大数据数据采集框架复盘—Flume Flume简介
Flume 是Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。 目前业界,大公司日常的业务数据量一般都能够达到PB级别,小公司也有TB级别。Flume是一个分布式的日志采集、数据收集框架,可以高效的从各个网站服务器中收集日志数据,并且存储到Hbase、HDFS中。
Flume组成架构
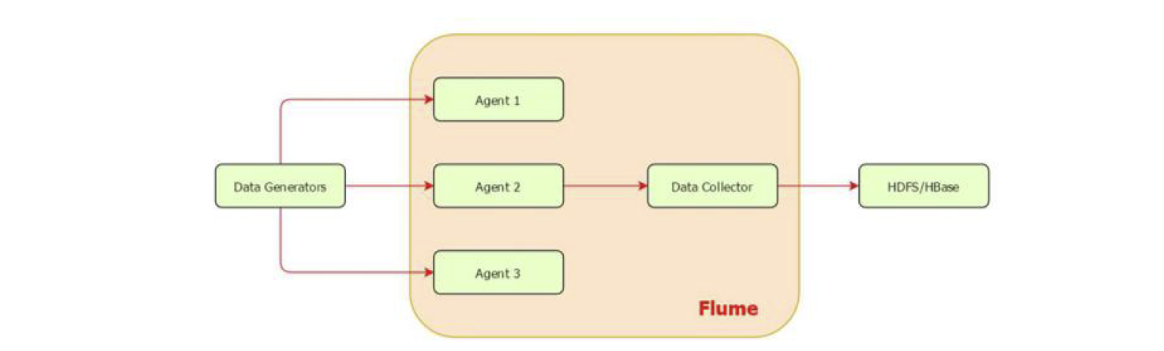
数据发生器(如: facebook, twitter)产生的数据被单个的运行在数据发生器所在服务器上的agent所收集,之后数据收容器从各个 agent上汇集数据并将采集到的数据存入到HDFS或者Hbase中。
agent是部署在一个服务器里的进程(JVM),负责收集该服务器产生的日志数据。
数据在Flume中的流转
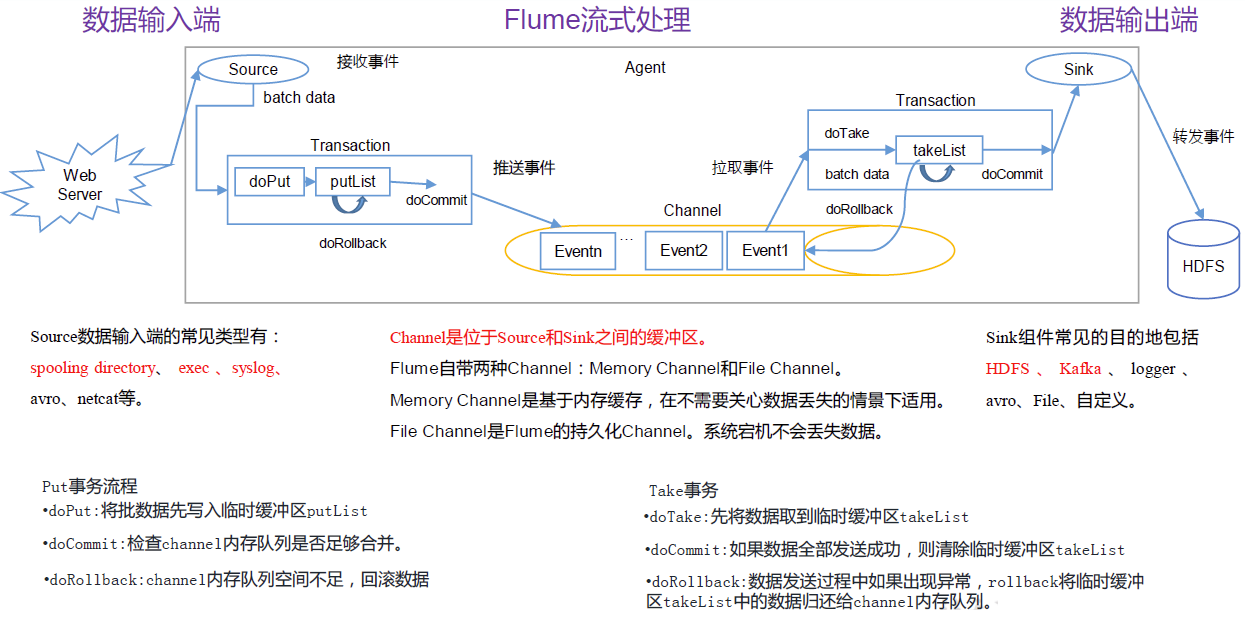
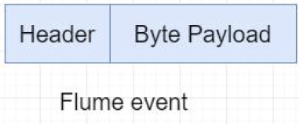
数据的单元 Flume数据的传输单元,Event对象是Flume 内部数据传输的最基本单元,以事件的形式将数据从源头送至目的地。它是由一个转载数据的字节数组+ー个可选头部构成 。
Event由零个或者多个 header(可以起到过滤作用)和正文body组成。Header是key/vaue形式的,可以用来制造路由决策或携带其他结构化信息(如事件的时间戳或事件来源的服务器主机名)。你可以把它想象成和HTTP头一样提供相同的功能一一通过该方法来传输正文之外的额外信息。Body是一个字节数组,包含了实际的内容。
数据的接入 数据是由部署在日志服务器上的Flume进程进行采集接入到Flume中的。这些被部署了Flume日志采集进程(Agent)的服务器在Flume内部称之为agent,Flume内部可以有多个agent,每一个agent都是运行了一个FLume的Agent独立守护进程(JVM)。
Flume从客户端或者其他agent接收数据,然后迅速的将获取的数据传输给下一个目的节点的agent。
Agent是Flume数据传输的基本单元。
Flume运行在数据采集服务器上的进程:Agent
运行了Flume数据采集进程的服务器:agent
数据的来源 Source是负责接收数据到Flume agent的组件,定义了采集的数据来源类型,位于agent中。
Source负责对接一个外部源(数据发生器),如一个web服务器传递给他的事件,该外部源将它的事件以 Flume可以识别的格式发送到Flume中,当一个 Flume源接收到一个事件时,其将通过一个或者多个通道存储该事件。
Source 组件可以处理各种类型、各种格式的日志数据,包括 console、PRC、Text、avro、thrift、exec、jms、spooling directory、netcat、sequence generator、 syslog、http、legacy。
关于Source处理的数据类型介绍: Avro Source Flume通过监听Avro 端口来接收外部avro客户端的事件流。
avro-source接收到的是经过avro序列化后的数据,然后反序列化数据继续传输。所以,如果是avro-source的话,源数据必须是经过avro序列化后的数据。利用 Avro source可以实现多级流动、扇出流、扇入流等效果。接收通过flume提供的avro客户端发送的日志信息。
Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。
它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。
作者:Albert陈凯https://www.jianshu.com/p/a5c0cbfbf608
Exec Source 可以将命令产生的输出作为源,例子:
1 a1.sources.r1.command=ping 192.168.234.163 要执行的命令
