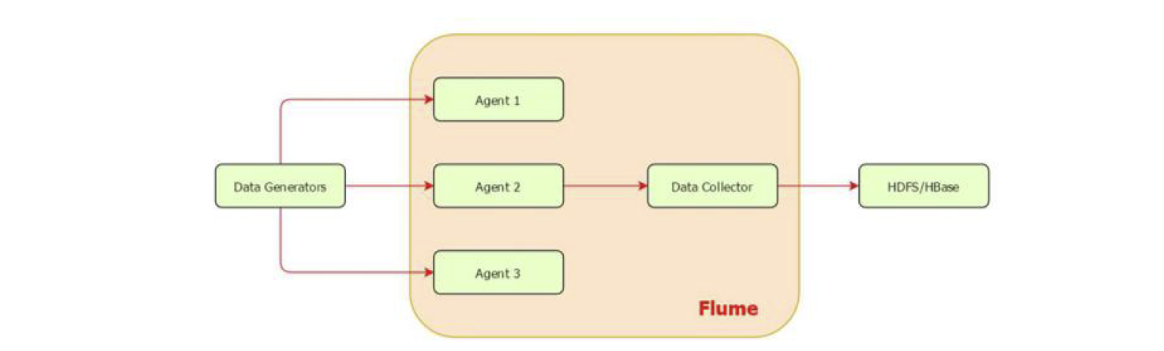
数据发生器(如: facebook, twitter)产生的数据被单个的运行在数据发生器所在服务器上的agent所收集,之后数据收容器从各个 agent上汇集数据并将采集到的数据存入到HDFS或者Hbase中。
agent是部署在一个服务器里的进程(JVM),负责收集该服务器产生的日志数据。
Flume架构详解
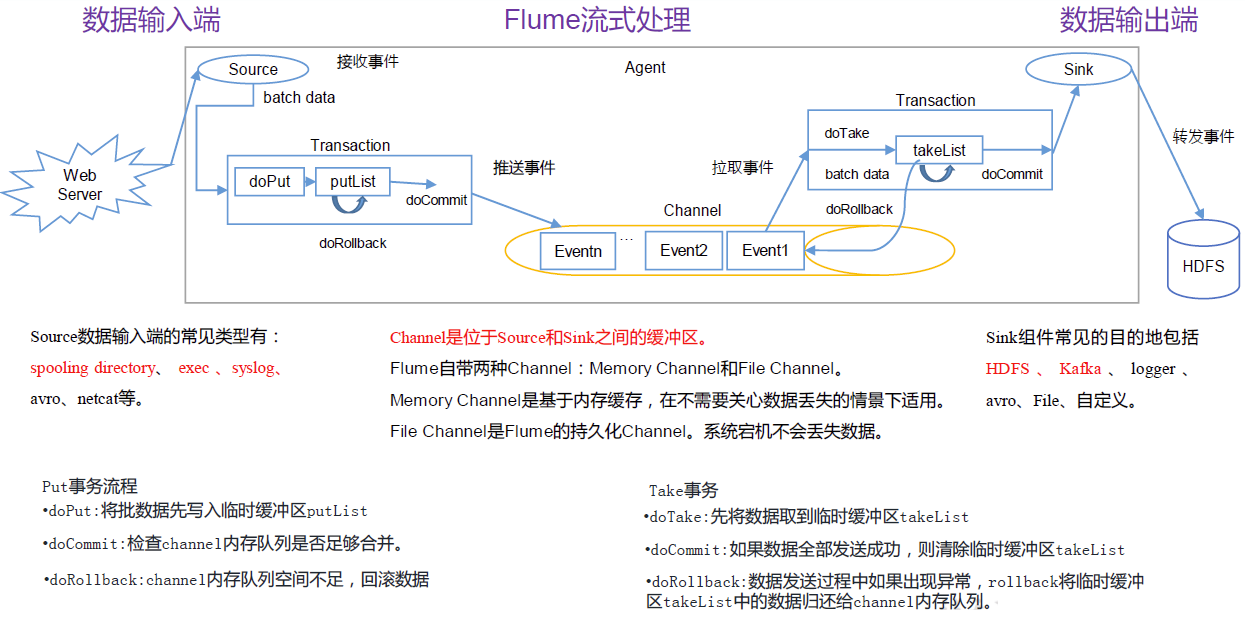
Agent
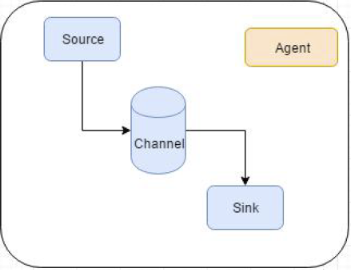
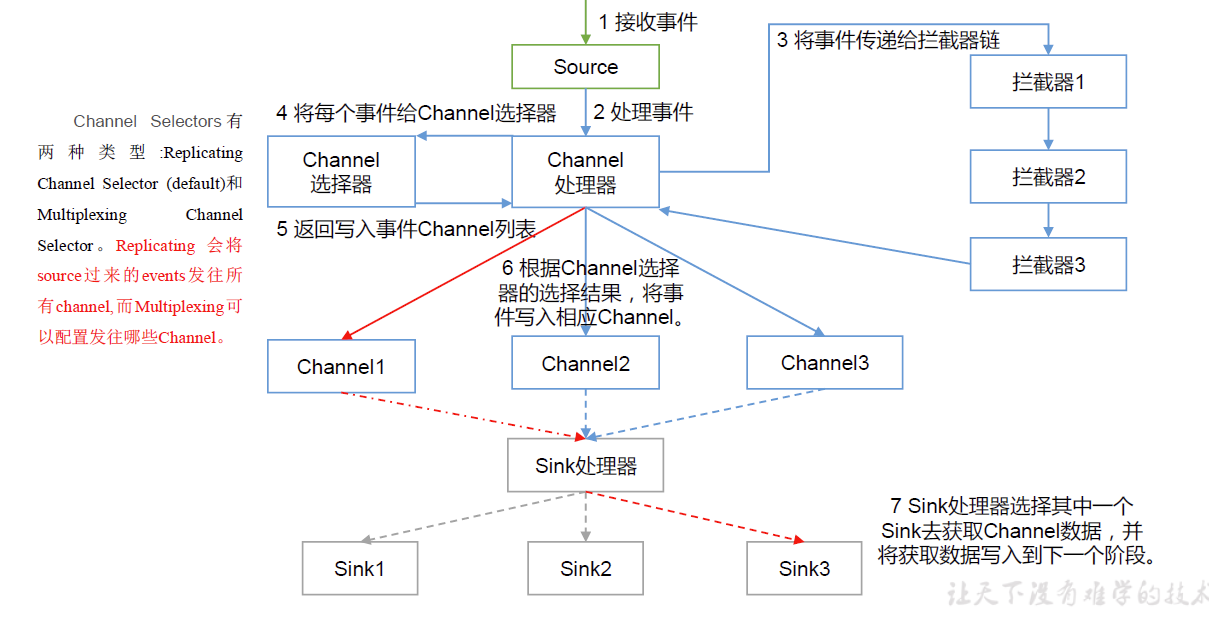
Flume内部有一个或者多个 Agent,每一个 Agent是一个独立的守护进程(JVM),从客户端接收,或者从其他的 Agent接收,然后迅速的将获取的数据传给下一个目的节点 Agent。Agent是Flume数据传输的基本单元。Agent主要有3个部分组成:Source->(interceptor->selector)->Channel->Sink;
Source
Source是一个 Flume源, 是负责接收数据到Flume Agent 的组件。
Source负责一个外部源(数据发生器),如一个web服务器传递给他的事件,该外部源将它的事件以 Flume可以识别的格式发送到Flume中,当一个 Flume源接收到一个事件时,其将通过一个或者多个通道存储该事件。
Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence generator、 syslog、http、legacy。
关于Source处理的各种数据类型的补充:
Avro 类型的Source
监听Avro 端口来接收外部avro客户端的事件流。avro-source接收到的是经过avro序列化后的数据,然后 反序列化数据继续传输。所以,如果是avro-source的话,源数据必须是经过avro序列化后的数据。利用 Avro source可以实现多级流动、扇出流、扇入流等效果。接收通过flume提供的avro客户端发送的日 志信息。
Exec类型的Source
可以将命令产生的输出作为源
1 | a1.sources.r1.command=ping 192.168.234.163 要执行的命令 |
Taildir Source
监控指定的多个文件,一旦文件内有新写入的数据,就会将其写入到指定的sink内,本来源可靠性高,不会丢失数据,建议使用;但目前不适用于Windows系统;其不会对于跟踪的文件有任何处理,不会重命名也不会删除,不会做任何修改,这点比Spooling Source有优势;目前不支持读取二进制文件,支持一行一行的读取文本文件;在实时数据处理中,可以用该方式取代Exec方式,因为本方式可靠性高。
