HiveQL行列转换以及开窗函数案例
HiveQL行列转换以及开窗函数案例
列和字段属性转换练习
该表是用户订单表,请统计各用户一周内各天的订单数。orders.order_dow列用数字表示一周内的第几天。
| orders.order_id | orders.user_id | orders.eval_set | orders.order_number | orders.order_dow | orders.order_hour_of_day | orders.days_since_prior_order |
|---|---|---|---|---|---|---|
| 2539329 | 1 | prior | 1 | 2 | 08 | |
| 2398795 | 1 | prior | 2 | 3 | 07 | 15.0 |
| 473747 | 1 | prior | 3 | 3 | 12 | 21.0 |
| 2254736 | 1 | prior | 4 | 4 | 07 | 29.0 |
| 431534 | 1 | prior | 5 | 4 | 15 | 28.0 |
方法一:
1 | select |
方法二:
1 | select |
结果:
1 | user_id dow0 dow1 dow2 dow3 dow4 dow5 dow6 |
行列转换
concat_ws 行转列
求出用户一周内各天下单的订单有哪些。
| orders.order_id | orders.user_id | orders.eval_set | orders.order_number | orders.order_dow | orders.order_hour_of_day | orders.days_since_prior_order |
|---|---|---|---|---|---|---|
| 2539329 | 1 | prior | 1 | 2 | 08 | |
| 2398795 | 1 | prior | 2 | 3 | 07 | 15.0 |
| 473747 | 1 | prior | 3 | 3 | 12 | 21.0 |
| 2254736 | 1 | prior | 4 | 4 | 07 | 29.0 |
| 431534 | 1 | prior | 5 | 4 | 15 | 28.0 |
1 | select |
结果:
1 | user_id order_dow orders_set |
列转行
用之前列转行的结果创建一个测试表进行转列测试。
1 | hive> create table orders_cp as select |
1 | hive> select * from orders_cp limit 5; |
列转行:
lateral view用于和split、explode等UDTF一起使用,它能够将一列数据拆分成多行数据,在此基础上可以对拆分后的数据进行聚合。
1 | select |
1 | hive> select |
开窗函数练习
普通的聚合函数聚合的行集是组,开窗函数聚合的行集是窗口。因此,普通的聚合函数每组(Group By)只返回一个值,而开窗函数则可为窗口的每行都返回一个值。简单理解,就是对查询的结果多出一列,这一列可以是聚合值,也可以是排序值。
开窗函数分为聚合开窗函数和排序开窗函数。
我们在这里创建一个公司-员工-薪资表来充当数据测试集,数据来自当下传的比较火的互联网公司时薪表:
1 | hive> CREATE table company_stuff_salary( |
聚合开窗函数
Count开窗函数案例
1 | select *, |
1 | 对于count1: |
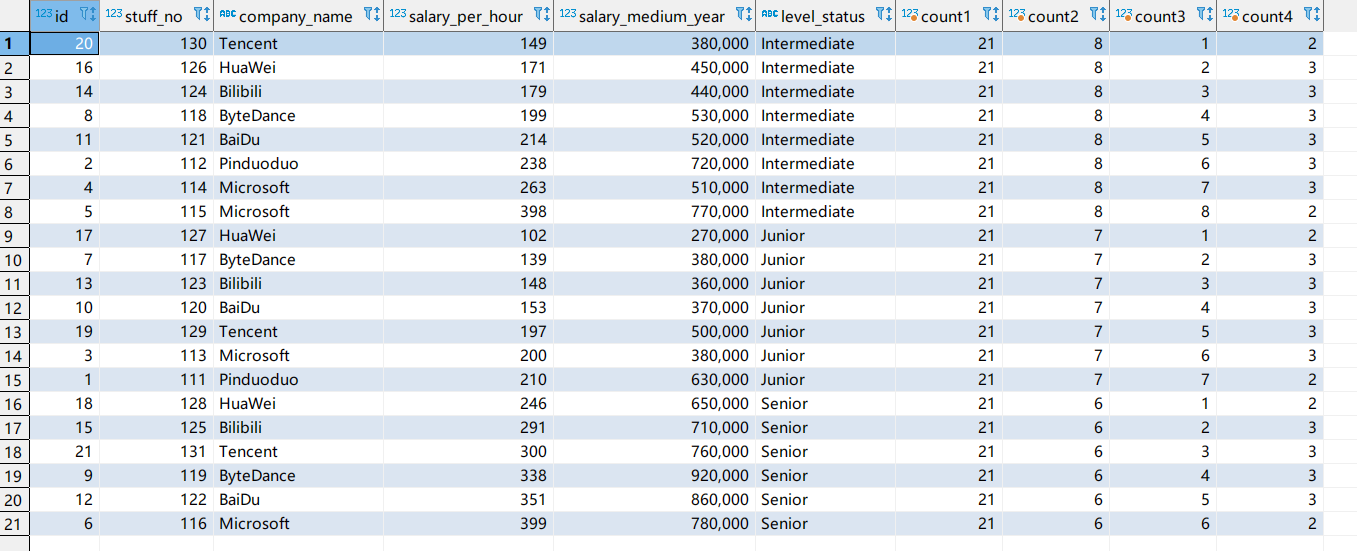
对于sum、avg、min、max等聚合函数也是如此。
这里再演示一下max()开窗函数:
1 | select *, |
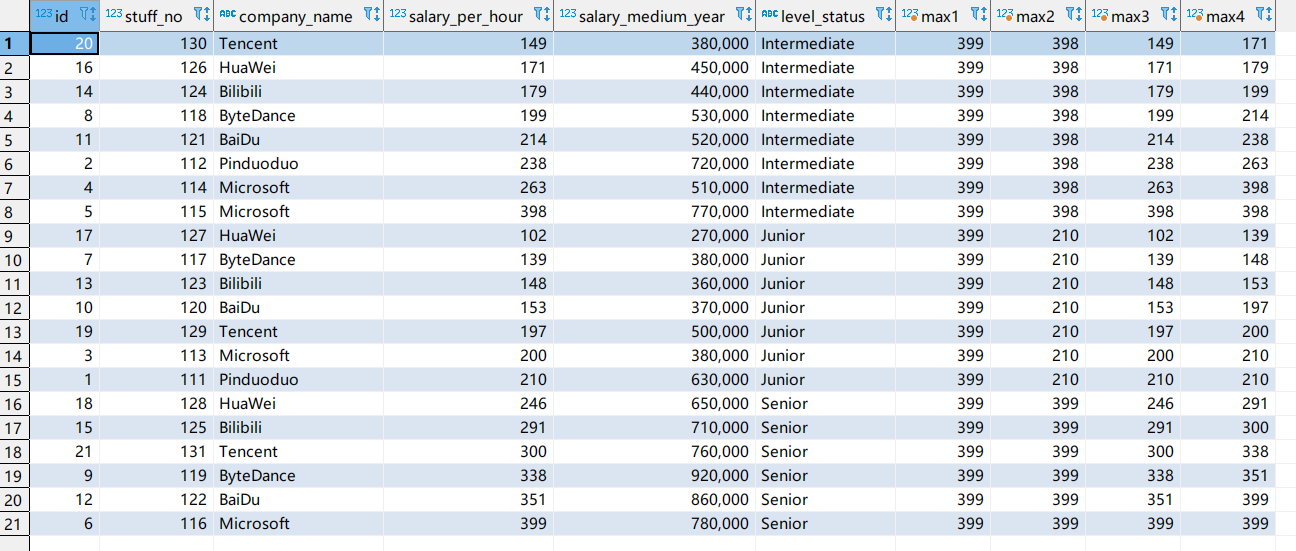
其他聚合开窗函数总结
- first_value(): 返回分区中的第一个值
- last_value(): 返回分区中的最后一个值