Taildir Source 监控指定的多个文件 ,一旦文件内有新写入的数据,就会将其写入到指定的sink内(断点续传 ),该来源可靠性高,不会丢失数据,建议使用,但目前不适用于Windows系统。
其不会对于跟踪的文件有任何处理,不会重命名也不会删除,不会做任何修改,这点比Spooling Source有优势,目前不支持读取二进制文件。
支持一行一行的读取文本文件。在实时数据处理中,可以用该方式取代Exec方式,因为本方式可靠性高。
此外,该数据源存在一个问题,当文件更名之后,会重新读取该文件,造成数据重复。解决方式有两种:(可参考实践案例:[[Flume TaildirSource重复读取实操]])
要使用不更名的打印日志框架(logback),有些日志打印框架会对日志数据文件进行归档,log4j就是,比如当天12点,将原本名为today.log改为yesterday.log
修改源码(flume-taildir-source-1.9.0.jar),让TailDirSource判断文件时只看iNode值
Spooling Directory Source 将指定的文件加入到“自动搜集”目录中。flume会持续监听这个目录,把文件当做source来处理。注意:一旦文件被放到“自动收集”目录中后,便不能修改,如果修改,flume会报错。此外,也不能有重名的文件,如果有,flume也会报错。
1 a1.sources.r1.spoolDir=/home/work/data 读取文件的路径,即"搜集目录"
Netcat Source 一个NetCat Source用来监听一个指定端口,并接端口收监听到的数据。
Kafka Source 支持从Kafka指定的topic中读取数据。
Sequence Generator Source —序列发生源 一个简单的序列发生器,不断的产生事件,值是从0开始每次递增1。主要用来测试。
Flume Source官方文档
Flume Source官方文档:http://flume.apache.org/FlumeUserGuide.html#flume-sources
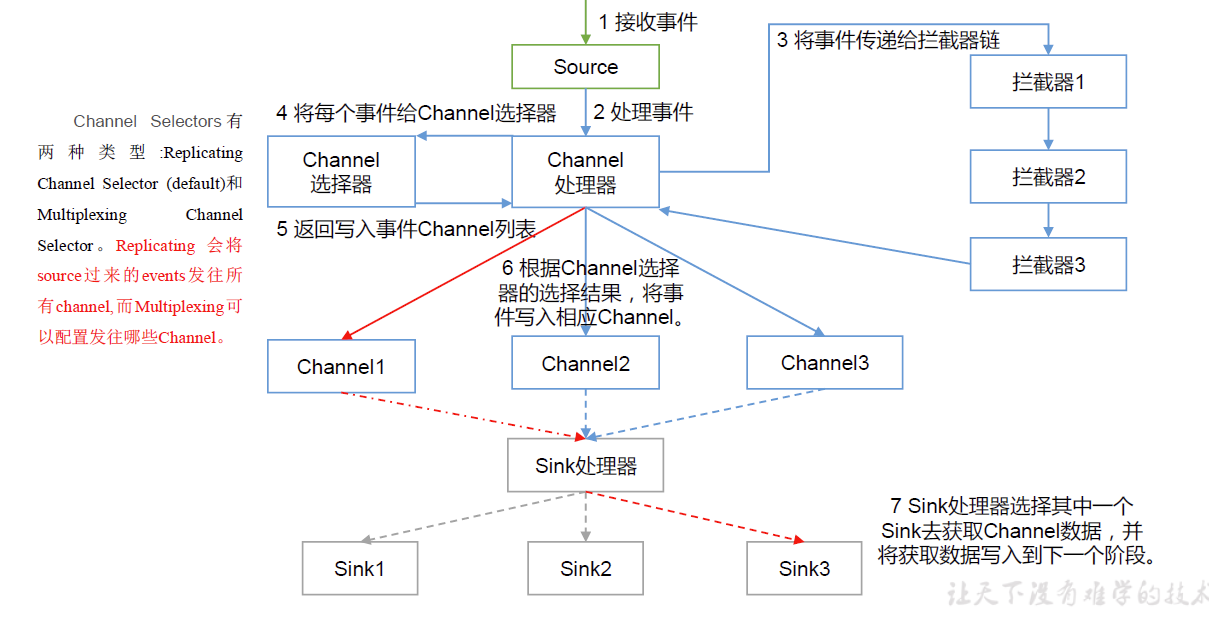
数据的传输 数据经过Flume Source采集进入agent内后,在Flume Channel内进行传输。
Flume Channel是Agent内用于传输的数据通道,位于Source和Sink之间的缓冲区,存储池,起缓存作用。它允许 Source 和Sink 运作在不同的速率上。
Channel 是线程安全的,可以同时处理几个Source 的写入操作和几个 Sink的读取操作。
Flume自带两种Channel:
Memory Channel
Memory Channel 是内存中的队列,内存存储事务,吞吐率极高,但存在丟数据风险。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel
File Channel,本地磁盘的事务实现模式,保证数据不会丟失(WAL实现) write ahead log,将所有事件写入到磁盘中。
Spillable Memory Channel
使用该内存作为channel,内存缓冲的数据超过了阈值就会将数据落盘。
Flume通常选择 File Channel,而不使用 Memory Channel。
此外,在Channel中,Flume在Channel中还实现了Interceptor(拦截器)和Selector(选择器)
Flume Channel Interceptor 位于Channel中,用于拦截指定的内容,一个channel里可以有多个拦截器进行重重过滤。
拦截器通过拦截event对应的header,从而达到对信息的过滤效果。
拦截器的分类:
Timestamp Interceptor 时间拦截器
Host Interceptor 主机名或者ip拦截器
Static Interceptor 静态拦截器
官方interceptor参考文档:http://flume.apache.org/FlumeUserGuide.html#flume-interceptors