Spooling Directory类型的 Source
将指定的文件加入到“自动搜集”目录中。flume会持续监听这个目录,把文件当做source来处理。注意:一旦文件被放到“自动收集”目录中后,便不能修改,如果修改,flume会报错。此外,也不能有重名的文件,如果有,flume也会报错。
1 | a1.sources.r1.spoolDir=/home/work/data 读取文件的路径,即"搜集目录" |
NetCat Source
一个NetCat Source用来监听一个指定端口,并接收监听到的数据。
Kafka Source
支持从Kafka指定的topic中读取数据。
Sequence Generator Source —序列发生源
一个简单的序列发生器,不断的产生事件,值是从0开始每次递增1。主要用来测试。
Channel
Channel 是位于Source 和Sink 之间的缓冲区。简单来说,channel就是一个通道,存储池,起缓存作用。只有当数据传输完成后,该event才从通道中移除(可靠性)。(Event的最大个数可以由参数设置)
因此,Channel 允许 Source 和Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个Source 的写入操作和几个 Sink的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel。 Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
- file:本地磁盘的事务实现模式,保证数据不会丟失(WAL实现) write ahead log
- memoery:内存存储事务,吞吐率极高,但存在丟数据风险
Flume通常选择 File Channel,而不使用 Memory Channel。
补充概念:Event
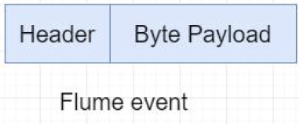
Flume数据的传输单元,Event对象是Flume 内部数据传输的最基本单元,以事件的形式将数据从源头送至目的地。它是由一个转载数据的字节数组+ー个可选头部构成 。
Event由零个或者多个 header(可以起到过滤作用)和正文body组成。Header是key/vaue形式的,可以用来制造路由决策或携带其他结构化信息(如事件的时间戳或事件来源的服务器主机名)。你可以把它想象成和HTTP头一样提供相同的功能一一通过该方法来传输正文之外的额外信息。Body是一个字节数组,包含了实际的内容。
Sink
sink是数据传输的目标,将event传输到外部介质。