- lag(col, n, default): 用于统计统计窗口内col列往上第n行的值,如果为NULL则采用设置的默认值default
- lead(col, n, default): 与上面的开窗口函数作用相似但顺序相反,它是往下取col第n行的值;
- cume_dist开窗函数: 计算某个窗口或分区中某个值的累计分布。假定升序排列,则用一下公式确定累计分布:
- 小于当前值x的行数 / 窗口或partition分区内的总行数;其中x为order by子句中指定的列的当前行中的值
排序开窗函数
rank开窗函数
该开窗函数基于over子句中的order by确定一组中一个值的排名。如果存在partition by。则为每个分区组中的每个值排名。排名是非连续的,如果两个相邻行的值相同,则在前面的行的排名相同为n,则下一行的排名为n+2。
注意:
rank()排序函数必须和over子句中的order by配合使用,
rank()排序函数的over子句里不能有
rows between 1 preceding and 1 following,使用会报错:
1 | Expecting left window frame boundary for function rank() org.apache.hadoop.hive.ql.parse.WindowingSpec$WindowSpec@254080e1 as rank_window_2 to be unbounded. Found : 1 |
1 | select *, |
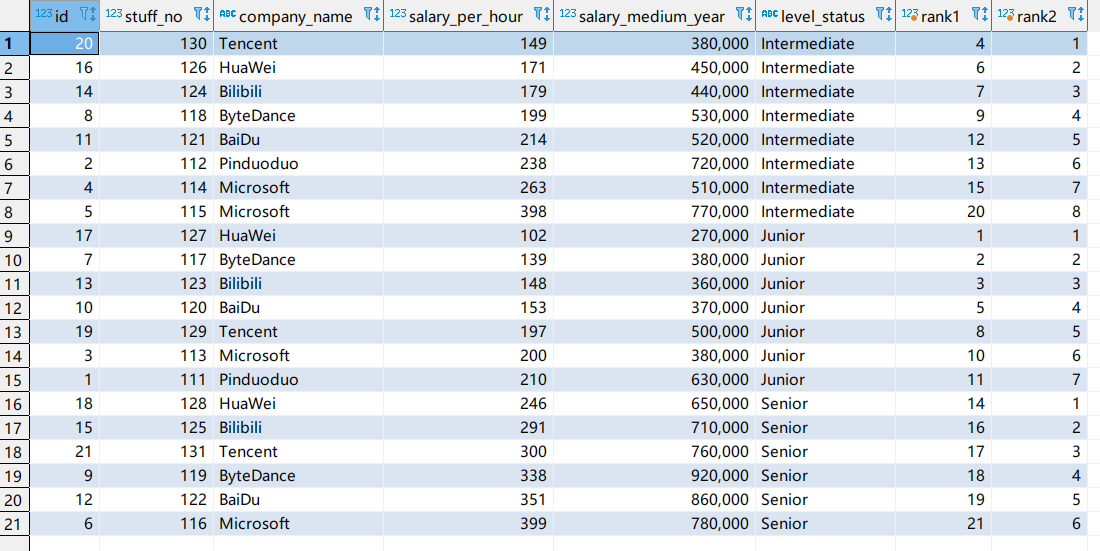
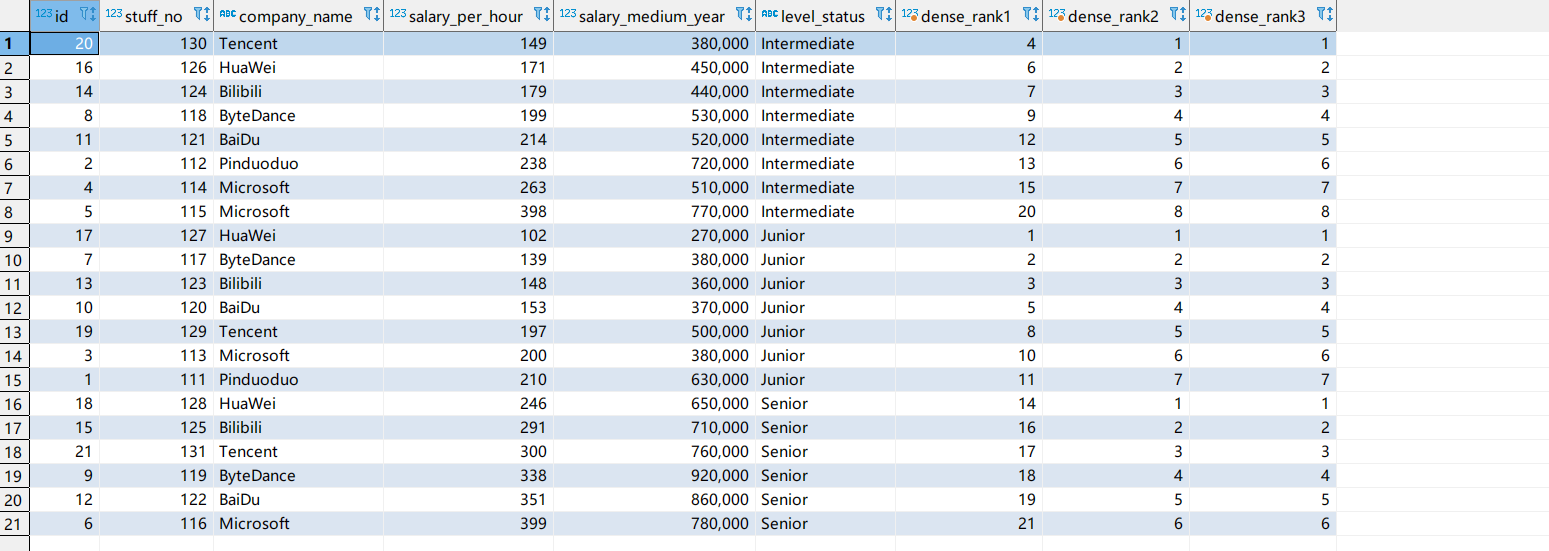
dense_rank()开窗函数
区别与rank()的一点在于,当前面两行的值一致,排名相同,则下一行的排名为n+1。
1 | select *, |
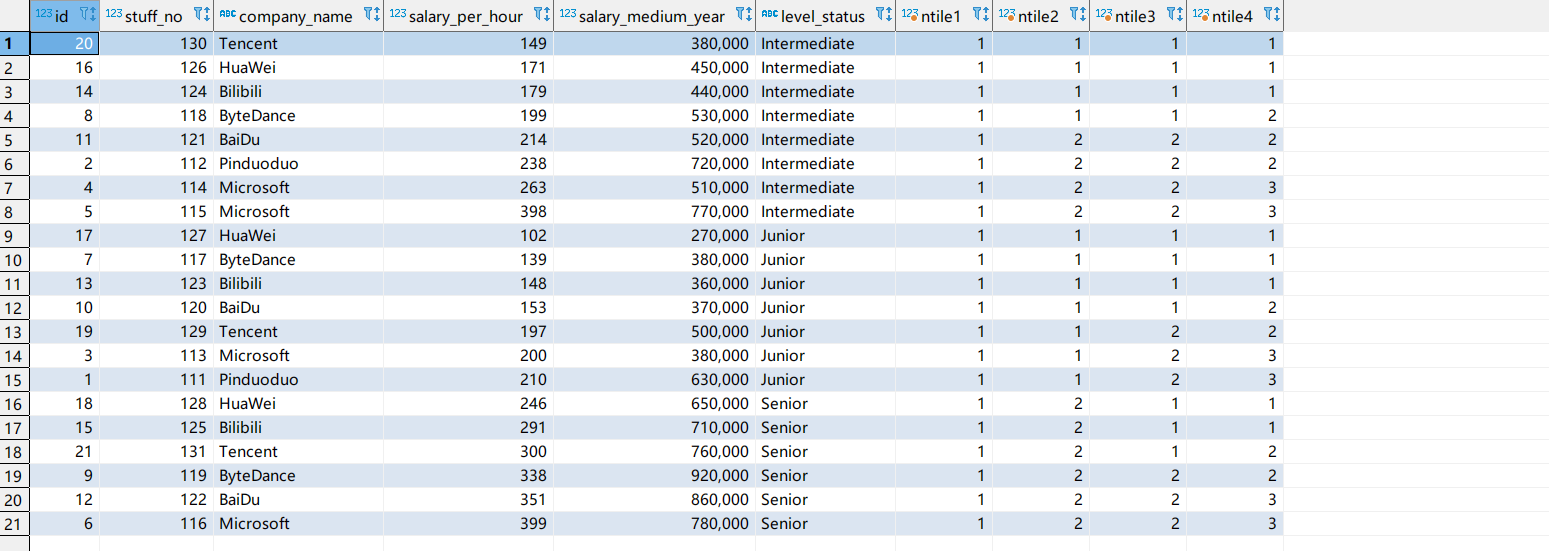
ntile开窗函数
ntile(n)开窗函数将分区中已排序的行划分为大小尽可能相等的指定数量排名的组,并返回给定行所在的组的排名。
1 | select *, |
1 | ntile1: |
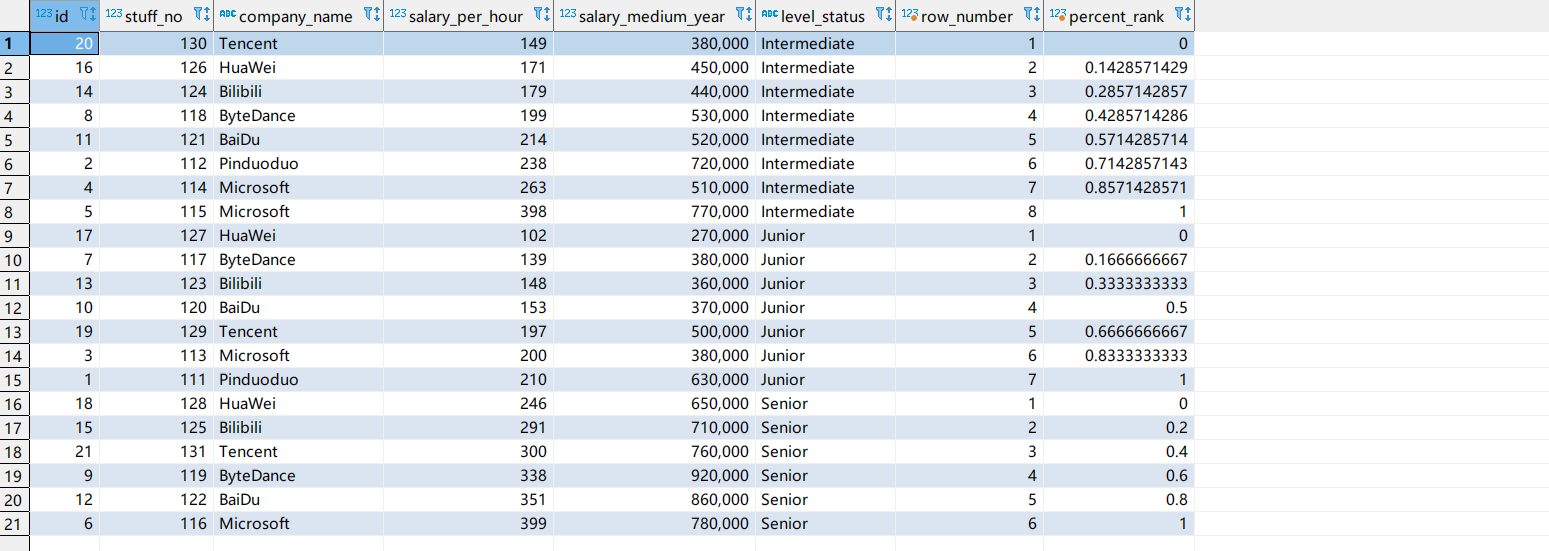
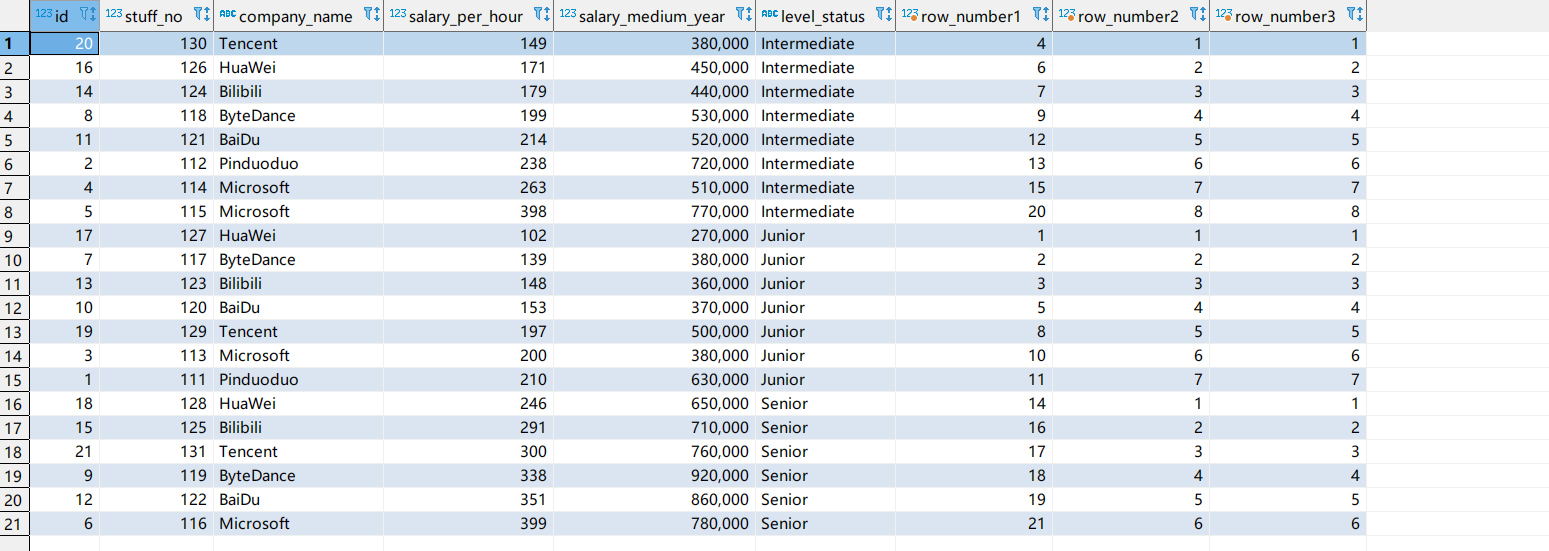
row_number开窗函数
从1开始对分区的数据进行排序,区别于前面的rank和dense_rank函数,排名是连续的,不存在相同或跳跃性的排名。
1 | select *, |
percent_rabk()开窗函数
计算给定行的百分比排名,可以用来计算超过了百分之多少的人,案例为360开机小组手。
计算公式:(当前行rank值-1) / (分组内的总行数 - 1)
1 | select *, |