Flume Channel Selector 一个agent里可以有多个channel。selector负责依据event的key值决定将数据传入到特定事件的channel。
选择器的分类:
Multiplexing Channel Selector
Replicating Channel Selector
会将Source过来的events发往所有的channel
官方selector参考文档:http://flume.apache.org/FlumeUserGuide.html#flume-channel-selectors
数据的输出 Flume Sink是数据传输的目标,将events输出到外部介质。Sink 不断地轮询Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Channel 启动一个事务(channel可以放到mysql,也可以放到kafka)。批量事件一旦成功写出到存储系统或下一个 Flume Agent,Sink 就利用Channel 提交事务。事务一旦被提交,该Channel 从自己的内部缓冲区删除事件。
Fluem Sink的分类:
HDFS Sink
Hive Sink
Logger Sink
Avoro Sink
Thrift Sink
IRC Sink
官方参考文档:http://flume.apache.org/FlumeUserGuide.html#flume-sinks
Flume内部数据流转总结
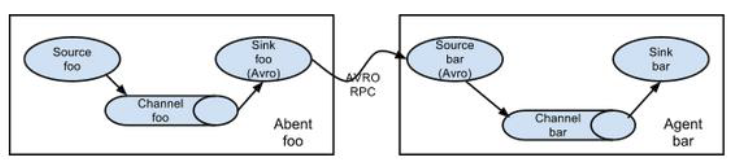
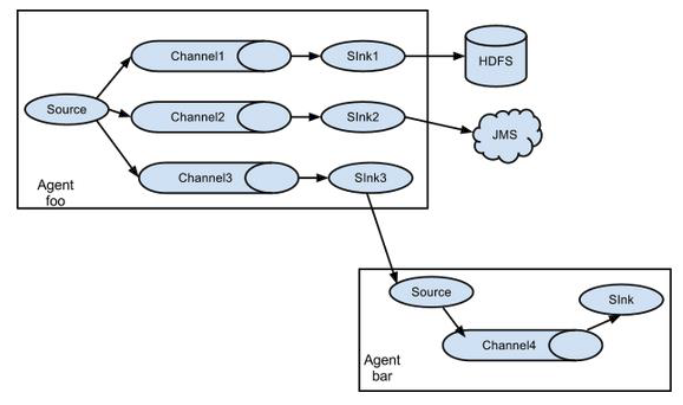
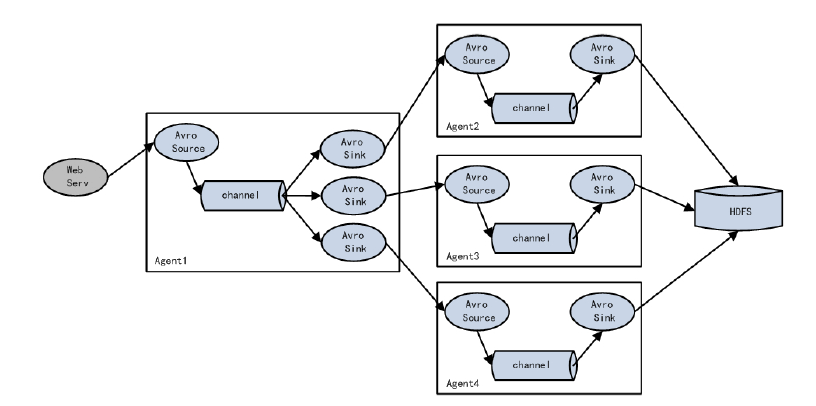
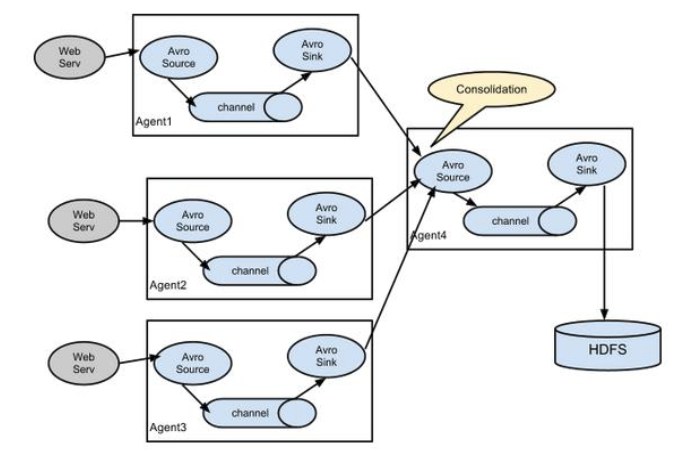
Flume的拓扑结构 这里主要介绍下Flume在日常的使用对接方式。
Flume的配置 Flume1.6.0的搭建 Hdoop3.1.3下Flume1.9.0的搭建—>[[数据仓库从0到1之日志采集平台搭建02]]
apache-flume-1.6.0-bin.tar.gz
wget http://mirror.bit.edu.cn/apache/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz
1 tar zxvf apache-flume-1.6.0-bin.tar.gz
2.进入flume根目录,在conf目录下配置Flume的配置文件(Flume配置文件主要放置在该目录下)
1 [root@main apache-flume-1.6.0-bin]
flume-netcat.conf配置文件内容:(这里主要是为了后续测试而配置的文件)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 # Name the components on this agent #a1:表示agent的名称 #r1:表示a1的输入源 #k1:表示a1的 输出目的地 #c1:表示a1的缓冲区 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat #表示a1的输入源类型为netcat端口类型 a1.sources.r1.bind = master #表示a1的监听的主机 a1.sources.r1.port = 44444 #表示监听a1的监听的端口号 # Describe the sink a1.sinks.k1.type = logger #表示a1的输出目的地是控制台logger类型 # Use a channel which buffers events in memory a1.channels.c1.type = memory #表示a1的channel类型是memory内存型 a1.channels.c1.capacity = 1000 #表示a1的channel总容量1000个event a1.channels.c1.transactionCapacity = 100 #表示a1的channel传输时收集到了100条event以后再去提交事务 # Bind the source and sink to the channel a1.sources.r1.channels = c1 #表示将r1和c1连接起来 a1.sinks.k1.channel = c1 #表示将k1和c1连接起来