Sink 不断地轮询Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Channel 启动一个事务。批量事件一旦成功写出到存储系统或下一个 Flume Agent,Sink 就利用Channel 提交事务。事务一旦被提交,该Channel 从自己的内部缓冲区删除事件。
总结
三个组件将代码和数据进行解耦,channel起到缓存作用,避免sink数据读取慢而source传输块造成数据丢失。channel可以放到mysql也可以放到kafka。
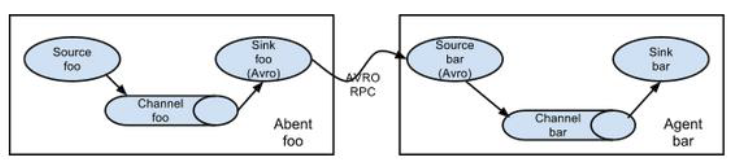
Flume的拓扑结构
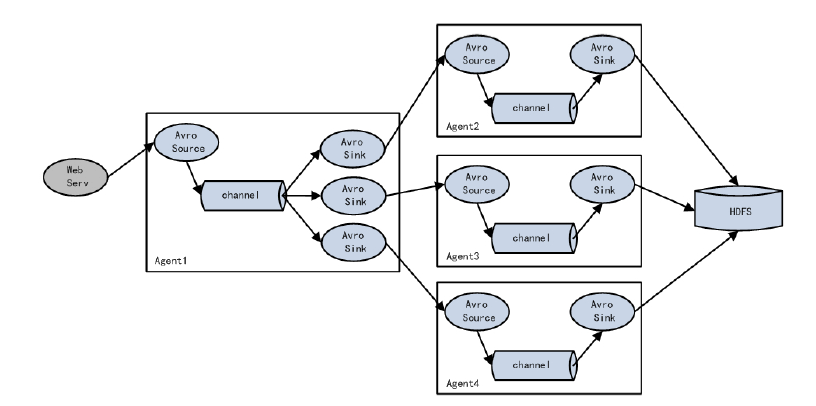
Agent对接Agent
单Source对接多Channel、Sink
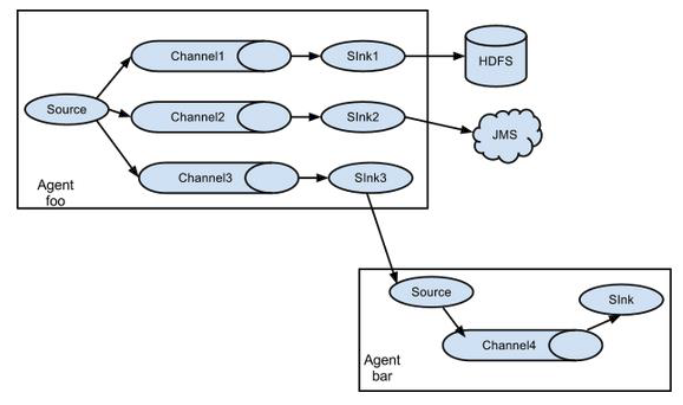
Flume负载均衡
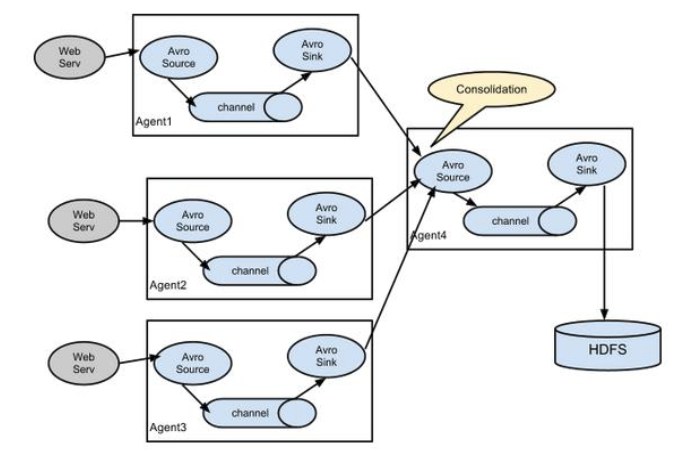
Flume Agent聚合
Flume Agent内部原理
补充
Flume中的source、interceptor、channel内部原理参考
https://blog.csdn.net/wx1528159409/article/details/87923754
Interceptor类型
Flume实践
需求1:通过netcat作为source,sink为logger方式
去修改example.conf配置文件,进行相关配置。
1 | ./bin/flume-ng agent --conf conf --conf-file ./conf/example.conf -name a1 -Dflume.root.logger=INFO,console |
需求2:通过netcat作为source, sink为logger的方式,并配置拦截器,拦截数字
1 | ./bin/flume-ng agent --conf conf --conf-file ./conf/example.conf -name a1 -Dflume.root.logger=INFO,console |
修改配置文件,增加过滤。
需求3:通过netcat作为source, sink写到hdfs
1 | ./bin/flume-ng agent --conf conf --conf-file ./conf/example.conf -name a1 -Dflume.root.logger=INFO,console |
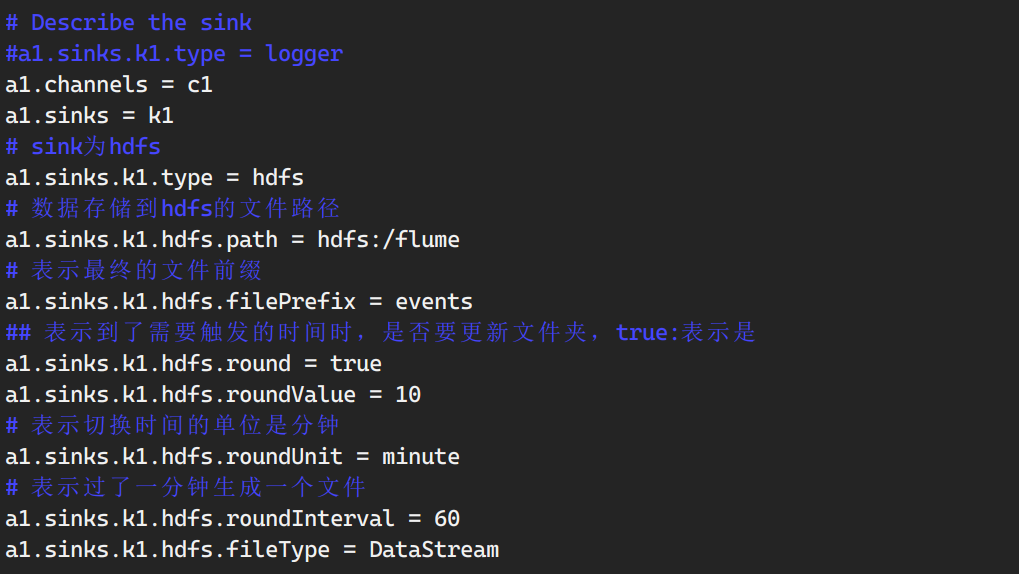
传入信息
写入hdfs
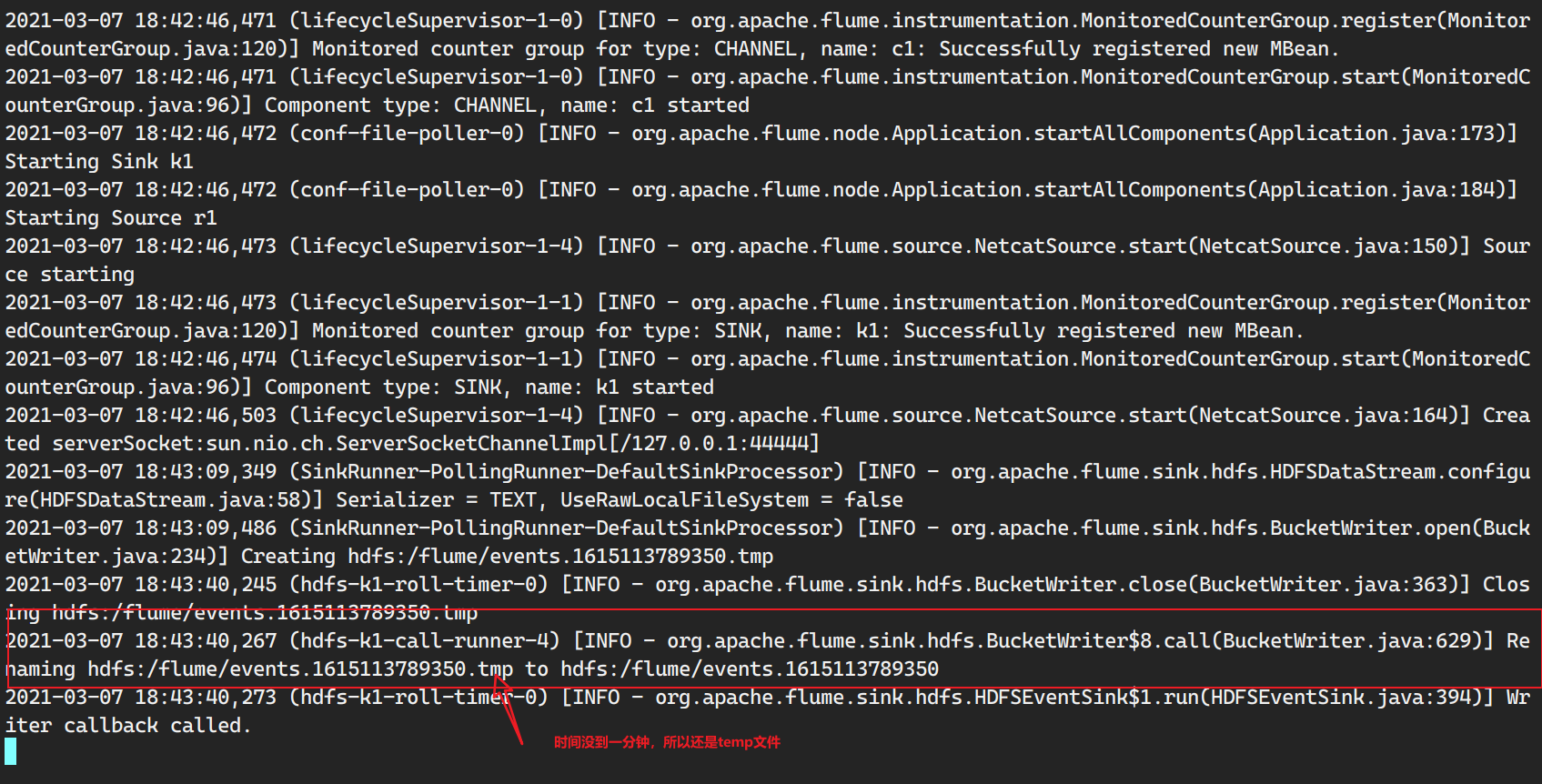
这里存在小文件问题,如何设置flume防止小文件?
1.在配置文件里配置roll.size,限定一个文件里存储多大的数据。
1 | a1.sinks.k1.hdfs.rollSize = 200*1024*1024 |
2.限定文件可以存储多少个event
1 | a1.sinks.k1.hdfs.rollCount = 10000 |
需求4:通过http作为source, sink写到logger
1 | # Name the components on this agent |
更改配置文件
1 | ./bin/flume-ng agent --conf conf --conf-file ./conf/header_test.conf -name a1 -Dflume.root.logger=INFO,console |
发送json数据
1 | curl -X POST -d '[{"headers" : {"timestamp" : "434324343","host" : "random_host.example.com"},"body" : "random_body"},{"headers" : {"namenode" : "namenode.example.com","datanode" : "random_datanode.example.com"},"body" : "badou,badou"}]' main:50020 |
需求5:将agent进行串联操作
1.在main上,配置slaves2作为sink,利用push.conf配置文件
1 | Name the components on this agent |
2.在slaves2上配置pull.conf
1 | Name the components on this agent |
3.在slaves2运行flume
1 | ./bin/flume-ng agent -c conf -f conf/pull.conf -n a2 -Dflume.root.logger=INFO,console |
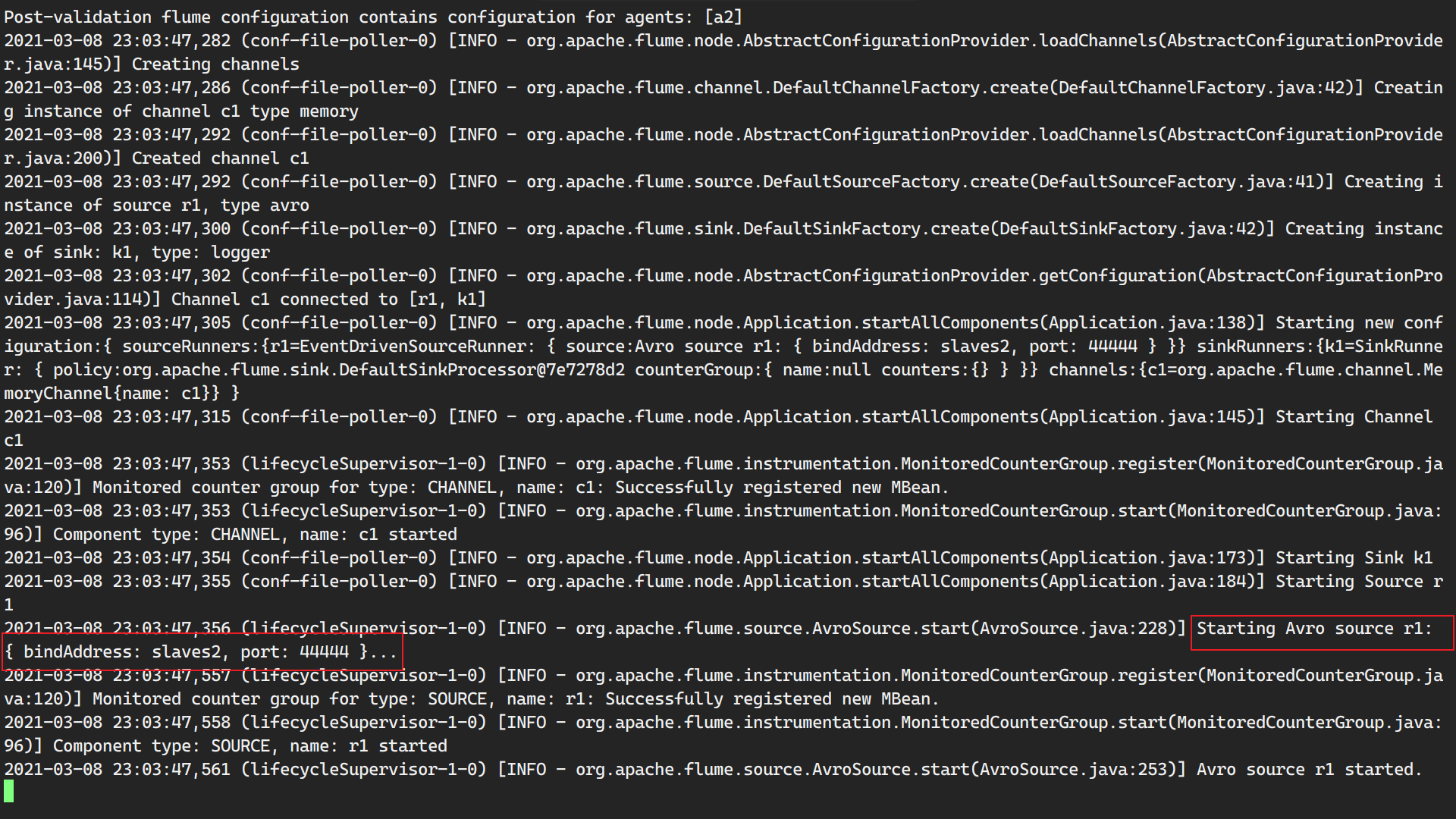
先启动第二个agent,因为先启动第一个agent master会报错,因为它会尝试连接第二个agent。
4.在master上启动flume
1 | ./bin/flume-ng agent -c conf -f conf/push.conf -n a1 -Dflume.root.logger=INFO,console |
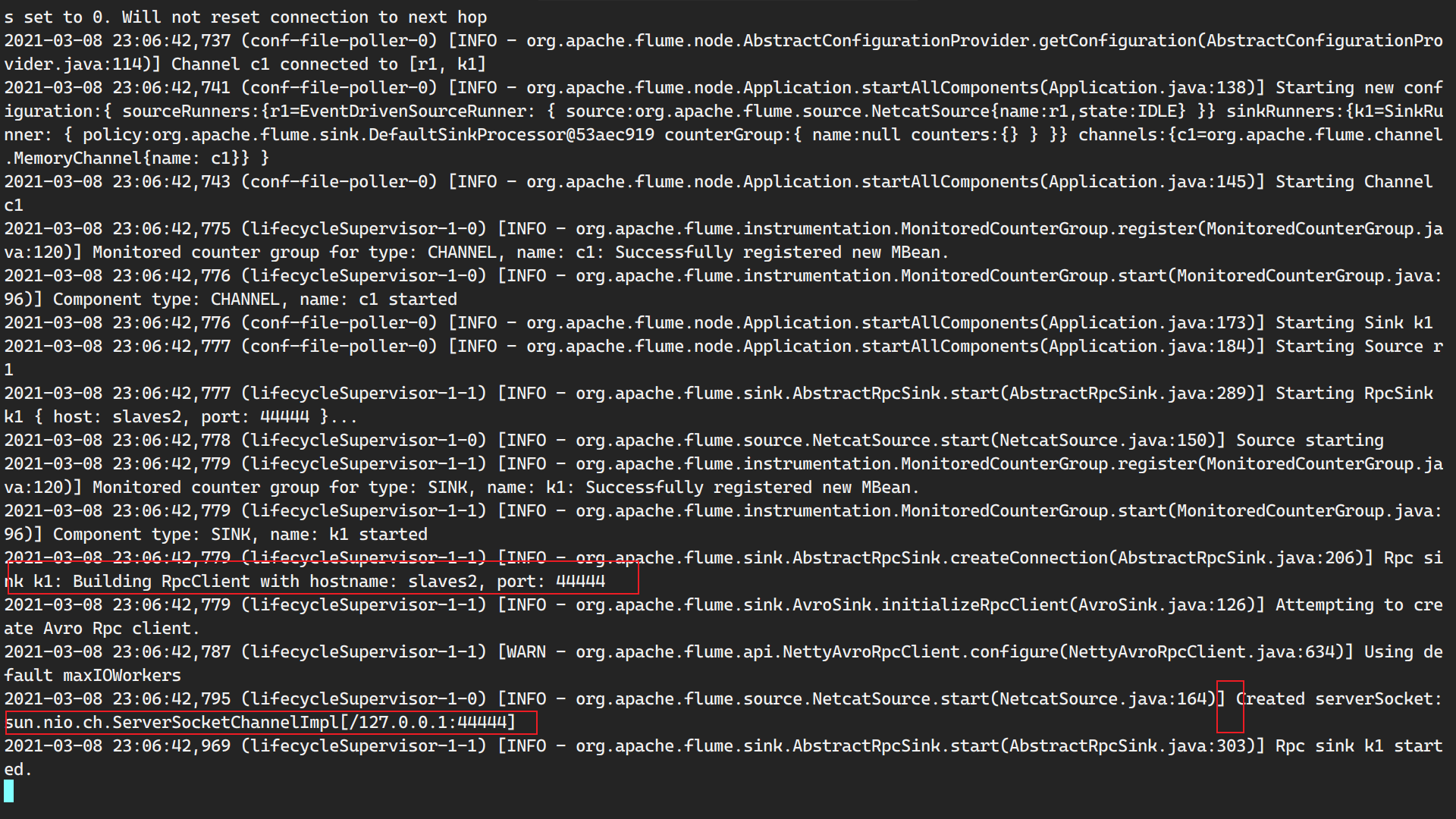
5.再创建一个main总端,开始给main传输数据
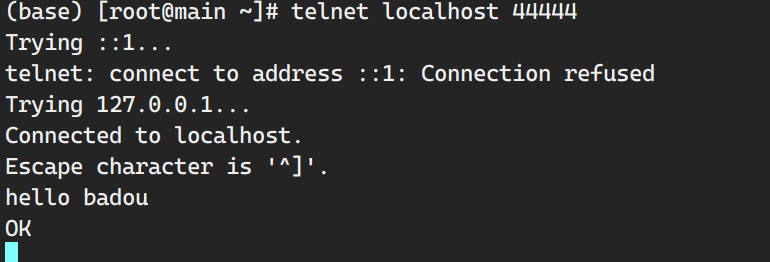
1 | (base) [root@main ~]# telnet localhost 44444 |
查看slaves2:
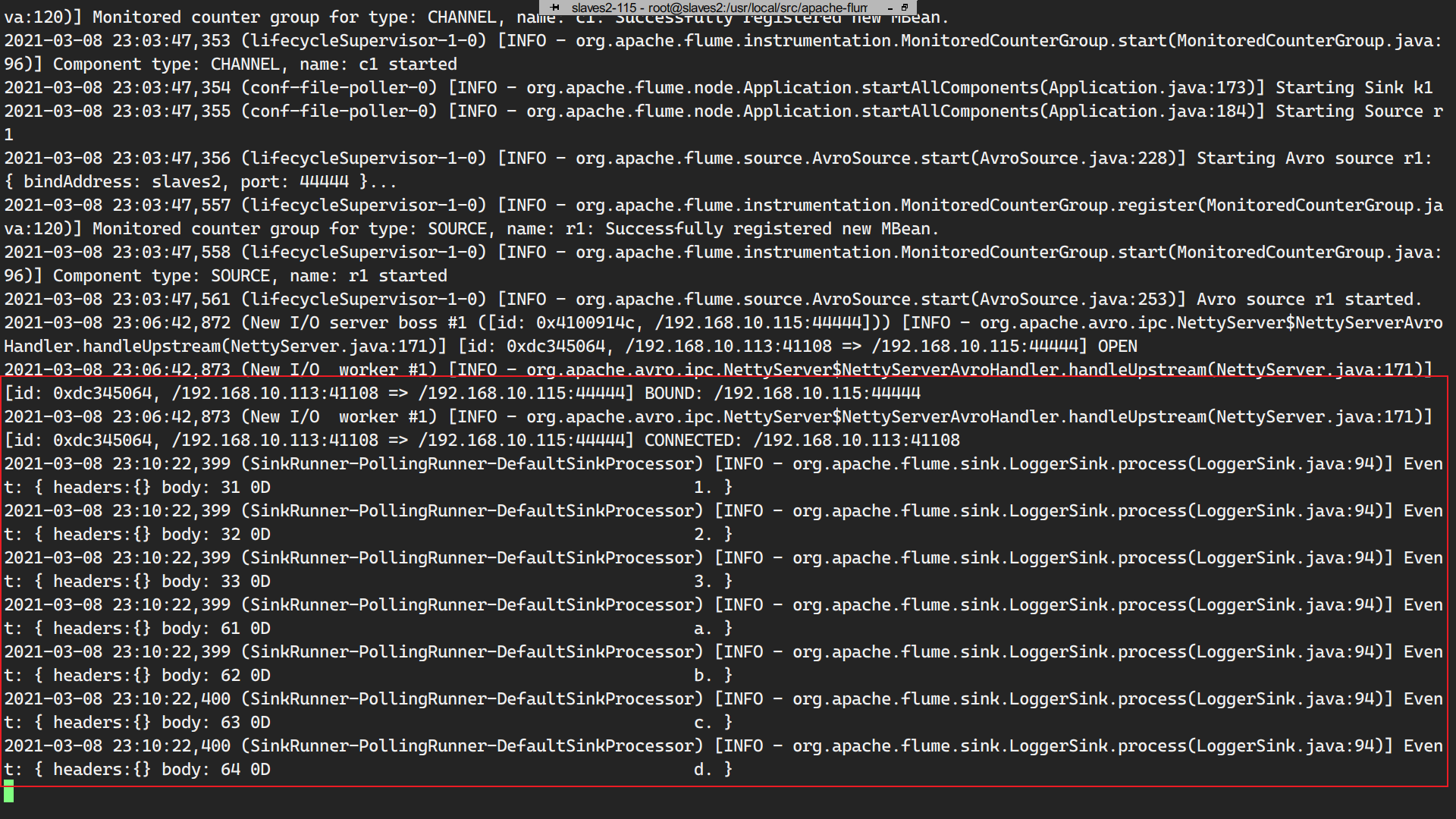
数据流转:
a.数据打印传输给第一个agent;—>b.第一个agent指定sink是slave2,最后数据传输到slave2的agent上。slave2获取数据时首先要连接到master。 —> c.数据从master传输到slave2上。