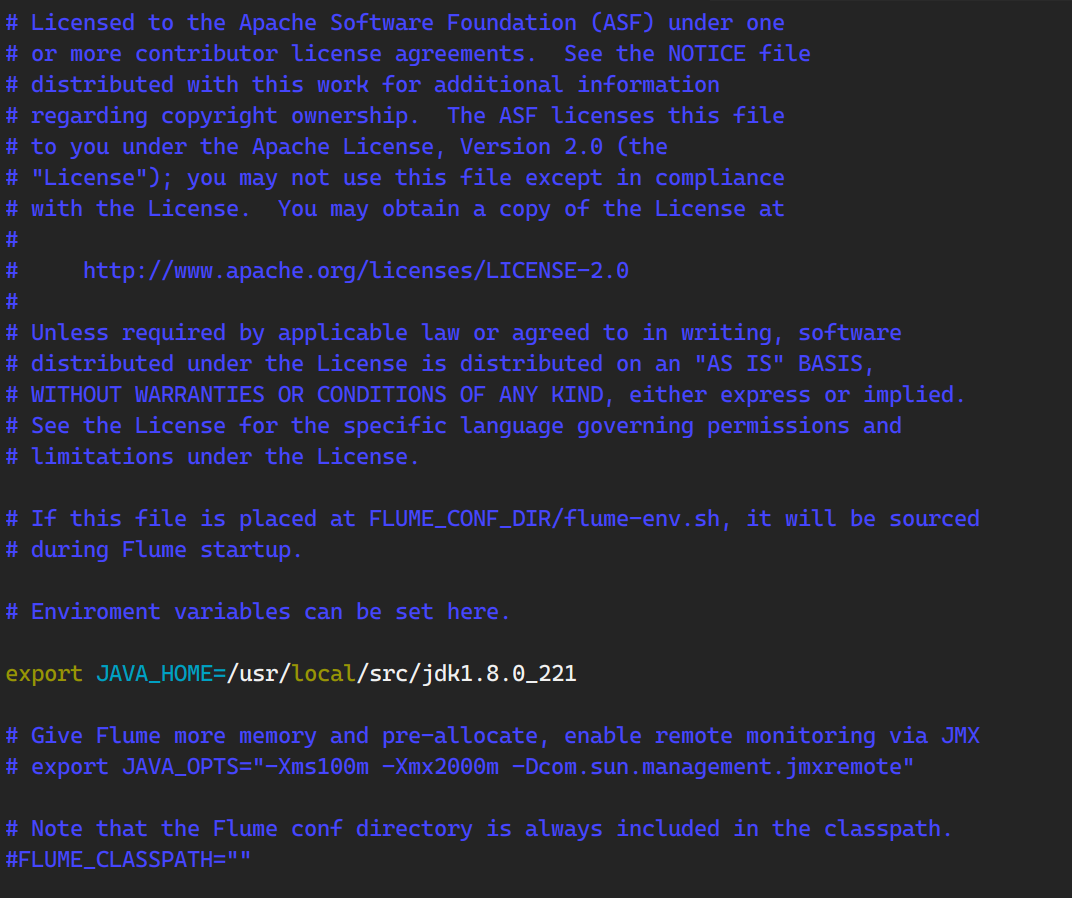
3.修改conf目录下的flume-env.sh.template文件
1 2 3 4 (base) [root@main conf] flume-conf.properties.template flume-env.ps1.template flume-env.sh.template flume-netcat.conf log4j.properties (base) [root@main conf] (base) [root@main conf]
找到JAVA_HOME,填上自己的JAVA_HOME路径。
4.安装telnet工具(master+slave1+slave2)
检验
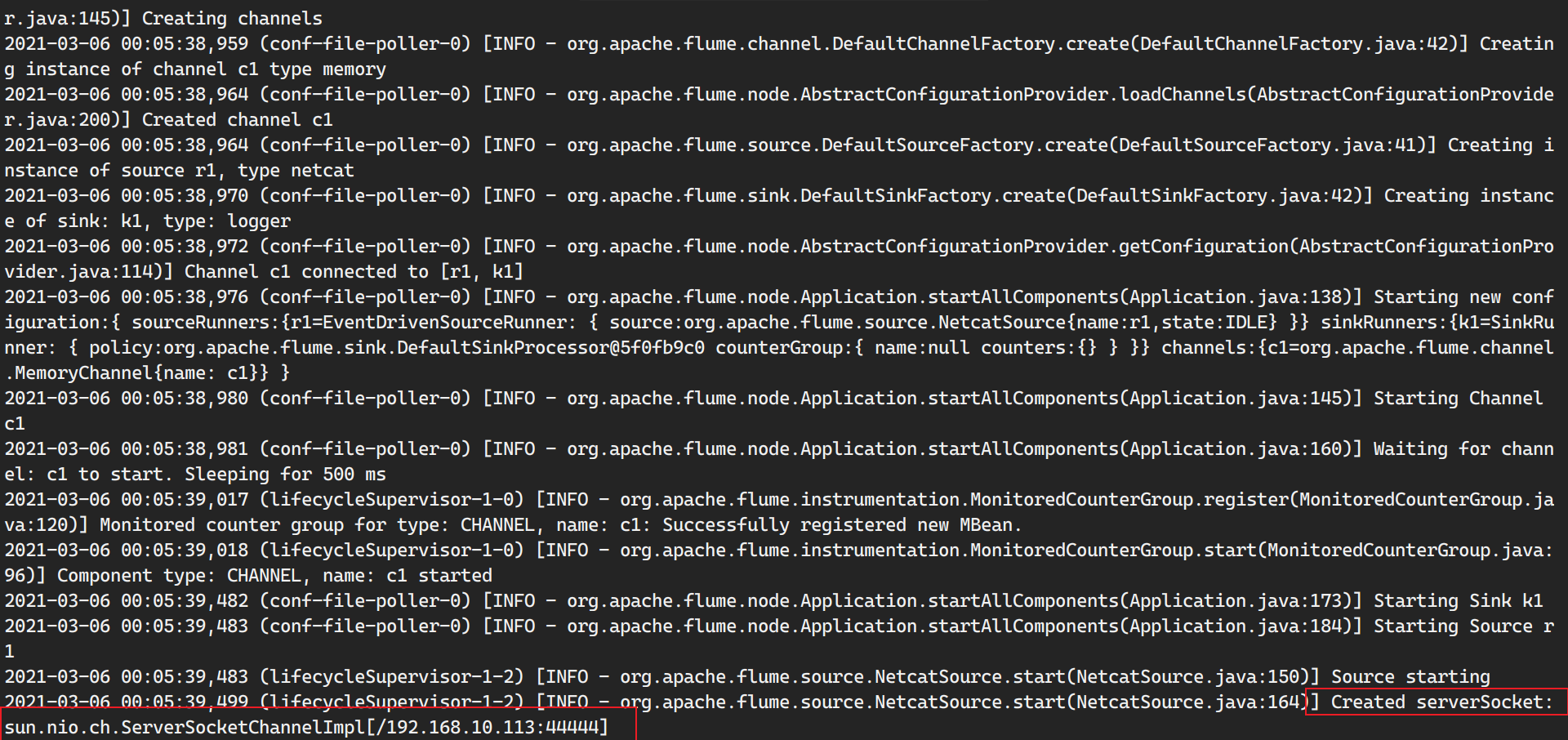
1 bin/flume-ng agent --conf conf --conf-file conf/flume-netcat.conf --name=agent -Dflume.root.logger=INFO,console
bin/flume-ng : Flume启动脚本
—conf conf or -c : 指定配置路径
—conf-file or -f : 指定Flume启动的配置文件
—name=agent or -n : 指定agent名称
-Dflume.root.logger=INFO,console : 配置日志信息打印到终端
2.使用telnet工具,从slave节点向master节点传递信息
1 2 3 4 [root@slaves1 ~]# telnet main 44444 Trying 192.168.10.113... Connected to main. Escape character is '^]'.
成功接受到信息。
后面的配置课程会有相关文件,到时直接copy配置文件即可。
Flume实践
netcat Source
它侦听给定的端口并将每一行文本转换为一个事件。 作用类似于 nc -k -l [host] [port]。 换句话说,它打开一个指定的端口并监听数据。 期望提供的数据是换行符分隔的文本。 每行文本都变成一个 Flume 事件并通过连接的通道发送。
案例一:netcat为source,sink为logger,配置拦截器拦截数值 1.编写配置文件:interceptor-number.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 # Name the components on this agent 针对agent重命名为a1 a1.sources = r1 # source别名为 r1 a1.sinks = k1 # sinks别名为 k1 a1.channels = c1 # channel别名为 c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # source定义正则匹配规则 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type =regex_filter a1.sources.r1.interceptors.i1.regex =^[0-9]*$ a1.sources.r1.interceptors.i1.excludeEvents =true # Describe/configure the channels a1.channels.c1.type = memory a1.channels.c1.capacity = 100 a1.channels.c1.transactionCapacity = 100 # Describe/configure the sink a1.sinks.k1.type = logger # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
2.启动flume
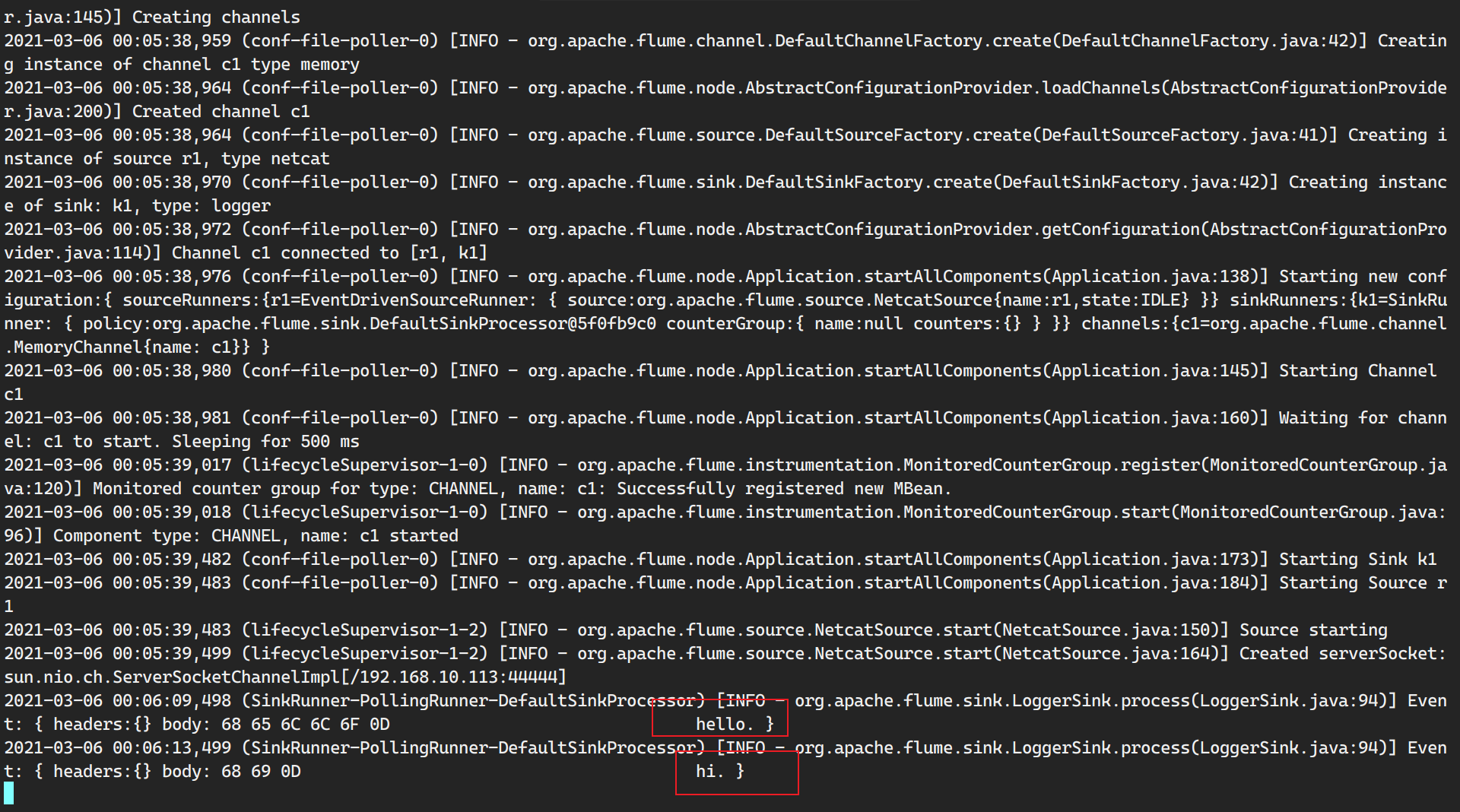
1 2 3 4 5 6 7 8 (base) [dw@hadoop116 flume]$ bin/flume-ng agent -n a1 -c conf/ -f jobs /interceptor-number.conf -Dflume.root.logger=INFO,console 2021-11-07 10:45:18,994 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type : CHANNEL, name: c1: Successfully registered new MBean. 2021-11-07 10:45:18,995 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type : CHANNEL, name: c1 started 2021-11-07 10:45:19,381 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:196)] Starting Sink k1 2021-11-07 10:45:19,382 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:207)] Starting Source r1 2021-11-07 10:45:19,383 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:155)] Source starting 2021-11-07 10:45:19,460 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
3.测试
注意:通过telnet连接可能会出现连接错误,多试几次就好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 (base) [dw@hadoop116 ~]$ telnet localhost 44444 Trying 127.0.0.1... Connected to localhost. Escape character is '^]' . a12b OK 123 OK abc OK 456 OK test OK
flume输出:
1 2 3 4 2021-11-07 10:45:19,460 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444] 2021-11-07 10:47:25,448 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 61 31 32 62 0D a12b. } 2021-11-07 10:47:34,460 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 61 62 63 0D abc. } 2021-11-07 10:47:37,044 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 74 65 73 74 0D test . }
结论:
flume过滤掉了数字,保留了英文字母消息。
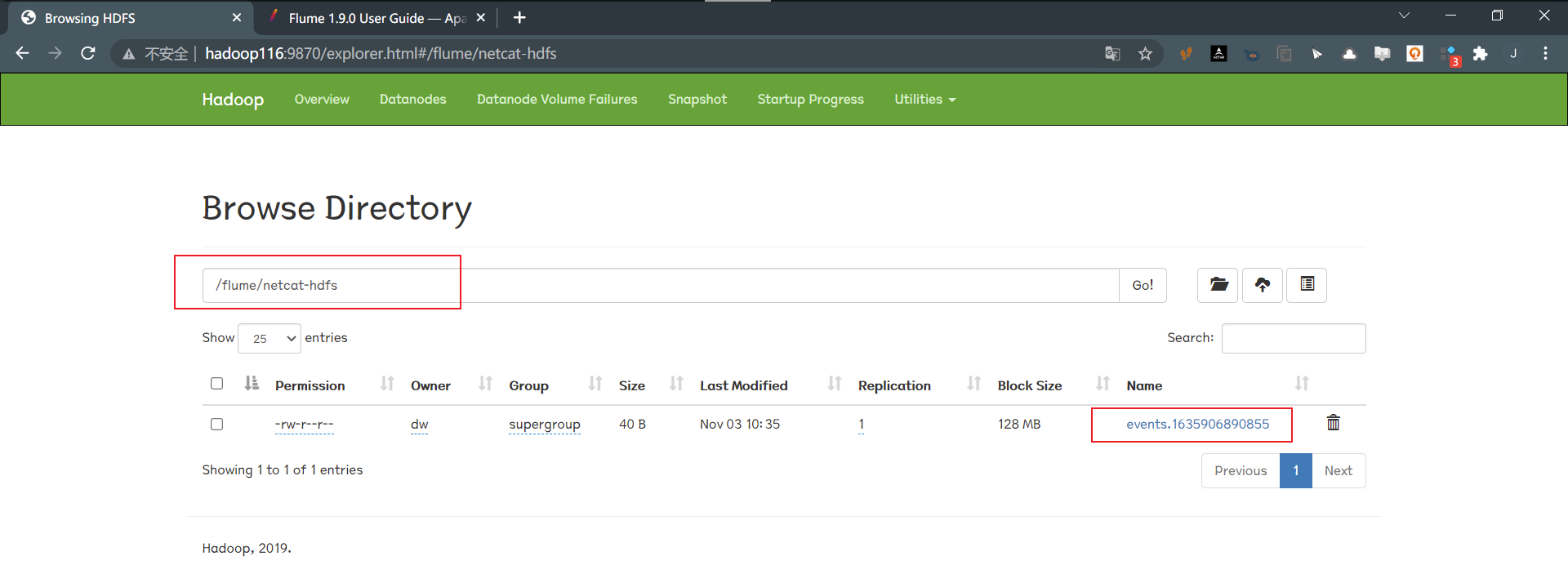