1 | 将文本中的a2全部替换(g)为a4 |
需求6:通过flume监控日志文件的变化,然后最终sink到logger
要监控的logger文件
1 | /usr/local/src/practice_code/flume/data/flume_exec_test.txt |
将其置为空值
1 | echo '' > /usr/local/src/practice_code/flume/data/flume_exec_test.txt |
运行flume_data_write.py,查看第一行输出结果:
1 | # -*- coding: utf-8 -*- |
1 | (py2) [root@main flume]# python flume_data_write.py |
main的flume配置文件flume_kafka.conf
1 | Name the components on this agent |
启动flume
1 | ./bin/flume-ng agent --conf conf --conf-file ./conf/flume_kafka.conf -name a1 -Dflume.root.logger=INFO,console |
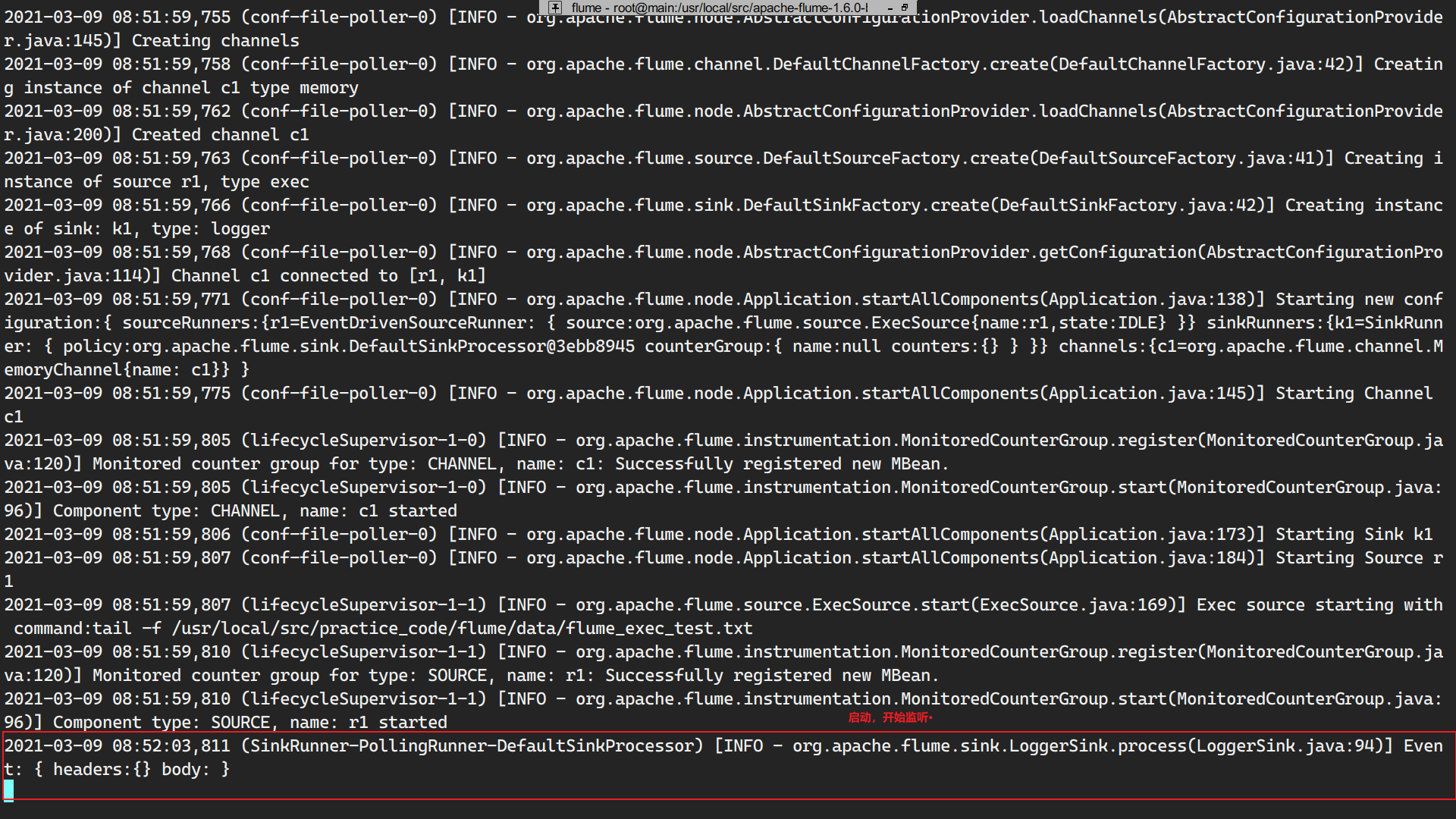
运行
1 | (py2) [root@main flume]# python flume_data_write.py |
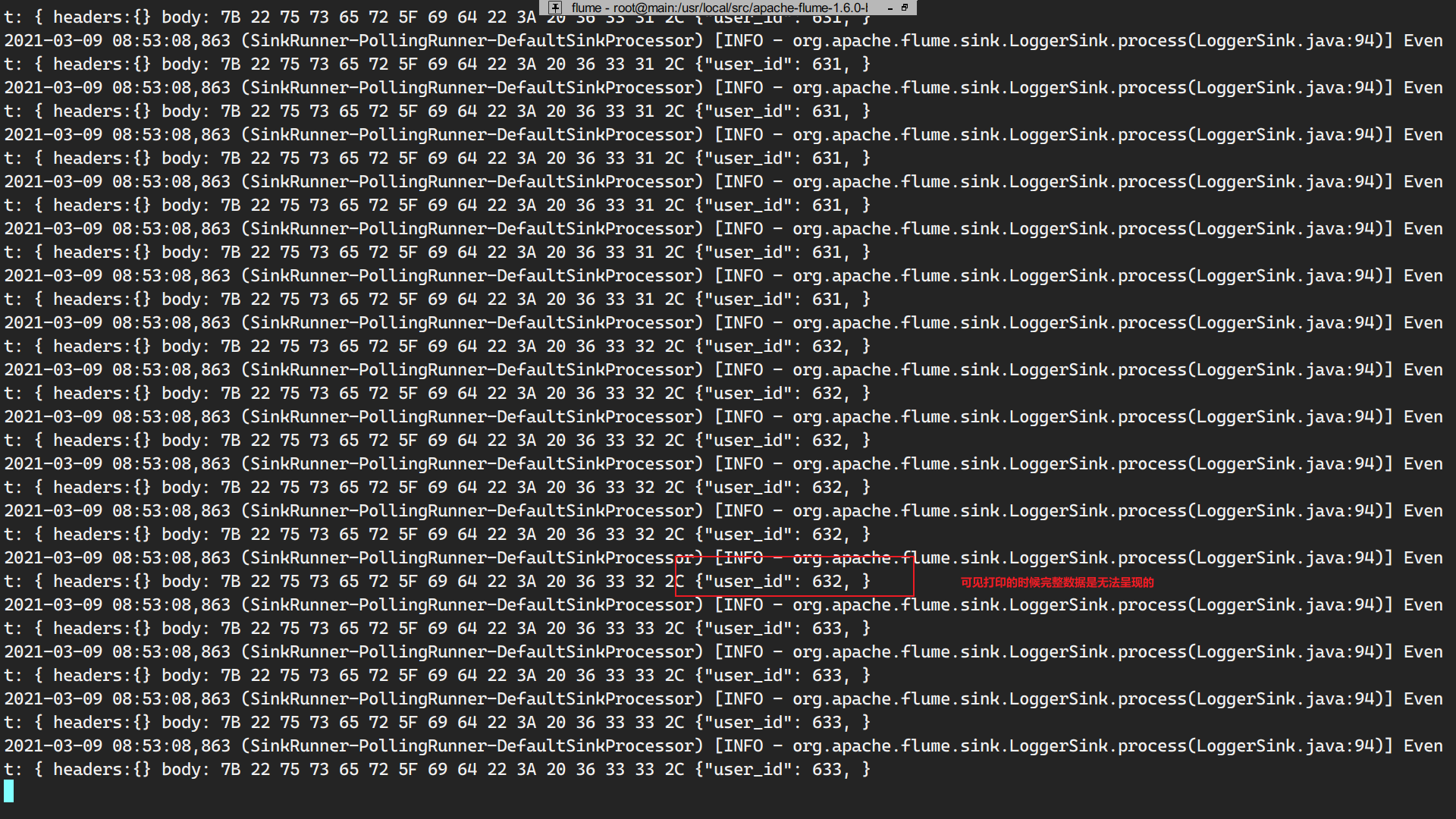
查看日志文件:
1 | (py2) [root@main flume]# head -2 data/flume_exec_test.txt |
通过pthon模拟实时写日志文件完成。
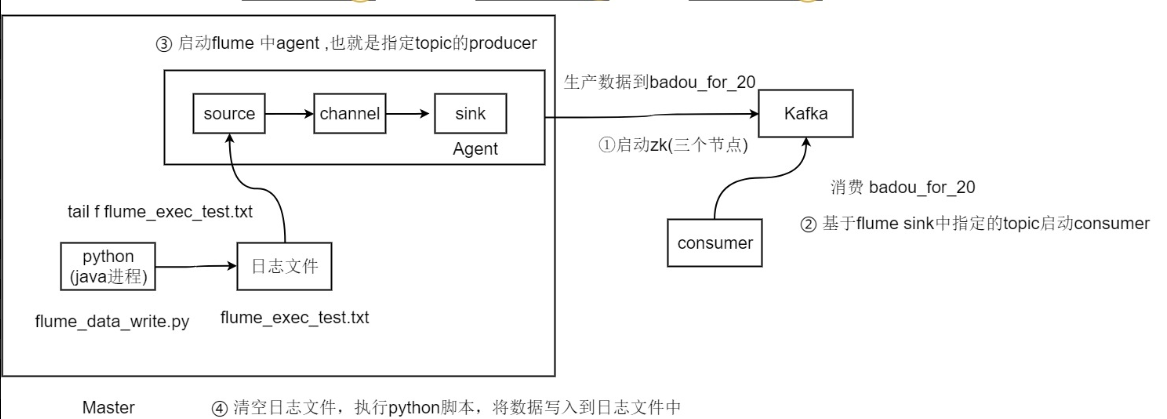
需求6:flume+kafka对接
flume和kafka对接需要先启动zookeeper。
1.在三个节点上启动zookeeper
1 | zkServer.sh start |
2.在后台(&)启动kafka
1 | (base) [root@main kafka_2.11-0.10.2.1]# ./bin/kafka-server-start.sh config/server.properties & |
查看后台运行进程
1 | (base) [root@main kafka_2.11-0.10.2.1]# jobs -l |
1 | 查看后台进程 |
查看端口号
1 | netstat -anp | grep 9092 |
查看kafka中的主题—topic
1 | (base) [root@main kafka_2.11-0.10.2.1]# ./bin/kafka-topics.sh --list --zookeeper localhost:2181 |
创建主题
1 | ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic badou_for_test |
1 | (base) [root@main kafka_2.11-0.10.2.1]# ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic badou_for_test |