案例二:通过netcat作为source,sink到hdfs 1.编写配置文件:netcat-hdfs.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 ## source config # a1的输入源类型是netcat端口类型 a1.sources.r1.type = netcat # a1监听的主机 填localhost也行 a1.sources.r1.bind = hadoop116 # a1监听的端口号 a1.sources.r1.port = 44444 ## channel config a1.channels.c1.type = memory # 表示a1的channel总容量1000个event a1.channels.c1.capacity = 1000 #表示a1的channel传输时收集到了100条event以后再去提交事务 a1.channels.c1.transactionCapacity = 100 ## sink config a1.sinks.k1.type = hdfs # 数据存储的hdfs路径 a1.sinks.k1.hdfs.path = hdfs:/flume/netcat-hdfs # 表示最终落盘的文件前缀 a1.sinks.k1.hdfs.filePrefix = events # 表示到需要触发的时间时,是否要更新文件夹,true表示是 a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 # 表示切换时间的单位是分钟 a1.sinks.k1.hdfs.roundUnit = minute # 表示过1mins生产一个文件 a1.sinks.k1.hdfs.roundInterval = 60 # 文件格式:目前 SequenceFile、DataStream 或 CompressedStream (1)DataStream 不会压缩输出文件,请不要设置 codeC (2)CompressedStream 需要使用可用的 codeC 设置 hdfs.codeC a1.sinks.k1.hdfs.fileType = DataStream ## Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
2.启动Flume:
1 2 3 4 5 (base) [dw@hadoop116 flume]$ bin/flume-ng agent -c conf/ -n a1 -f jobs /netcat-hdfs.conf -Dflume.root.logger=INFO,console or (base) [dw@hadoop116 flume]$ bin/flume-ng agent --conf conf/ -name a1 --conf-file jobs /netcat-hdfs.conf -Dflume.root.logger=INFO,console
1 2 3 4 5 6 7 8 9 10 11 12 2021-11-03 10:33:30,244 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:120)] Channel c1 connected to [r1, k1] 2021-11-03 10:33:30,250 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:162)] Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source :org.apache.flume.source.NetcatSource{name:r1,state:IDLE} }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@615f64d1 counterGroup:{ name:null counters:{} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} } 2021-11-03 10:33:30,253 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:169)] Starting Channel c1 2021-11-03 10:33:30,254 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:184)] Waiting for channel: c1 to start. Sleeping for 500 ms 2021-11-03 10:33:30,353 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type : CHANNEL, name: c1: Successfully registered new MBean. 2021-11-03 10:33:30,353 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type : CHANNEL, name: c1 started 2021-11-03 10:33:30,755 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:196)] Starting Sink k1 2021-11-03 10:33:30,756 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:207)] Starting Source r1 2021-11-03 10:33:30,757 (lifecycleSupervisor-1-2) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type : SINK, name: k1: Successfully registered new MBean. 2021-11-03 10:33:30,757 (lifecycleSupervisor-1-2) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type : SINK, name: k1 started 2021-11-03 10:33:30,757 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:155)] Source starting 2021-11-03 10:33:30,777 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/192.168.10.116:44444]
3.telnet向监听端口传入数据
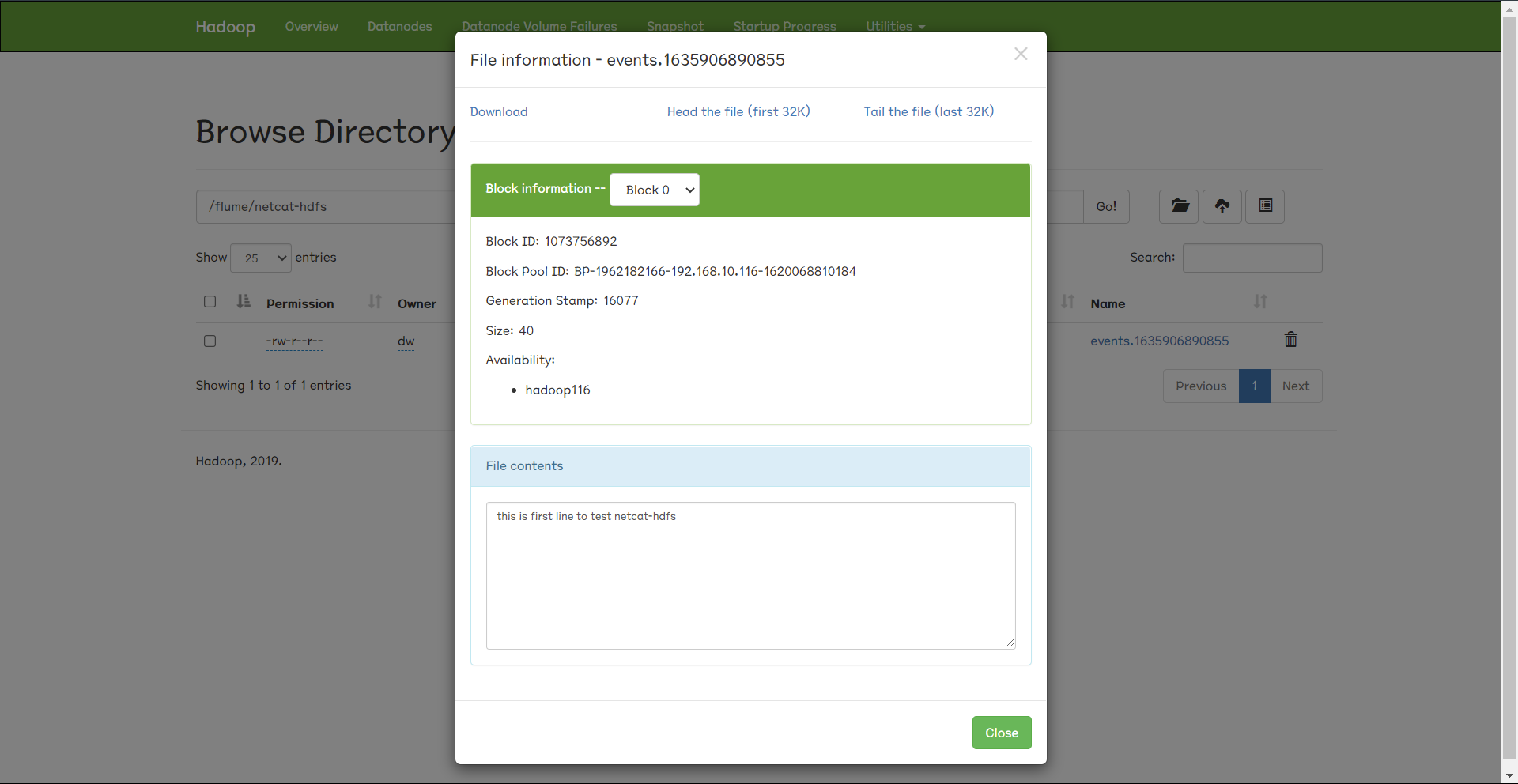
1 2 3 4 5 6 (base) [dw@hadoop116 ~]$ telnet hadoop116 44444 Trying 192.168.10.116... Connected to hadoop116. Escape character is '^]' . this is first line to test netcat-hdfs OK
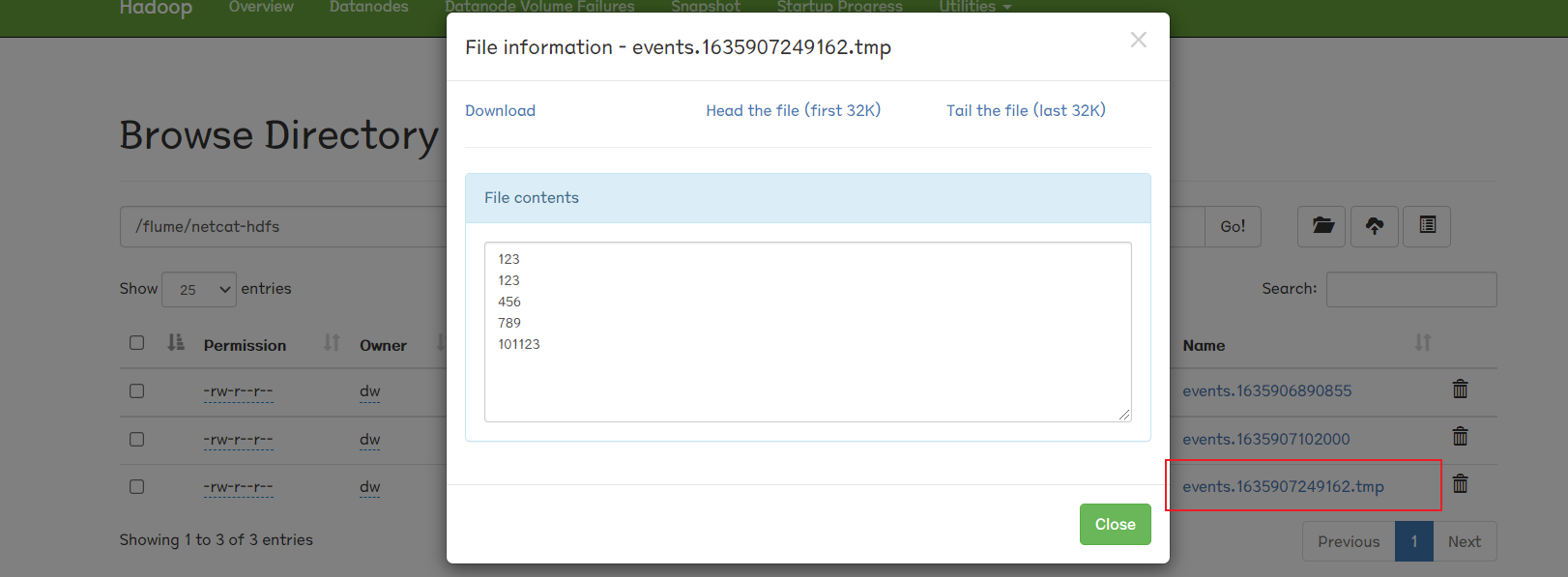
4.查看hdfs页面
文件生成
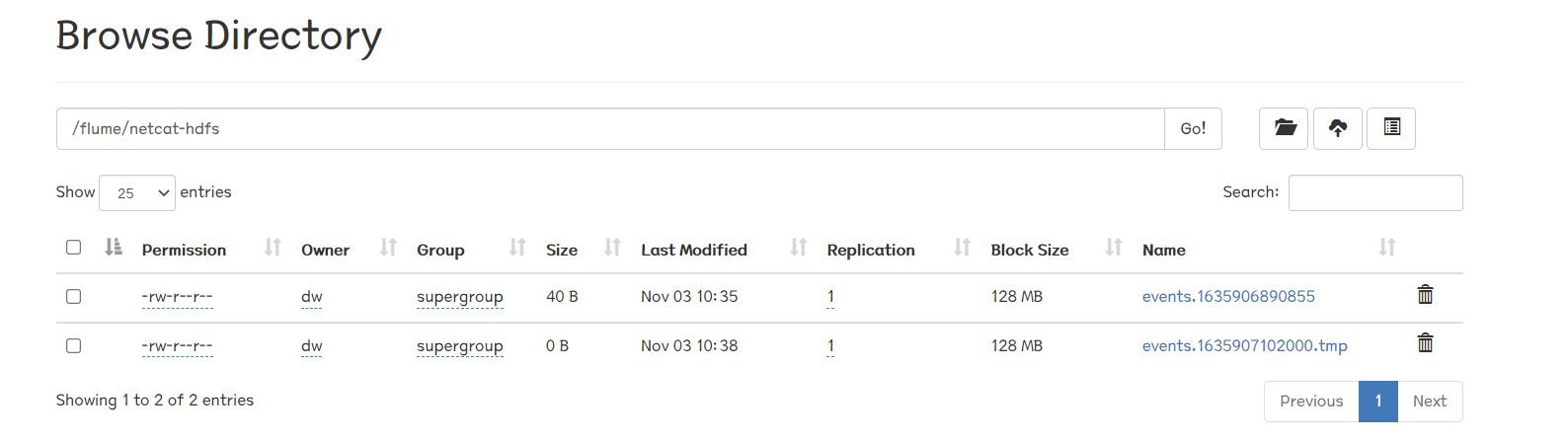
注意这里的tmp,因为我们前面设置了
1 2 # 表示过1mins生产一个文件 a1.sinks.k1.hdfs.roundInterval = 60
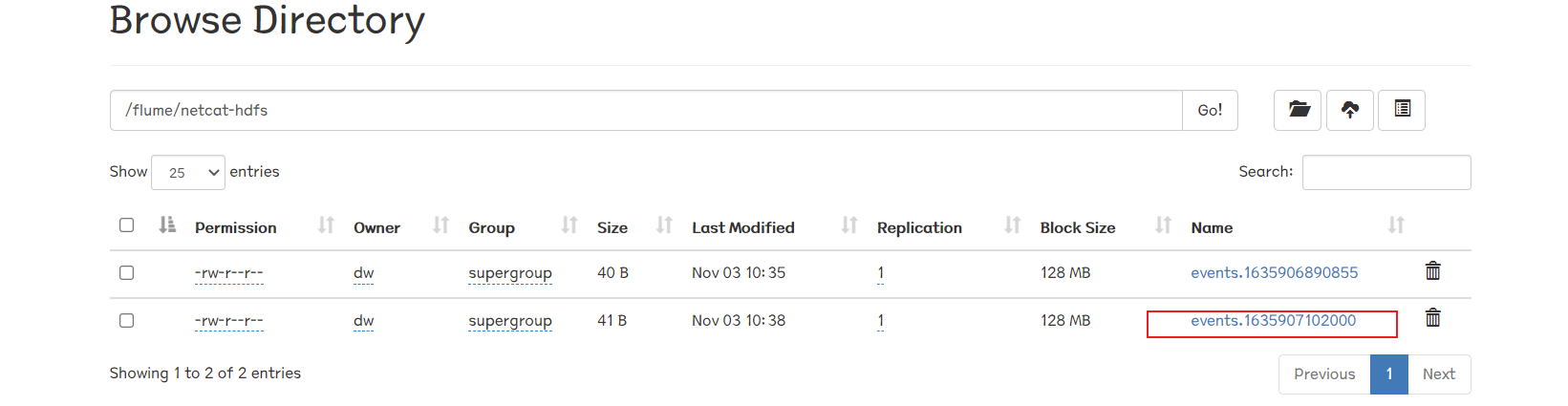
所以要到一分钟后该文件才从tmp转为正式文件:
这里我们尝试在1mins内输入多行:
1 2 3 4 5 6 7 8 9 10 11 OK 123 OK 123 OK 456 OK 789 OK 101123 OK
拓展:小文件问题 这里存在小文件问题,如何设置flume防止小文件?