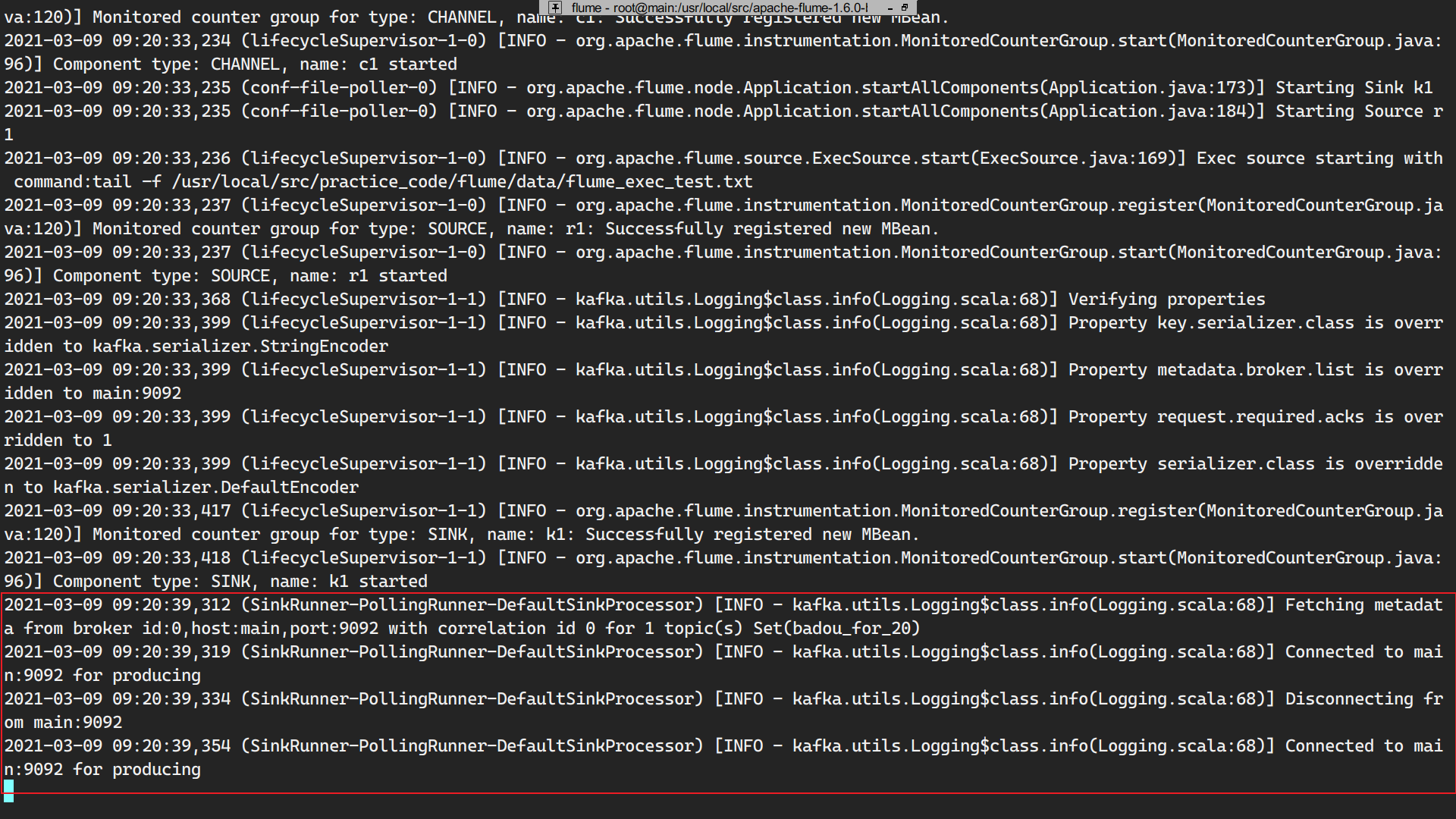
3.启动flume
修改flume配置文件
1 | Name the components on this agent |
消费badou_for_20 topic,没有消费就没有监听。
1 | ./bin/kafka-console-consumer.sh --zookeeper main:2181 --topic badou_for_20 --from-beginning |

启动flume
1 | ./bin/flume-ng agent --conf conf --conf-file ./conf/flume_kafka.conf -name a1 -Dflume.root.logger=INFO,console |
请空日志文件
1 | echo '' > /usr/local/src/practice_code/flume/data/flume_exec_test.txt |
写数据,consumer消费:
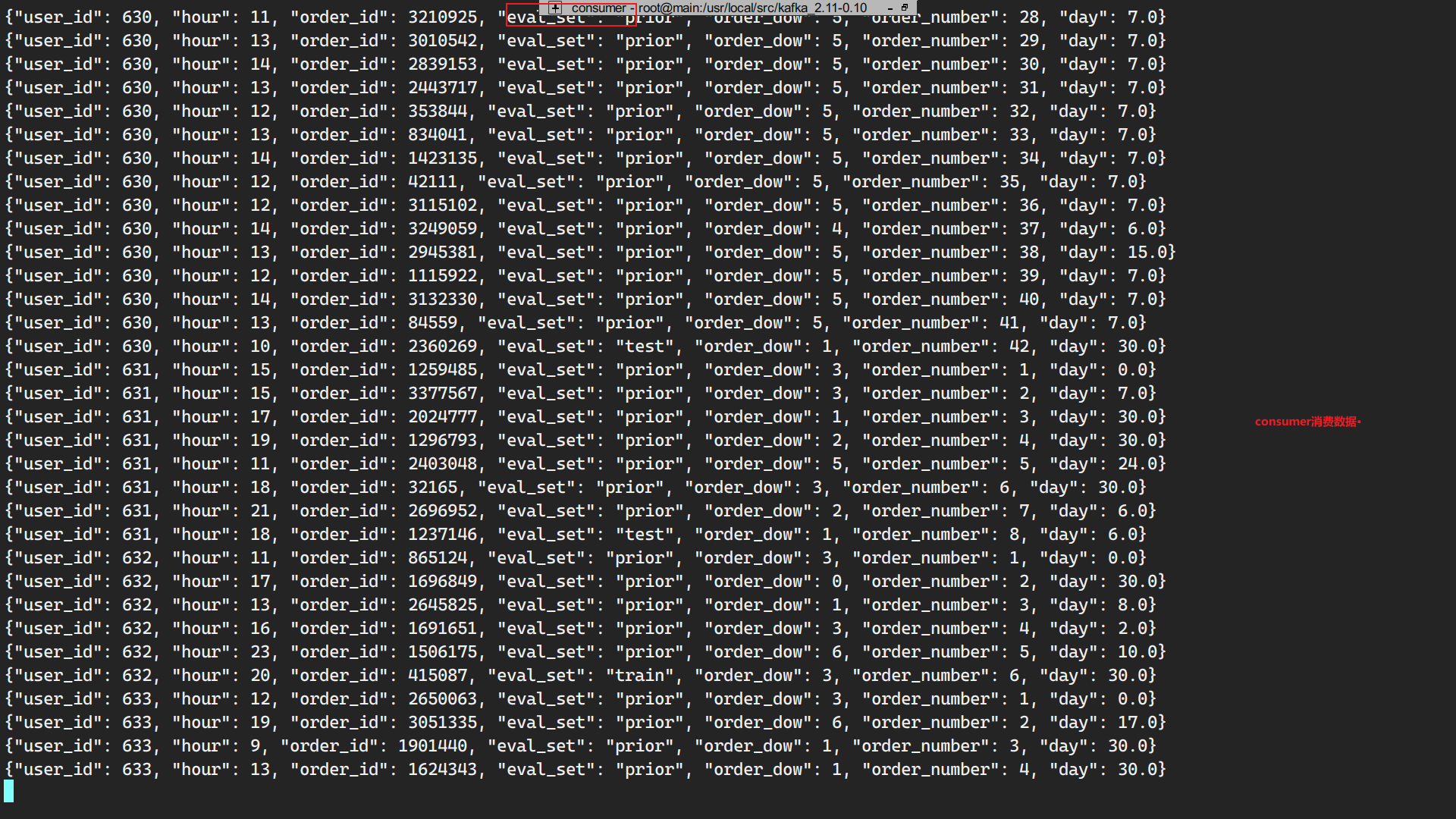
整体流程:
a.python 模拟java进程往日志文件写日志 —> b.flume通过exec(tail -f 日志文件)监控日志文件,一旦日志文件发生变化写入到source中—> c.sink对接到kafka—>d.kafka启动badou_for_20主题,消费agent往badou_for_20主题上发送的数据—>d.