1.在配置文件里配置roll.size,限定一个文件里存储多大的数据。
1 a1.sinks.k1.hdfs.rollSize = 200*1024*1024
2.限定文件可以存储多少个event
1 a1.sinks.k1.hdfs.rollCount = 10000
案例三:通过http作为source, sink写到logger 1.编写配置文件:http-logger.conf:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = org.apache.flume.source.http.HTTPSource a1.sources.r1.bind = hadoop116 a1.sources.r1.port = 50020 #a1.sources.r1.fileHeader = true # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
2.启动Flume
1 (base) [dw@hadoop116 flume]$ bin/flume-ng agent -n a1 -c conf/ -f jobs /http-logger.conf -Dflume.root.logger=INFO,console
3.测试http Source的结果:
发送json数据:
1 (base) [dw@hadoop116 ~]$ curl -X POST -d '[{"headers" : {"timestamp" : "434324343","host" : "random_host.example.com"},"body" : "random_body"},{"headers" : {"namenode" : "namenode.example.com","datanode" : "random_datanode.example.com"},"body" : "badou,badou"}]' hadoop116:44444
Flume输出结果:
1 2 2021-11-07 11:14:40,242 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{host=random_host.example.com, timestamp=434324343} body: 72 61 6E 64 6F 6D 5F 62 6F 64 79 random_body } 2021-11-07 11:14:40,242 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{namenode=namenode.example.com, datanode=random_datanode.example.com} body: 62 61 64 6F 75 2C 62 61 64 6F 75 badou,badou }
案例四:通过flume监控日志文件的变化,然后最终sink到logger 1.配置要监控的文件
1 2 3 4 5 (base) [dw@hadoop116 flume]$ mkdir data (base) [dw@hadoop116 flume]$ touch flume_exe_test.txt (base) [dw@hadoop116 flume]$ touch data/flume_exe_test.txt (base) [dw@hadoop116 flume]$ ls data/ flume_exe_test.txt
2.编写数据发生脚本:flume_data_produce.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import randomimport timeimport pandas as pdimport jsonwriteFileName = "/opt/module/flume/data/flume_exe_test.txt" def generate_js (): data_dict = { "order_id" : [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ], "user_id" : [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ], "eval_set" : [101 , 110 , 100 , 201 ], "order_number" : [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ], "order_dow" : [0 , 1 , 2 , 3 , 4 , 5 , 6 ], "hour" : [0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 , 13 , 14 , 15 , 16 , 17 , 18 , 19 , 20 , 21 , 22 , 23 ], "day" : [0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 , 13 , 14 , 15 , 16 , 17 , 18 , 19 , 20 , 21 , 22 , 23 , 24 , 25 , 26 , 27 , 28 , 29 ] } datad = {} for col in data_dict: datad[col] = data_dict[col][random.randint(0 , len (data_dict[col]) - 1 )] data_js = json.dumps(datad) return data_js def generate_data (rows ): with open (writeFileName, 'a+' ) as wf: for i in range (rows): wf.write(generate_js() + '\n' ) if __name__ == "__main__" : generate_data(15 )
3.编写flume配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = exec # 要观察的日志文件 a1.sources.r1.command = tail -f /opt/module/flume/data/flume_exe_test.txt # Describe/configure the sinks a1.sinks.k1.type = logger # Describe/configure the channels a1.channels.c1.type = memory a1.channels.c1.capacity = 100 a1.channels.c1.transcationCapacity = 1000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
4.启动flume
1 2 3 4 5 6 7 8 9 (base) [dw@hadoop116 flume]$ bin/flume-ng agent -n a1 -c conf/ -f jobs /flume_monitor_log.conf -Dflume.root.logger=INFO,console 2021-11-07 13:02:37,867 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type : CHANNEL, name: c1: Successfully registered new MBean. 2021-11-07 13:02:37,868 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type : CHANNEL, name: c1 started 2021-11-07 13:02:38,275 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:196)] Starting Sink k1 2021-11-07 13:02:38,276 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:207)] Starting Source r1 2021-11-07 13:02:38,277 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.ExecSource.start(ExecSource.java:170)] Exec source starting with command : tail -f /opt/module/flume/data/flume_exe_test.txt 2021-11-07 13:02:38,280 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type : SOURCE, name: r1: Successfully registered new MBean. 2021-11-07 13:02:38,280 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type : SOURCE, name: r1 started
5.运行python脚本,查看flume输出
1 2 3 (base) [dw@hadoop116 data]$ ./flume_data_produce.py (base) [dw@hadoop116 data]$
Flume输出(打印的时候不会打印完整的数据):
1 2 3 2021-11-07 13:03:34,205 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 7B 22 6F 72 64 65 72 5F 69 64 22 3A 20 31 2C 20 {"order_id" : 1, } 2021-11-07 13:03:38,405 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 7B 22 6F 72 64 65 72 5F 69 64 22 3A 20 32 2C 20 {"order_id" : 2, } 2021-11-07 13:03:38,405 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 7B 22 6F 72 64 65 72 5F 69 64 22 3A 20 35 2C 20 {"order_id" : 5, }
案例五:agent串联传输 1.主节上部署Source、Channel,从节点作为sink,编写配置文件push.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #Name the components on this agent a1.sources= r1 a1.sinks= k1 a1.channels= c1 #Describe/configure the source a1.sources.r1.type= netcat a1.sources.r1.bind= localhost a1.sources.r1.port = 44444 #Use a channel which buffers events in memory a1.channels.c1.type= memory a1.channels.c1.keep-alive= 10 a1.channels.c1.capacity= 100000 a1.channels.c1.transactionCapacity= 100000 #Describe/configure the source a1.sinks.k1.type= avro a1.sinks.k1.hostname= hadoop117 a1.sinks.k1.port= 44444 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel= c1
2.在从节点hadoop117上配置pull.conf文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #Name the components on this agent a2.sources= r1 a2.sinks= k1 a2.channels= c1 #Describe/configure the source a2.sources.r1.type= avro a2.sources.r1.bind= hadoop117 a2.sources.r1.port= 44444 #Describe the sink a2.sinks.k1.type= logger #Use a channel which buffers events in memory a2.channels.c1.type= memory a2.channels.c1.keep-alive= 10 a2.channels.c1.capacity= 100000 a2.channels.c1.transactionCapacity= 100000 # Bind the source and sink to the channel a2.sources.r1.channels= c1 a2.sinks.k1.channel = c1
3.先启动hadoop117上的flume,因为如果先启动主节点的flume,他会尝试去连接从节点,结果就是从节点端口还没开启而报错。
1 2 3 4 5 6 7 [dw@hadoop117 flume]$ bin/flume-ng agent -n a2 -c conf/ -f jobs /pull.conf -Dflume.root.logger=INFO,console 2021-11-07 13:15:05,968 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:193)] Starting Avro source r1: { bindAddress: hadoop117, port: 44444 }... 2021-11-07 13:15:06,415 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type : SOURCE, name: r1: Successfully registered new MBean. 2021-11-07 13:15:06,415 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type : SOURCE, name: r1 started 2021-11-07 13:15:06,417 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:219)] Avro source r1 started.
4.再启动主节点上的flume:
1 2 3 4 5 (base) [dw@hadoop116 flume]$ bin/flume-ng agent -n a1 -c conf/ -f jobs /push.conf -Dflume.root.logger=INFO,console 2021-11-07 13:16:51,186 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444] 2021-11-07 13:16:51,499 (lifecycleSupervisor-1-2) [INFO - org.apache.flume.sink.AbstractRpcSink.start(AbstractRpcSink.java:308)] Rpc sink k1 started.
5.在主节点上通过telnet传输数据测试:
1 2 3 4 5 6 7 8 (base) [dw@hadoop116 data]$ telnet localhost 44444 Trying ::1... telnet: connect to address ::1: Connection refused Trying 127.0.0.1... Connected to localhost. Escape character is '^]' . this is the test for agent-agent-flume OK
6.检验从节点的flume
1 2 3 4 2021-11-07 13:16:51,236 (New I/O server boss 2021-11-07 13:16:51,237 (New I/O worker 2021-11-07 13:16:51,237 (New I/O worker 2021-11-07 13:18:26,020 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 74 68 69 73 20 69 73 20 74 68 65 20 74 65 73 74 this is the test }
Flume的优化 下次一定!